 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIVA: Facial Image and Video Anonymization and Anonymization Defense
Sep 08, 2023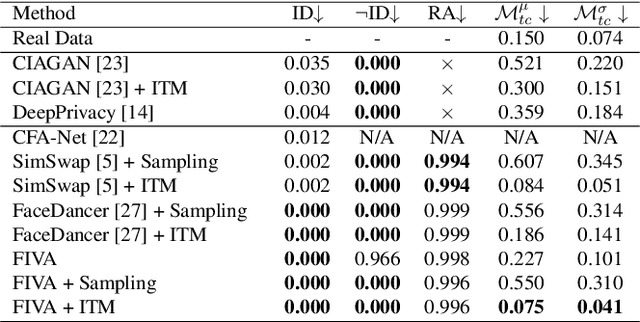
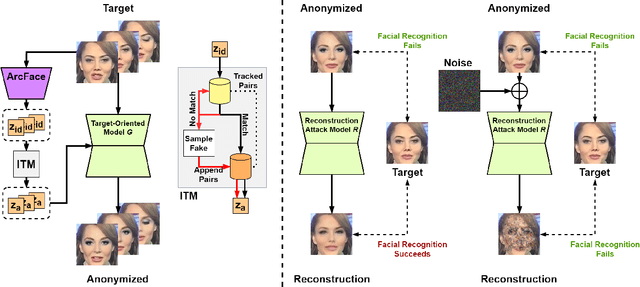
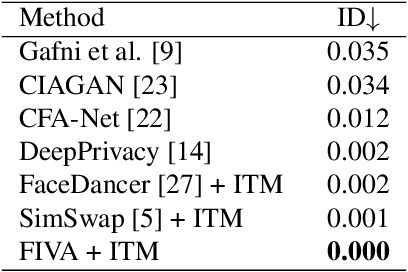
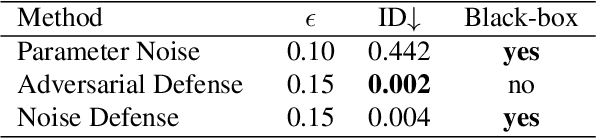
In this paper, we present a new approach for facial anonymization in images and videos, abbreviated as FIVA. Our proposed method is able to maintain the same face anonymization consistently over frames with our suggested identity-tracking and guarantees a strong difference from the original face. FIVA allows for 0 true positives for a false acceptance rate of 0.001. Our work considers the important security issue of reconstruction attacks and investigates adversarial noise, uniform noise, and parameter noise to disrupt reconstruction attacks. In this regard, we apply different defense and protection methods against these privacy threats to demonstrate the scalability of FIVA. On top of this, we also show that reconstruction attack models can be used for detection of deep fakes. Last but not least, we provide experimental results showing how FIVA can even enable face swapping, which is purely trained on a single target image.
FaceDancer: Pose- and Occlusion-Aware High Fidelity Face Swapping
Oct 19, 2022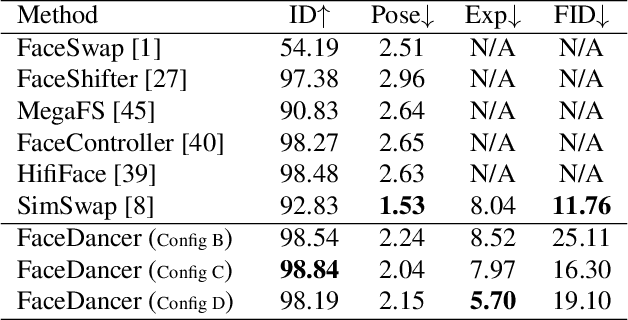
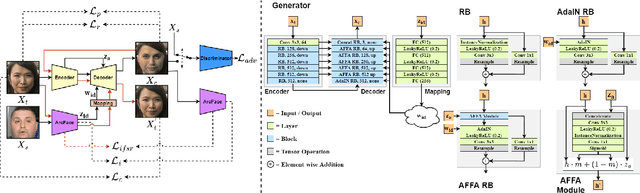


In this work, we present a new single-stage method for subject agnostic face swapping and identity transfer, named FaceDancer. We have two major contributions: Adaptive Feature Fusion Attention (AFFA) and Interpreted Feature Similarity Regularization (IFSR). The AFFA module is embedded in the decoder and adaptively learns to fuse attribute features and features conditioned on identity information without requiring any additional facial segmentation process. In IFSR, we leverage the intermediate features in an identity encoder to preserve important attributes such as head pose, facial expression, lighting, and occlusion in the target face, while still transferring the identity of the source face with high fidelity. We conduct extensive quantitative and qualitative experiments on various datasets and show that the proposed FaceDancer outperforms other state-of-the-art networks in terms of identityn transfer, while having significantly better pose preservation than most of the previous methods.