 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRC-WeatherNet: LiDAR, RADAR, and Camera Fusion Network for Real-time Weather-type Classification in Autonomous Driving
Mar 23, 2026Autonomous vehicles face major perception and navigation challenges in adverse weather such as rain, fog, and snow, which degrade the performance of LiDAR, RADAR, and RGB camera sensors. While each sensor type offers unique strengths, such as RADAR robustness in poor visibility and LiDAR precision in clear conditions, they also suffer distinct limitations when exposed to environmental obstructions. This study proposes LRC-WeatherNet, a novel multi-sensor fusion framework that integrates LiDAR, RADAR, and camera data for real-time classification of weather conditions. By employing both early fusion using a unified Bird's Eye View representation and mid-level gated fusion of modality-specific feature maps, our approach adapts to the varying reliability of each sensor under changing weather. Evaluated on the extensive MSU-4S dataset covering nine weather types, LRC-WeatherNet achieves superior classification performance and computational efficiency, significantly outperforming unimodal baselines in adverse conditions. This work is the first to combine all three modalities for robust, real-time weather classification in autonomous driving. We release our trained models and source code in https://github.com/nouralhudaalbashir/LRC-WeatherNet.
REHEARSE-3D: A Multi-modal Emulated Rain Dataset for 3D Point Cloud De-raining
Apr 30, 2025
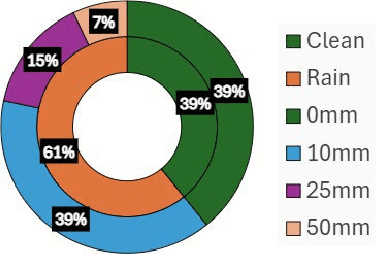
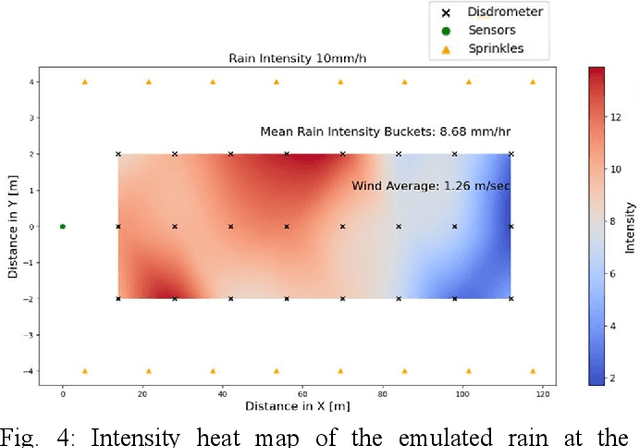
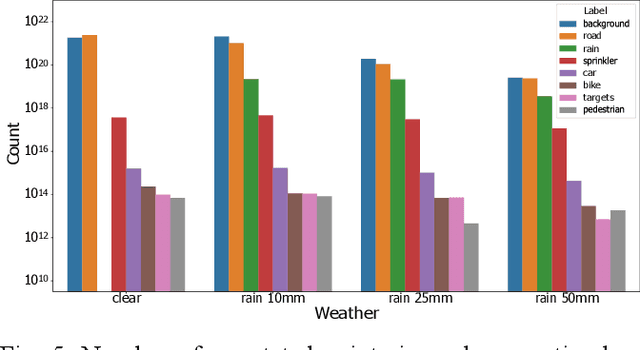
Sensor degradation poses a significant challenge in autonomous driving. During heavy rainfall, the interference from raindrops can adversely affect the quality of LiDAR point clouds, resulting in, for instance, inaccurate point measurements. This, in turn, can potentially lead to safety concerns if autonomous driving systems are not weather-aware, i.e., if they are unable to discern such changes. In this study, we release a new, large-scale, multi-modal emulated rain dataset, REHEARSE-3D, to promote research advancements in 3D point cloud de-raining. Distinct from the most relevant competitors, our dataset is unique in several respects. First, it is the largest point-wise annotated dataset, and second, it is the only one with high-resolution LiDAR data (LiDAR-256) enriched with 4D Radar point clouds logged in both daytime and nighttime conditions in a controlled weather environment. Furthermore, REHEARSE-3D involves rain-characteristic information, which is of significant value not only for sensor noise modeling but also for analyzing the impact of weather at a point level. Leveraging REHEARSE-3D, we benchmark raindrop detection and removal in fused LiDAR and 4D Radar point clouds. Our comprehensive study further evaluates the performance of various statistical and deep-learning models. Upon publication, the dataset and benchmark models will be made publicly available at: https://sporsho.github.io/REHEARSE3D.
Real-Time Manipulation Action Recognition with a Factorized Graph Sequence Encoder
Mar 15, 2025
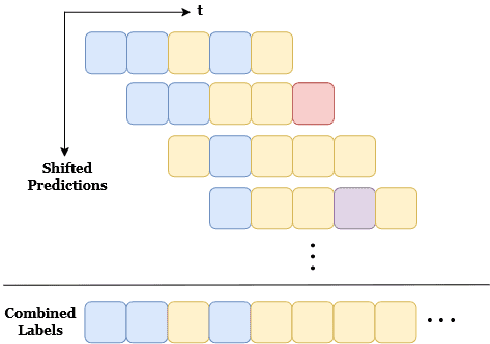
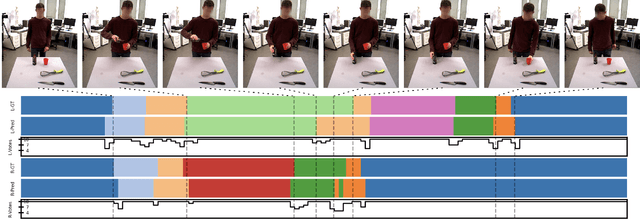

Recognition of human manipulation actions in real-time is essential for safe and effective human-robot interaction and collaboration. The challenge lies in developing a model that is both lightweight enough for real-time execution and capable of generalization. While some existing methods in the literature can run in real-time, they struggle with temporal scalability, i.e., they fail to adapt to long-duration manipulations effectively. To address this, leveraging the generalizable scene graph representations, we propose a new Factorized Graph Sequence Encoder network that not only runs in real-time but also scales effectively in the temporal dimension, thanks to its factorized encoder architecture. Additionally, we introduce Hand Pooling operation, a simple pooling operation for more focused extraction of the graph-level embeddings. Our model outperforms the previous state-of-the-art real-time approach, achieving a 14.3\% and 5.6\% improvement in F1-macro score on the KIT Bimanual Action (Bimacs) Dataset and Collaborative Action (CoAx) Dataset, respectively. Moreover, we conduct an extensive ablation study to validate our network design choices. Finally, we compare our model with its architecturally similar RGB-based model on the Bimacs dataset and show the limitations of this model in contrast to ours on such an object-centric manipulation dataset.
Semantics-aware LiDAR-Only Pseudo Point Cloud Generation for 3D Object Detection
Sep 16, 2023Although LiDAR sensors are crucial for autonomous systems due to providing precise depth information, they struggle with capturing fine object details, especially at a distance, due to sparse and non-uniform data. Recent advances introduced pseudo-LiDAR, i.e., synthetic dense point clouds, using additional modalities such as cameras to enhance 3D object detection. We present a novel LiDAR-only framework that augments raw scans with denser pseudo point clouds by solely relying on LiDAR sensors and scene semantics, omitting the need for cameras. Our framework first utilizes a segmentation model to extract scene semantics from raw point clouds, and then employs a multi-modal domain translator to generate synthetic image segments and depth cues without real cameras. This yields a dense pseudo point cloud enriched with semantic information. We also introduce a new semantically guided projection method, which enhances detection performance by retaining only relevant pseudo points. We applied our framework to different advanced 3D object detection methods and reported up to 2.9% performance upgrade. We also obtained comparable results on the KITTI 3D object detection dataset, in contrast to other state-of-the-art LiDAR-only detectors.
FIVA: Facial Image and Video Anonymization and Anonymization Defense
Sep 08, 2023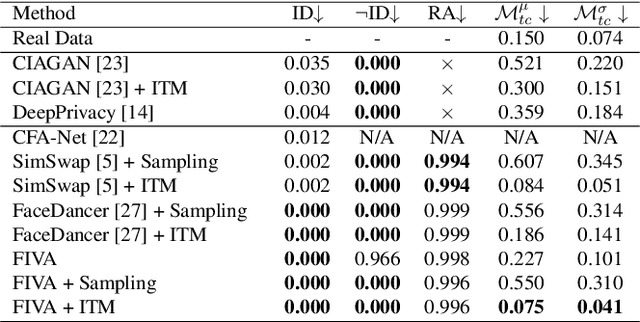
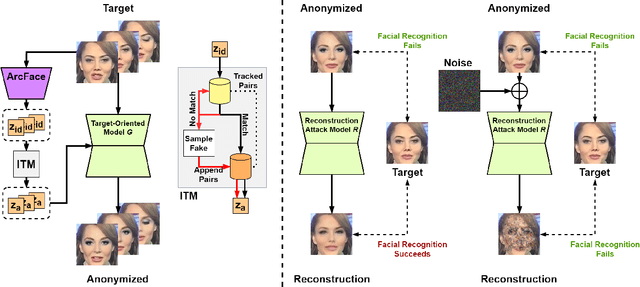
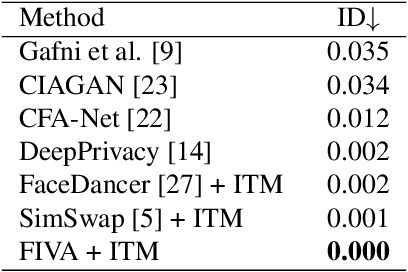
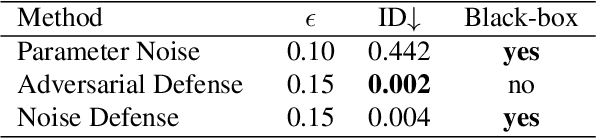
In this paper, we present a new approach for facial anonymization in images and videos, abbreviated as FIVA. Our proposed method is able to maintain the same face anonymization consistently over frames with our suggested identity-tracking and guarantees a strong difference from the original face. FIVA allows for 0 true positives for a false acceptance rate of 0.001. Our work considers the important security issue of reconstruction attacks and investigates adversarial noise, uniform noise, and parameter noise to disrupt reconstruction attacks. In this regard, we apply different defense and protection methods against these privacy threats to demonstrate the scalability of FIVA. On top of this, we also show that reconstruction attack models can be used for detection of deep fakes. Last but not least, we provide experimental results showing how FIVA can even enable face swapping, which is purely trained on a single target image.
Multimodal Detection and Identification of Robot Manipulation Failures
May 08, 2023


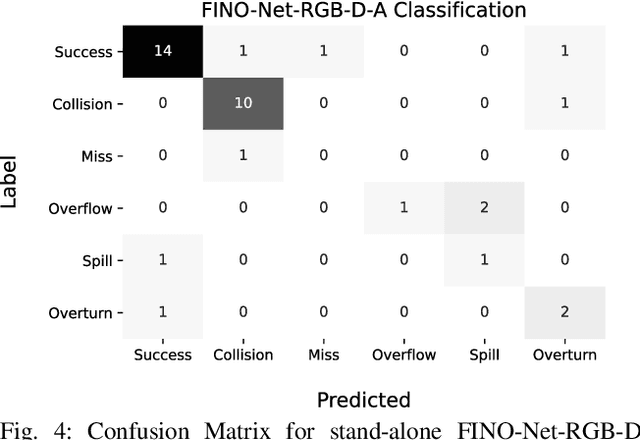
An autonomous service robot should be able to interact with its environment safely and robustly without requiring human assistance. Unstructured environments are challenging for robots since the exact prediction of outcomes is not always possible. Even when the robot behaviors are well-designed, the unpredictable nature of physical robot-object interaction may prevent success in object manipulation. Therefore, execution of a manipulation action may result in an undesirable outcome involving accidents or damages to the objects or environment. Situation awareness becomes important in such cases to enable the robot to (i) maintain the integrity of both itself and the environment, (ii) recover from failed tasks in the short term, and (iii) learn to avoid failures in the long term. For this purpose, robot executions should be continuously monitored, and failures should be detected and classified appropriately. In this work, we focus on detecting and classifying both manipulation and post-manipulation phase failures using the same exteroception setup. We cover a diverse set of failure types for primary tabletop manipulation actions. In order to detect these failures, we propose FINO-Net [1], a deep multimodal sensor fusion based classifier network. Proposed network accurately detects and classifies failures from raw sensory data without any prior knowledge. In this work, we use our extended FAILURE dataset [1] with 99 new multimodal manipulation recordings and annotate them with their corresponding failure types. FINO-Net achieves 0.87 failure detection and 0.80 failure classification F1 scores. Experimental results show that proposed architecture is also appropriate for real-time use.
Learning Failure Prevention Skills for Safe Robot Manipulation
May 04, 2023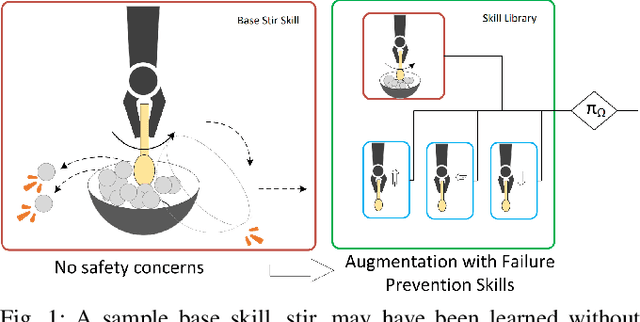


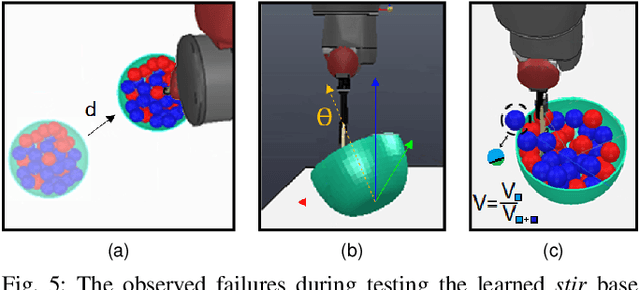
Robots are more capable of achieving manipulation tasks for everyday activities than before. But the safety of manipulation skills that robots employ is still an open problem. Considering all possible failures during skill learning increases the complexity of the process and restrains learning an optimal policy. Beyond that, in unstructured environments, it is not easy to enumerate all possible failures beforehand. In the context of safe skill manipulation, we reformulate skills as base and failure prevention skills where base skills aim at completing tasks and failure prevention skills focus on reducing the risk of failures to occur. Then, we propose a modular and hierarchical method for safe robot manipulation by augmenting base skills by learning failure prevention skills with reinforcement learning, forming a skill library to address different safety risks. Furthermore, a skill selection policy that considers estimated risks is used for the robot to select the best control policy for safe manipulation. Our experiments show that the proposed method achieves the given goal while ensuring safety by preventing failures. We also show that with the proposed method, skill learning is feasible, novel failures are easily adaptable, and our safe manipulation tools can be transferred to the real environment.
Depth- and Semantics-aware Multi-modal Domain Translation: Generating 3D Panoramic Color Images from LiDAR Point Clouds
Feb 15, 2023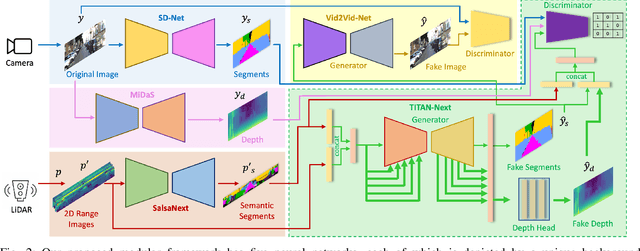



This work presents a new depth- and semantics-aware conditional generative model, named TITAN-Next, for cross-domain image-to-image translation in a multi-modal setup between LiDAR and camera sensors. The proposed model leverages scene semantics as a mid-level representation and is able to translate raw LiDAR point clouds to RGB-D camera images by solely relying on semantic scene segments. We claim that this is the first framework of its kind and it has practical applications in autonomous vehicles such as providing a fail-safe mechanism and augmenting available data in the target image domain. The proposed model is evaluated on the large-scale and challenging Semantic-KITTI dataset, and experimental findings show that it considerably outperforms the original TITAN-Net and other strong baselines by 23.7$\%$ margin in terms of IoU.
FaceDancer: Pose- and Occlusion-Aware High Fidelity Face Swapping
Oct 19, 2022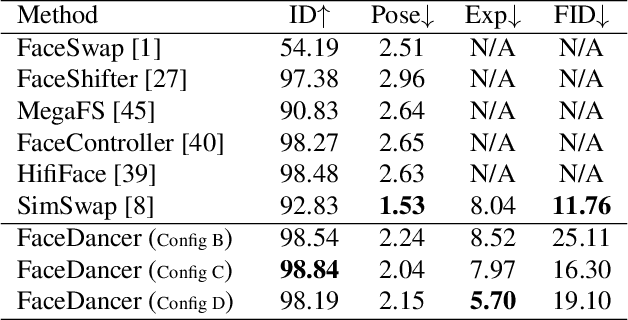
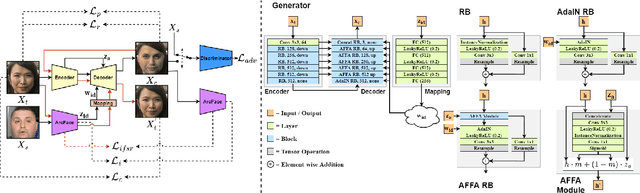


In this work, we present a new single-stage method for subject agnostic face swapping and identity transfer, named FaceDancer. We have two major contributions: Adaptive Feature Fusion Attention (AFFA) and Interpreted Feature Similarity Regularization (IFSR). The AFFA module is embedded in the decoder and adaptively learns to fuse attribute features and features conditioned on identity information without requiring any additional facial segmentation process. In IFSR, we leverage the intermediate features in an identity encoder to preserve important attributes such as head pose, facial expression, lighting, and occlusion in the target face, while still transferring the identity of the source face with high fidelity. We conduct extensive quantitative and qualitative experiments on various datasets and show that the proposed FaceDancer outperforms other state-of-the-art networks in terms of identityn transfer, while having significantly better pose preservation than most of the previous methods.
Semantic State Estimation in Cloth Manipulation Tasks
Mar 22, 2022

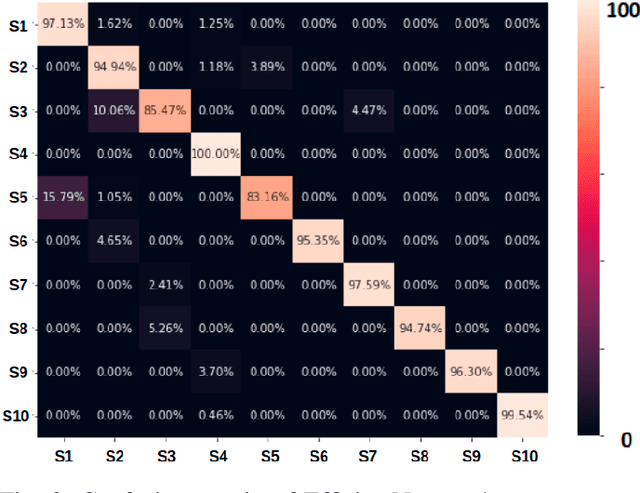
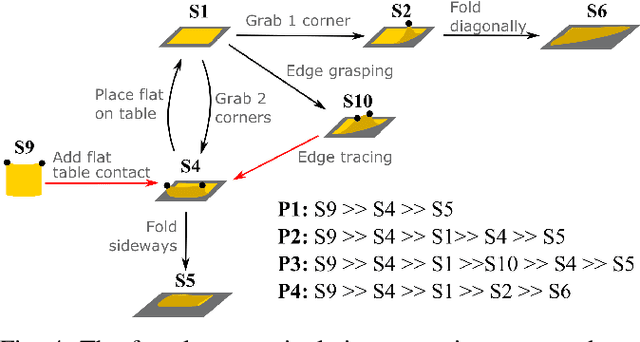
Understanding of deformable object manipulations such as textiles is a challenge due to the complexity and high dimensionality of the problem. Particularly, the lack of a generic representation of semantic states (e.g., \textit{crumpled}, \textit{diagonally folded}) during a continuous manipulation process introduces an obstacle to identify the manipulation type. In this paper, we aim to solve the problem of semantic state estimation in cloth manipulation tasks. For this purpose, we introduce a new large-scale fully-annotated RGB image dataset showing various human demonstrations of different complicated cloth manipulations. We provide a set of baseline deep networks and benchmark them on the problem of semantic state estimation using our proposed dataset. Furthermore, we investigate the scalability of our semantic state estimation framework in robot monitoring tasks of long and complex cloth manipulations.