 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExComm: Exploration-Stage Communication for Error-Resilient Agentic Test-Time Scaling
May 21, 2026A common failure mode in long-horizon agentic test-time scaling is error propagation, where factual errors or invalid deductions introduced at intermediate steps persist in the agent's belief state and contaminate later reasoning. Existing test-time scaling methods provide limited control over this process, as they often rely on agents to detect their own mistakes, select among flawed trajectories, or refine solutions only after errors have already shaped the reasoning path. We propose ExComm, a communication protocol for exploration-stage agentic test-time scaling. ExComm is motivated by the empirical observation that the majority of intermediate errors in parallel agentic reasoning produce detectable cross-agent factual conflicts. Leveraging the iterative structure of agentic workflows, ExComm periodically audits agent belief states to detect such conflicts, resolves them through a dedicated tool-based verification loop, and returns concise, targeted feedback to the involved agents. Corrections are incorporated through soft belief updates, which append verified feedback rather than overwriting existing beliefs. Furthermore, to prevent collapsing trajectory diversity due to communication, ExComm further introduces a trajectory diversification module that redirects redundant trajectories toward orthogonal strategies. Experiments on AIME 2024, AIME 2025, and GAIA with Gemini-2.5-Flash-Lite and Qwen3.5-4B show that ExComm consistently outperforms strong test-time scaling baselines, achieving average performance gains of 5.7% and 5.0% over the best-performing baselines, respectively. Further analyses demonstrate improved error recovery, favorable scaling behavior, stronger diversity than adapted communication baselines, and the best performance-cost trade-off among the evaluated methods.
IdleSpec: Exploiting Idle Time via Speculative Planning for LLM Agents
May 21, 2026Large language model (LLM)-based agents solve complex tasks by leveraging multi-step reasoning with iterative tool calls and environment interactions, which incur idle time while waiting for observations. Despite the prevalence of idle time in most agentic scenarios, existing works treat it as an unavoidable overhead or propose restricted solutions that overlook varying computational budgets across different tool calls and future observation uncertainty, thereby leading to suboptimal utilization of idle time. In this paper, we introduce IdleSpec, a scalable and generic inference approach that leverages idle-time computation to improve agent performance while minimizing latency overhead. Specifically, IdleSpec iteratively generates plan candidates during idle periods and, once observations become available, aggregates them to guide the next reasoning step. For effective plan generation under observation uncertainty, IdleSpec samples between complementary drafting strategies (i.e., progressive and recovery) from a learned distribution that is updated via posterior feedback. Our experiments demonstrate that IdleSpec significantly improves agent performance in various agentic scenarios by effectively utilizing idle time. In particular, on the GAIA and FRAMES, IdleSpec achieves 55.6% average accuracy with Gemini-2.5-Flash, surpassing the vanilla baseline without idle-time usage by 5.1%. Furthermore, for MLE-Bench, which involves substantial delay from code executions, IdleSpec achieves performance gains of up to 9.1% on the Any Medal rate, highlighting its generalizability to long-horizon tasks.
RLDX-1 Technical Report
May 05, 2026While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
HAMLET: Switch your Vision-Language-Action Model into a History-Aware Policy
Oct 02, 2025Inherently, robotic manipulation tasks are history-dependent: leveraging past context could be beneficial. However, most existing Vision-Language-Action models (VLAs) have been designed without considering this aspect, i.e., they rely solely on the current observation, ignoring preceding context. In this paper, we propose HAMLET, a scalable framework to adapt VLAs to attend to the historical context during action prediction. Specifically, we introduce moment tokens that compactly encode perceptual information at each timestep. Their representations are initialized with time-contrastive learning, allowing them to better capture temporally distinctive aspects. Next, we employ a lightweight memory module that integrates the moment tokens across past timesteps into memory features, which are then leveraged for action prediction. Through empirical evaluation, we show that HAMLET successfully transforms a state-of-the-art VLA into a history-aware policy, especially demonstrating significant improvements on long-horizon tasks that require historical context. In particular, on top of GR00T N1.5, HAMLET achieves an average success rate of 76.4% on history-dependent real-world tasks, surpassing the baseline performance by 47.2%. Furthermore, HAMLET pushes prior art performance from 64.1% to 66.4% on RoboCasa Kitchen (100-demo setup) and from 95.6% to 97.7% on LIBERO, highlighting its effectiveness even under generic robot-manipulation benchmarks.
Adversarial Robustification via Text-to-Image Diffusion Models
Jul 26, 2024



Adversarial robustness has been conventionally believed as a challenging property to encode for neural networks, requiring plenty of training data. In the recent paradigm of adopting off-the-shelf models, however, access to their training data is often infeasible or not practical, while most of such models are not originally trained concerning adversarial robustness. In this paper, we develop a scalable and model-agnostic solution to achieve adversarial robustness without using any data. Our intuition is to view recent text-to-image diffusion models as "adaptable" denoisers that can be optimized to specify target tasks. Based on this, we propose: (a) to initiate a denoise-and-classify pipeline that offers provable guarantees against adversarial attacks, and (b) to leverage a few synthetic reference images generated from the text-to-image model that enables novel adaptation schemes. Our experiments show that our data-free scheme applied to the pre-trained CLIP could improve the (provable) adversarial robustness of its diverse zero-shot classification derivatives (while maintaining their accuracy), significantly surpassing prior approaches that utilize the full training data. Not only for CLIP, we also demonstrate that our framework is easily applicable for robustifying other visual classifiers efficiently.
Modality-Agnostic Self-Supervised Learning with Meta-Learned Masked Auto-Encoder
Oct 25, 2023Despite its practical importance across a wide range of modalities, recent advances in self-supervised learning (SSL) have been primarily focused on a few well-curated domains, e.g., vision and language, often relying on their domain-specific knowledge. For example, Masked Auto-Encoder (MAE) has become one of the popular architectures in these domains, but less has explored its potential in other modalities. In this paper, we develop MAE as a unified, modality-agnostic SSL framework. In turn, we argue meta-learning as a key to interpreting MAE as a modality-agnostic learner, and propose enhancements to MAE from the motivation to jointly improve its SSL across diverse modalities, coined MetaMAE as a result. Our key idea is to view the mask reconstruction of MAE as a meta-learning task: masked tokens are predicted by adapting the Transformer meta-learner through the amortization of unmasked tokens. Based on this novel interpretation, we propose to integrate two advanced meta-learning techniques. First, we adapt the amortized latent of the Transformer encoder using gradient-based meta-learning to enhance the reconstruction. Then, we maximize the alignment between amortized and adapted latents through task contrastive learning which guides the Transformer encoder to better encode the task-specific knowledge. Our experiment demonstrates the superiority of MetaMAE in the modality-agnostic SSL benchmark (called DABS), significantly outperforming prior baselines. Code is available at https://github.com/alinlab/MetaMAE.
3D GAN Inversion with Pose Optimization
Oct 17, 2022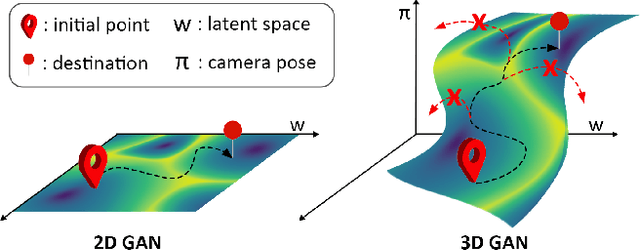


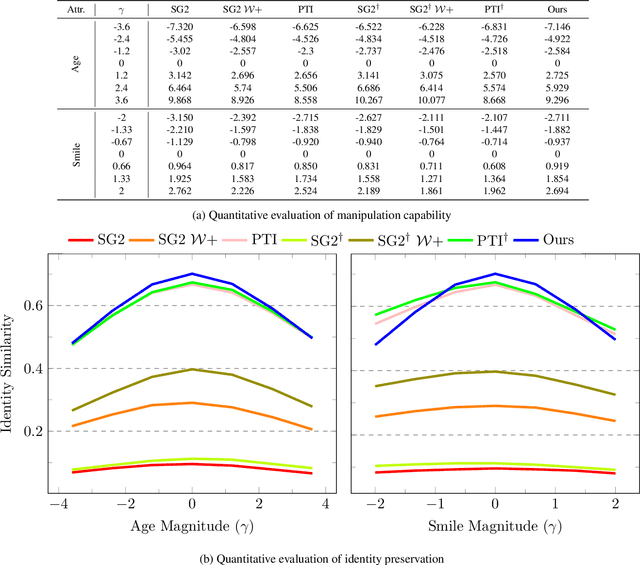
With the recent advances in NeRF-based 3D aware GANs quality, projecting an image into the latent space of these 3D-aware GANs has a natural advantage over 2D GAN inversion: not only does it allow multi-view consistent editing of the projected image, but it also enables 3D reconstruction and novel view synthesis when given only a single image. However, the explicit viewpoint control acts as a main hindrance in the 3D GAN inversion process, as both camera pose and latent code have to be optimized simultaneously to reconstruct the given image. Most works that explore the latent space of the 3D-aware GANs rely on ground-truth camera viewpoint or deformable 3D model, thus limiting their applicability. In this work, we introduce a generalizable 3D GAN inversion method that infers camera viewpoint and latent code simultaneously to enable multi-view consistent semantic image editing. The key to our approach is to leverage pre-trained estimators for better initialization and utilize the pixel-wise depth calculated from NeRF parameters to better reconstruct the given image. We conduct extensive experiments on image reconstruction and editing both quantitatively and qualitatively, and further compare our results with 2D GAN-based editing to demonstrate the advantages of utilizing the latent space of 3D GANs. Additional results and visualizations are available at https://3dgan-inversion.github.io .
AE-NeRF: Auto-Encoding Neural Radiance Fields for 3D-Aware Object Manipulation
Apr 28, 2022
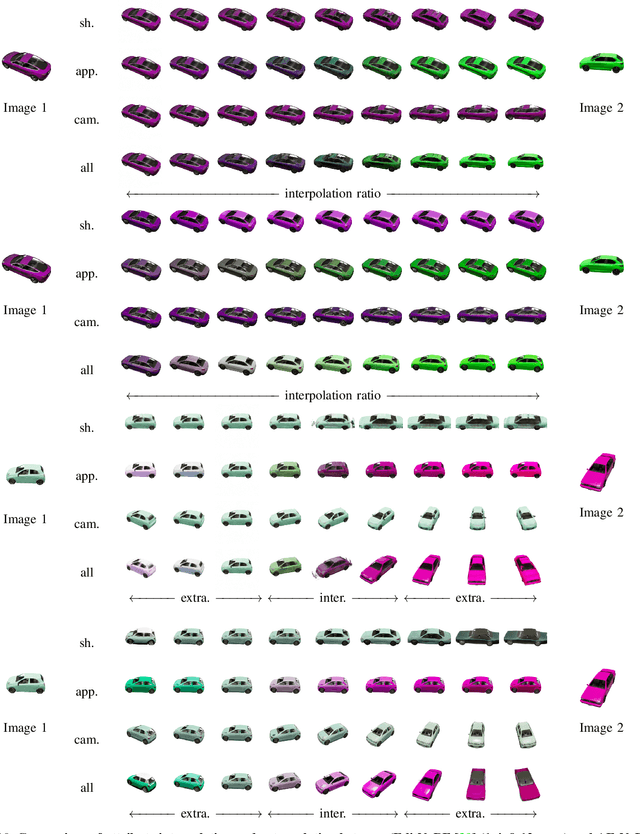


We propose a novel framework for 3D-aware object manipulation, called Auto-Encoding Neural Radiance Fields (AE-NeRF). Our model, which is formulated in an auto-encoder architecture, extracts disentangled 3D attributes such as 3D shape, appearance, and camera pose from an image, and a high-quality image is rendered from the attributes through disentangled generative Neural Radiance Fields (NeRF). To improve the disentanglement ability, we present two losses, global-local attribute consistency loss defined between input and output, and swapped-attribute classification loss. Since training such auto-encoding networks from scratch without ground-truth shape and appearance information is non-trivial, we present a stage-wise training scheme, which dramatically helps to boost the performance. We conduct experiments to demonstrate the effectiveness of the proposed model over the latest methods and provide extensive ablation studies.