Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Rectified Power Unit Networks Fail and How to Improve It: An Effective Theory Perspective
Paper and Code
Aug 04, 2024
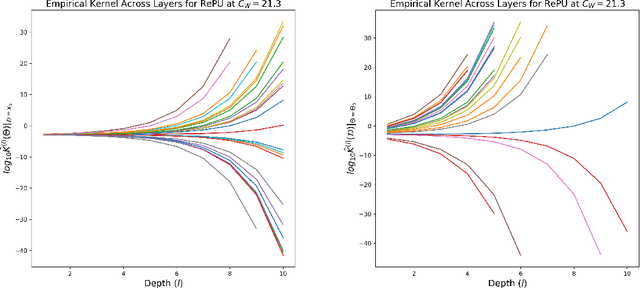
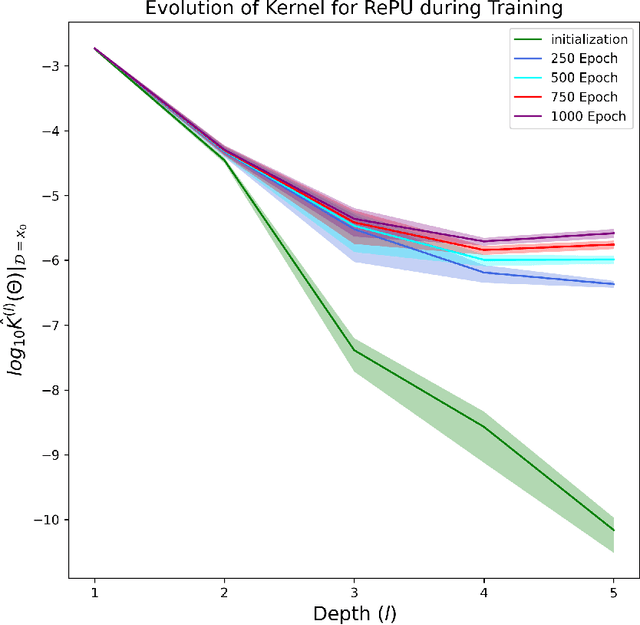
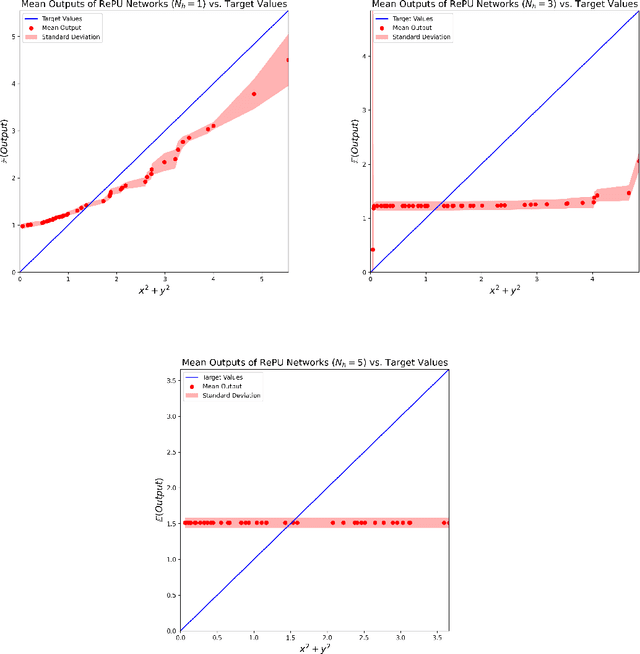
The Rectified Power Unit (RePU) activation functions, unlike the Rectified Linear Unit (ReLU), have the advantage of being a differentiable function when constructing neural networks. However, it can be experimentally observed when deep layers are stacked, neural networks constructed with RePU encounter critical issues. These issues include the values exploding or vanishing and failure of training. And these happen regardless of the hyperparameter initialization. From the perspective of effective theory, we aim to identify the causes of this phenomenon and propose a new activation function that retains the advantages of RePU while overcoming its drawbacks.
* 25 pages, 8 figures
View paper on