 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Delta: Beyond Key-Value Associative State Evolution
Jun 07, 2026Linear attention reformulates sequence modeling as recurrent state evolution, enabling efficient linear-time inference. Under the key-value associative paradigm, existing approaches restrict the role of the query to the readout operation, decoupling it from state evolution. We show that query-conditioned state readout induces a structured value prediction over accumulated memory that complements key-based retrieval. Based on this insight, we propose Q-Delta, a query-aware delta rule that integrates mixed key-query prediction errors into state evolution, enabling jointly corrective dynamics while preserving delta-rule efficiency. We establish stability guarantees for the resulting dynamics and derive a hardware-efficient chunkwise-parallel formulation with a custom Triton implementation. Empirical results demonstrate stable optimization, competitive throughput, and consistent improvements over strong baselines on language modeling and long-context retrieval tasks.
STAR: Rethinking MoE Routing as Structure-Aware Subspace Learning
Jun 07, 2026Mixture-of-Experts (MoE) scales model capacity efficiently by selectively routing inputs to a specialized subset of experts. However, input-expert specialization, the core motivation of MoE, critically depends on whether the router is actually aware of input structure. In practice, MoE routing is typically implemented as a shallow linear projection with limited awareness of input representation, which often leads to unstable routing. We propose STAR, a Structure Aware Routing that rethinks MoE routing as a subspace learning problem by augmenting standard learnable routing with an evolving principal subspace that tracks dominant input structure via Generalized Hebbian Algorithm (GHA). By aligning routing decisions directly with input structure, STAR enables stable expert specialization. We evaluate STAR on controlled synthetic setup and large-scale language and vision tasks, where it consistently improves routing quality and downstream performance over strong MoE baselines. Moreover, optional test-time subspace updates further enhance routing robustness and generalization under input distribution shifts.
RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
Mar 22, 2026Improving embodied reasoning in multimodal-large-language models (MLLMs) is essential for building vision-language-action models (VLAs) on top of them to readily translate multimodal understanding into low-level actions. Accordingly, recent work has explored enhancing embodied reasoning in MLLMs through supervision of vision-question-answering type. However, these approaches have been reported to result in unstable VLA performance, often yielding only marginal or even negative gains. In this paper, we propose a more systematic MLLM training framework RoboAlign that reliably improves VLA performance. Our key idea is to sample action tokens via zero-shot natural language reasoning and refines this reasoning using reinforcement learning (RL) to improve action accuracy. As a result, RoboAlign bridges the modality gap between language and low-level actions in MLLMs, and facilitate knowledge transfer from MLLM to VLA. To validate the effectiveness of RoboAlign, we train VLAs by adding a diffusion-based action head on top of an MLLM backbone and evaluate them on major robotics benchmarks. Remarkably, by performing RL-based alignment after SFT using less than 1\% of the data, RoboAlign achieves performance improvements of 17.5\%, 18.9\%, and 106.6\% over SFT baselines on LIBERO, CALVIN, and real-world environments, respectively.
FluoCLIP: Stain-Aware Focus Quality Assessment in Fluorescence Microscopy
Feb 27, 2026Accurate focus quality assessment (FQA) in fluorescence microscopy remains challenging, as the stain-dependent optical properties of fluorescent dyes cause abrupt and heterogeneous focus shifts. However, existing datasets and models overlook this variability, treating focus quality as a stain-agnostic problem. In this work, we formulate the task of stain-aware FQA, emphasizing that focus behavior in fluorescence microscopy must be modeled as a function of staining characteristics. Through quantitative analysis of existing datasets (FocusPath, BBBC006) and our newly curated FluoMix, we demonstrate that focus-rank relationships vary substantially across stains, underscoring the need for stain-aware modeling in fluorescence microscopy. To support this new formulation, we propose FluoMix, the first dataset for stain-aware FQA that encompasses multiple tissues, fluorescent stains, and focus variations. Building on this dataset, we propose FluoCLIP, a two-stage vision-language framework that leverages CLIP's alignment capability to interpret focus quality in the context of biological staining. In the stain-grounding phase, FluoCLIP learns general stain representations by aligning textual stain tokens with visual features, while in the stain-guided ranking phase, it optimizes stain-specific rank prompts for ordinal focus prediction. Together, our formulation, dataset, and framework establish the first foundation for stain-aware FQA, and FluoCLIP achieves strong generalization across diverse fluorescence microscopy conditions.
How Many Experts Are Enough? Towards Optimal Semantic Specialization for Mixture-of-Experts
Dec 21, 2025Finding the optimal configuration of Sparse Mixture-ofExperts (SMoE) that maximizes semantic differentiation among experts is essential for exploiting the full potential of MoE architectures. However, existing SMoE frameworks either heavily rely on hyperparameter tuning or overlook the importance of diversifying semantic roles across experts when adapting the expert pool size. We propose Mixture-of-Experts for Adaptive Semantic Specialization (MASS), a semanticaware MoE framework for adaptive expert expansion and dynamic routing. MASS introduces two key advancements: (i) a gradient-based semantic drift detector that prompts targeted expert expansion when the existing expert pool lacks capacity to capture the full semantic diversity of the data, and (ii) an integration of adaptive routing strategy that dynamically adjusts expert usage based on token-level routing confidence mass. We first demonstrate that MASS reliably converges to the point of optimal balance between cost-performance trade-off with notably improved sematic specialization in a highly controlled synthetic setup. Further empirical results on real-world datasets across language and vision domains show that MASS consistently outperforms a range of strong MoE baselines, demonstrating its domain robustness and enhanced expert specialization.
Are Graph Transformers Necessary? Efficient Long-Range Message Passing with Fractal Nodes in MPNNs
Nov 17, 2025Graph Neural Networks (GNNs) have emerged as powerful tools for learning on graph-structured data, but often struggle to balance local and global information. While graph Transformers aim to address this by enabling long-range interactions, they often overlook the inherent locality and efficiency of Message Passing Neural Networks (MPNNs). We propose a new concept called fractal nodes, inspired by the fractal structure observed in real-world networks. Our approach is based on the intuition that graph partitioning naturally induces fractal structure, where subgraphs often reflect the connectivity patterns of the full graph. Fractal nodes are designed to coexist with the original nodes and adaptively aggregate subgraph-level feature representations, thereby enforcing feature similarity within each subgraph. We show that fractal nodes alleviate the over-squashing problem by providing direct shortcut connections that enable long-range propagation of subgraph-level representations. Experiment results show that our method improves the expressive power of MPNNs and achieves comparable or better performance to graph Transformers while maintaining the computational efficiency of MPNN by improving the long-range dependencies of MPNN.
Proleptic Temporal Ensemble for Improving the Speed of Robot Tasks Generated by Imitation Learning
Oct 22, 2024
Imitation learning, which enables robots to learn behaviors from demonstrations by non-experts, has emerged as a promising solution for generating robot motions in such environments. The imitation learning based robot motion generation method, however, has the drawback of being limited by the demonstrators task execution speed. This paper presents a novel temporal ensemble approach applied to imitation learning algorithms, allowing for execution of future actions. The proposed method leverages existing demonstration data and pretrained policies, offering the advantages of requiring no additional computation and being easy to implement. The algorithms performance was validated through real world experiments involving robotic block color sorting, demonstrating up to 3x increase in task execution speed while maintaining a high success rate compared to the action chunking with transformer method. This study highlights the potential for significantly improving the performance of imitation learning-based policies, which were previously limited by the demonstrator's speed. It is expected to contribute substantially to future advancements in autonomous object manipulation technologies aimed at enhancing productivity.
LoraMap: Harnessing the Power of LoRA Connections
Aug 29, 2024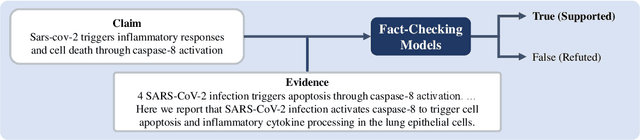



Large Language Models (LLMs) can benefit from mitigating hallucinations through fact-checking and overcoming substantial computational overhead with parameter-efficient techniques such as Low-Rank Adaptation (LoRA). While some studies have explored the parallel integration of multiple LoRAs, these approaches need attention to the connections between them. This paper investigates methods to establish connections among multiple LoRAs. We create three reasoning datasets tailored to fact-checking and fine-tune individual LoRAs, allowing them to view and reason from diverse perspectives. Then, we explore strategies for allocating these reasoning LoRAs and introduce LoraMap, an approach to map connections between them. The results on the fact-checking task demonstrate that the performance of LoraMap is superior to LoraHub, an existing LoRA composition method. LoraMap also outperforms with significantly fewer parameters than LoraConcat, which concatenates LoRAs and further fine-tunes them.
PANDA: Expanded Width-Aware Message Passing Beyond Rewiring
Jun 06, 2024Recent research in the field of graph neural network (GNN) has identified a critical issue known as "over-squashing," resulting from the bottleneck phenomenon in graph structures, which impedes the propagation of long-range information. Prior works have proposed a variety of graph rewiring concepts that aim at optimizing the spatial or spectral properties of graphs to promote the signal propagation. However, such approaches inevitably deteriorate the original graph topology, which may lead to a distortion of information flow. To address this, we introduce an expanded width-aware (PANDA) message passing, a new message passing paradigm where nodes with high centrality, a potential source of over-squashing, are selectively expanded in width to encapsulate the growing influx of signals from distant nodes. Experimental results show that our method outperforms existing rewiring methods, suggesting that selectively expanding the hidden state of nodes can be a compelling alternative to graph rewiring for addressing the over-squashing.
Korean Bio-Medical Corpus for Medical Named Entity Recognition
Mar 24, 2024Named Entity Recognition (NER) plays a pivotal role in medical Natural Language Processing (NLP). Yet, there has not been an open-source medical NER dataset specifically for the Korean language. To address this, we utilized ChatGPT to assist in constructing the KBMC (Korean Bio-Medical Corpus), which we are now presenting to the public. With the KBMC dataset, we noticed an impressive 20% increase in medical NER performance compared to models trained on general Korean NER datasets. This research underscores the significant benefits and importance of using specialized tools and datasets, like ChatGPT, to enhance language processing in specialized fields such as healthcare.