 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Graph Autoencoder for Manipulation Action Recognition and Prediction
Oct 25, 2021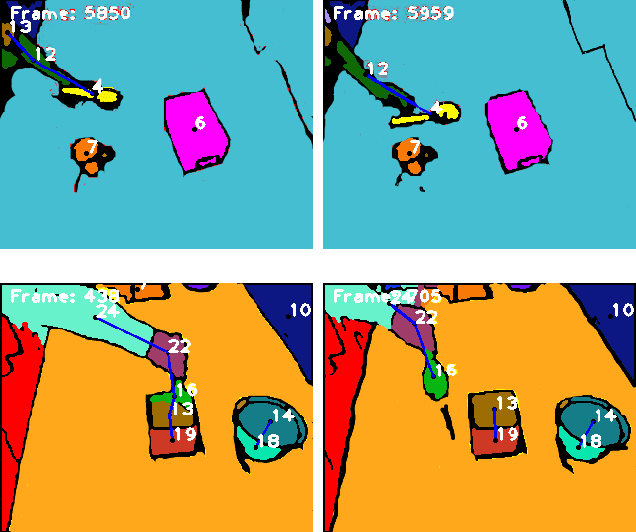
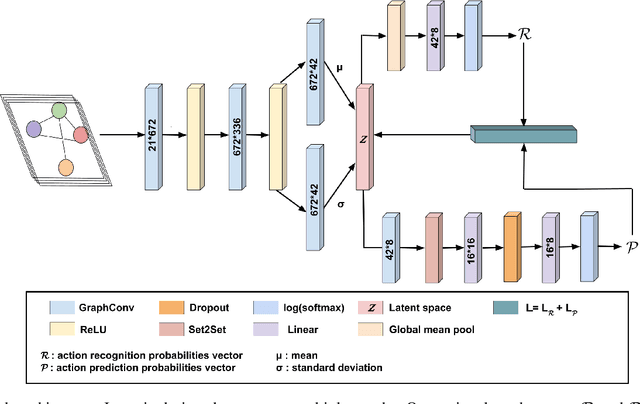

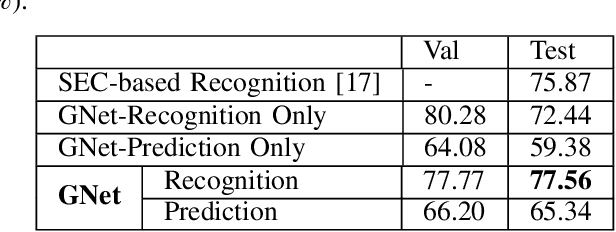
Despite decades of research, understanding human manipulation activities is, and has always been, one of the most attractive and challenging research topics in computer vision and robotics. Recognition and prediction of observed human manipulation actions have their roots in the applications related to, for instance, human-robot interaction and robot learning from demonstration. The current research trend heavily relies on advanced convolutional neural networks to process the structured Euclidean data, such as RGB camera images. These networks, however, come with immense computational complexity to be able to process high dimensional raw data. Different from the related works, we here introduce a deep graph autoencoder to jointly learn recognition and prediction of manipulation tasks from symbolic scene graphs, instead of relying on the structured Euclidean data. Our network has a variational autoencoder structure with two branches: one for identifying the input graph type and one for predicting the future graphs. The input of the proposed network is a set of semantic graphs which store the spatial relations between subjects and objects in the scene. The network output is a label set representing the detected and predicted class types. We benchmark our new model against different state-of-the-art methods on two different datasets, MANIAC and MSRC-9, and show that our proposed model can achieve better performance. We also release our source code https://github.com/gamzeakyol/GNet.