 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-aware LiDAR-Only Pseudo Point Cloud Generation for 3D Object Detection
Sep 16, 2023Although LiDAR sensors are crucial for autonomous systems due to providing precise depth information, they struggle with capturing fine object details, especially at a distance, due to sparse and non-uniform data. Recent advances introduced pseudo-LiDAR, i.e., synthetic dense point clouds, using additional modalities such as cameras to enhance 3D object detection. We present a novel LiDAR-only framework that augments raw scans with denser pseudo point clouds by solely relying on LiDAR sensors and scene semantics, omitting the need for cameras. Our framework first utilizes a segmentation model to extract scene semantics from raw point clouds, and then employs a multi-modal domain translator to generate synthetic image segments and depth cues without real cameras. This yields a dense pseudo point cloud enriched with semantic information. We also introduce a new semantically guided projection method, which enhances detection performance by retaining only relevant pseudo points. We applied our framework to different advanced 3D object detection methods and reported up to 2.9% performance upgrade. We also obtained comparable results on the KITTI 3D object detection dataset, in contrast to other state-of-the-art LiDAR-only detectors.
Depth- and Semantics-aware Multi-modal Domain Translation: Generating 3D Panoramic Color Images from LiDAR Point Clouds
Feb 15, 2023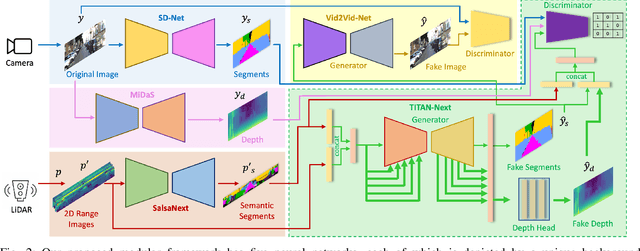



This work presents a new depth- and semantics-aware conditional generative model, named TITAN-Next, for cross-domain image-to-image translation in a multi-modal setup between LiDAR and camera sensors. The proposed model leverages scene semantics as a mid-level representation and is able to translate raw LiDAR point clouds to RGB-D camera images by solely relying on semantic scene segments. We claim that this is the first framework of its kind and it has practical applications in autonomous vehicles such as providing a fail-safe mechanism and augmenting available data in the target image domain. The proposed model is evaluated on the large-scale and challenging Semantic-KITTI dataset, and experimental findings show that it considerably outperforms the original TITAN-Net and other strong baselines by 23.7$\%$ margin in terms of IoU.
Semantics-aware Multi-modal Domain Translation:From LiDAR Point Clouds to Panoramic Color Images
Jun 26, 2021
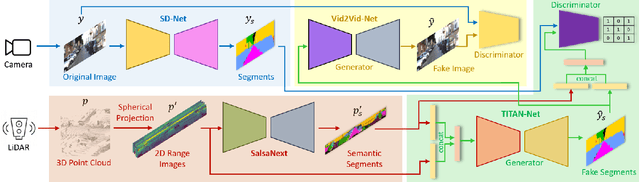


In this work, we present a simple yet effective framework to address the domain translation problem between different sensor modalities with unique data formats. By relying only on the semantics of the scene, our modular generative framework can, for the first time, synthesize a panoramic color image from a given full 3D LiDAR point cloud. The framework starts with semantic segmentation of the point cloud, which is initially projected onto a spherical surface. The same semantic segmentation is applied to the corresponding camera image. Next, our new conditional generative model adversarially learns to translate the predicted LiDAR segment maps to the camera image counterparts. Finally, generated image segments are processed to render the panoramic scene images. We provide a thorough quantitative evaluation on the SemanticKitti dataset and show that our proposed framework outperforms other strong baseline models. Our source code is available at https://github.com/halmstad-University/TITAN-NET
SalsaNext: Fast Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving
Mar 07, 2020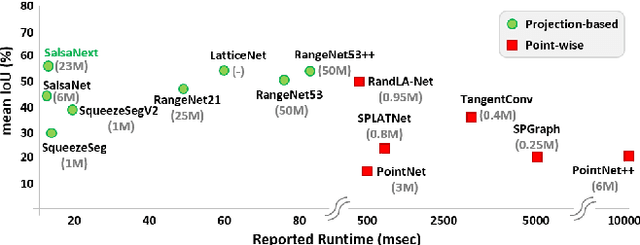



In this paper, we introduce SalsaNext for the semantic segmentation of a full 3D LiDAR point cloud in real-time. SalsaNext is the next version of SalsaNet [1] which has an encoder-decoder architecture where the encoder unit has a set of ResNet blocks and the decoder part combines upsampled features from the residual blocks. In contrast to SalsaNet, we have an additional layer in the encoder and decoder, introduce the context module, switch from stride convolution to average pooling and also apply central dropout treatment. To directly optimize the Jaccard index, we further combine the weighted cross-entropy loss with Lovasz-Softmax loss [2]. We provide a thorough quantitative evaluation on the Semantic-KITTI dataset [3], which demonstrates that the proposed SalsaNext outperforms other state-of-the-art semantic segmentation networks in terms of accuracy and computation time. We also release our source code https://github.com/TiagoCortinhal/SalsaNext.