 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-aware Multi-modal Domain Translation:From LiDAR Point Clouds to Panoramic Color Images
Paper and Code

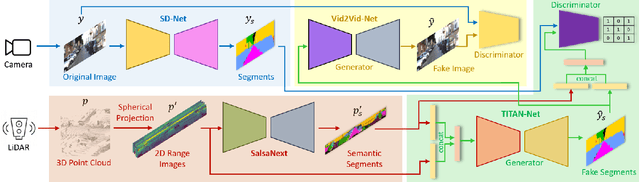


In this work, we present a simple yet effective framework to address the domain translation problem between different sensor modalities with unique data formats. By relying only on the semantics of the scene, our modular generative framework can, for the first time, synthesize a panoramic color image from a given full 3D LiDAR point cloud. The framework starts with semantic segmentation of the point cloud, which is initially projected onto a spherical surface. The same semantic segmentation is applied to the corresponding camera image. Next, our new conditional generative model adversarially learns to translate the predicted LiDAR segment maps to the camera image counterparts. Finally, generated image segments are processed to render the panoramic scene images. We provide a thorough quantitative evaluation on the SemanticKitti dataset and show that our proposed framework outperforms other strong baseline models. Our source code is available at https://github.com/halmstad-University/TITAN-NET