 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCScore: Quantifying Response Consistency in Large Language Models
Oct 30, 2025



Current LLM evaluations often rely on a single instruction template, overlooking models' sensitivity to instruction style-a critical aspect for real-world deployments. We present RCScore, a multi-dimensional framework quantifying how instruction formulation affects model responses. By systematically transforming benchmark problems into multiple instruction styles, RCScore reveals performance variations undetected by conventional metrics. Our experiments across ten LLMs on four reasoning benchmarks demonstrate that instruction style can shift accuracy by up to 16.7% points. We introduce Cross-Response Similarity (CRS), a method applying RCScore metrics to measure stylistic self-consistency, and establish its strong correlation with task accuracy, suggesting consistency as a valuable proxy for model reliability. Additional findings show that deterministic decoding produces more stylistically stable outputs, and model scale correlates positively with cross-style consistency. RCScore offers a principled approach to assess instruction robustness.
P-CoT: A Pedagogically-motivated Participatory Chain-of-Thought Prompting for Phonological Reasoning in LLMs
Jul 22, 2025
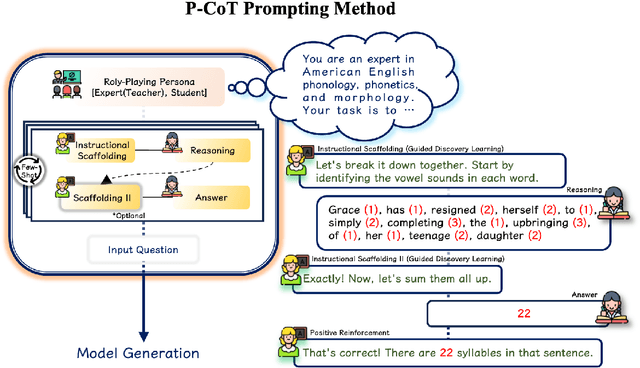
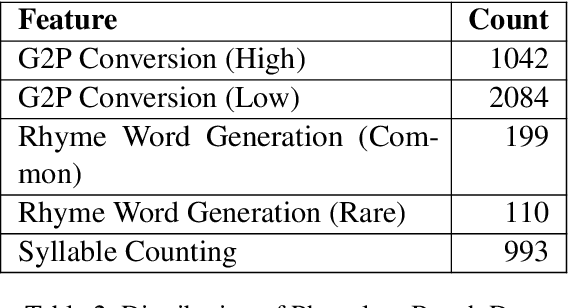
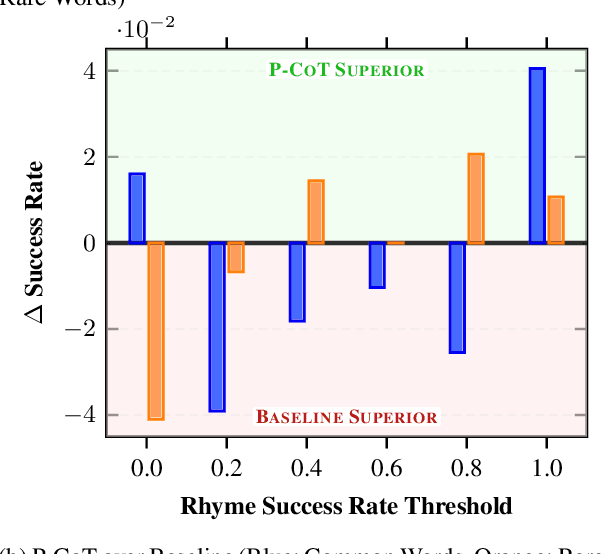
This study explores the potential of phonological reasoning within text-based large language models (LLMs). Utilizing the PhonologyBench benchmark, we assess tasks like rhyme word generation, g2p conversion, and syllable counting. Our evaluations across 12 LLMs reveal that while few-shot learning offers inconsistent gains, the introduction of a novel Pedagogically-motivated Participatory Chain-of-Thought (P-CoT) prompt, which is anchored in educational theories like scaffolding and discovery learning, consistently enhances performance. This method leverages structured guidance to activate latent phonological abilities, achieving up to 52% improvement and even surpassing human baselines in certain tasks. Future work could aim to optimize P-CoT prompts for specific models or explore their application across different linguistic domains.
KoBALT: Korean Benchmark For Advanced Linguistic Tasks
May 22, 2025
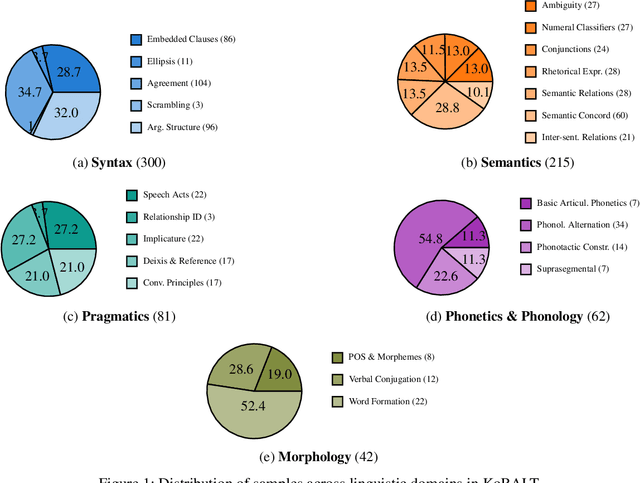

We introduce KoBALT (Korean Benchmark for Advanced Linguistic Tasks), a comprehensive linguistically-motivated benchmark comprising 700 multiple-choice questions spanning 24 phenomena across five linguistic domains: syntax, semantics, pragmatics, phonetics/phonology, and morphology. KoBALT is designed to advance the evaluation of large language models (LLMs) in Korean, a morphologically rich language, by addressing the limitations of conventional benchmarks that often lack linguistic depth and typological grounding. It introduces a suite of expert-curated, linguistically motivated questions with minimal n-gram overlap with standard Korean corpora, substantially mitigating the risk of data contamination and allowing a more robust assessment of true language understanding. Our evaluation of 20 contemporary LLMs reveals significant performance disparities, with the highest-performing model achieving 61\% general accuracy but showing substantial variation across linguistic domains - from stronger performance in semantics (66\%) to considerable weaknesses in phonology (31\%) and morphology (36\%). Through human preference evaluation with 95 annotators, we demonstrate a strong correlation between KoBALT scores and human judgments, validating our benchmark's effectiveness as a discriminative measure of Korean language understanding. KoBALT addresses critical gaps in linguistic evaluation for typologically diverse languages and provides a robust framework for assessing genuine linguistic competence in Korean language models.
DAHL: Domain-specific Automated Hallucination Evaluation of Long-Form Text through a Benchmark Dataset in Biomedicine
Nov 14, 2024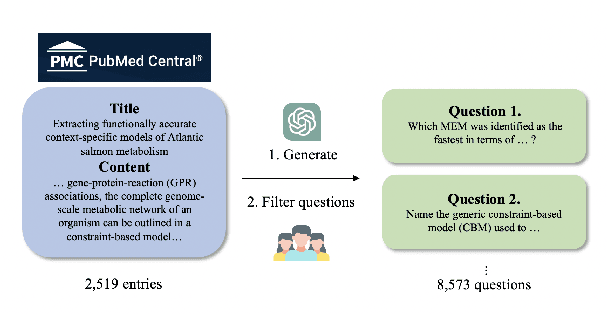

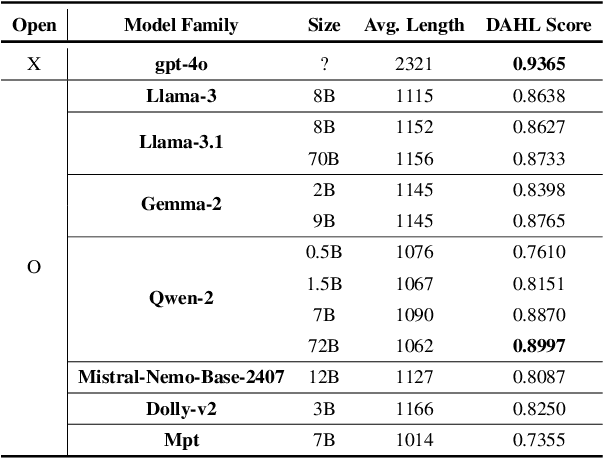
We introduce DAHL, a benchmark dataset and automated evaluation system designed to assess hallucination in long-form text generation, specifically within the biomedical domain. Our benchmark dataset, meticulously curated from biomedical research papers, consists of 8,573 questions across 29 categories. DAHL evaluates fact-conflicting hallucinations in Large Language Models (LLMs) by deconstructing responses into atomic units, each representing a single piece of information. The accuracy of these responses is averaged to produce the DAHL Score, offering a more in-depth evaluation of hallucinations compared to previous methods that rely on multiple-choice tasks. We conduct experiments with 8 different models, finding that larger models tend to hallucinate less; however, beyond a model size of 7 to 8 billion parameters, further scaling does not significantly improve factual accuracy. The DAHL Score holds potential as an efficient alternative to human-annotated preference labels, being able to be expanded to other specialized domains. We release the dataset and code in public.
KIT-19: A Comprehensive Korean Instruction Toolkit on 19 Tasks for Fine-Tuning Korean Large Language Models
Mar 25, 2024

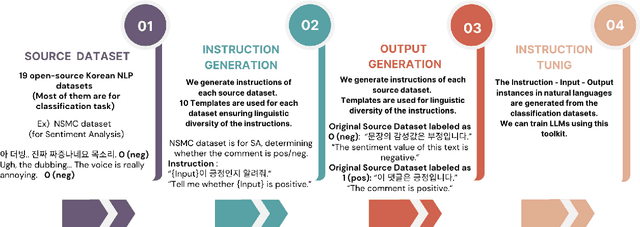
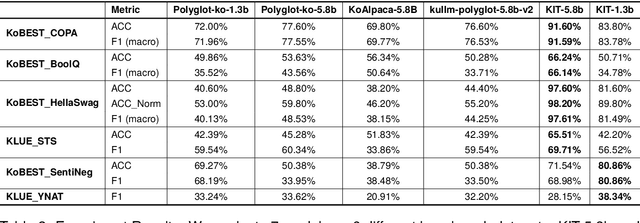
Instruction Tuning on Large Language Models is an essential process for model to function well and achieve high performance in specific tasks. Accordingly, in mainstream languages such as English, instruction-based datasets are being constructed and made publicly available. In the case of Korean, publicly available models and datasets all rely on using the output of ChatGPT or translating datasets built in English. In this paper, We introduce \textit{KIT-19} as an instruction dataset for the development of LLM in Korean. \textit{KIT-19} is a dataset created in an instruction format, comprising 19 existing open-source datasets for Korean NLP tasks. In this paper, we train a Korean Pretrained LLM using \textit{KIT-19} to demonstrate its effectiveness. The experimental results show that the model trained on \textit{KIT-19} significantly outperforms existing Korean LLMs. Based on the its quality and empirical results, this paper proposes that \textit{KIT-19} has the potential to make a substantial contribution to the future improvement of Korean LLMs' performance.
A Study on How Attention Scores in the BERT Model are Aware of Lexical Categories in Syntactic and Semantic Tasks on the GLUE Benchmark
Mar 25, 2024



This study examines whether the attention scores between tokens in the BERT model significantly vary based on lexical categories during the fine-tuning process for downstream tasks. Drawing inspiration from the notion that in human language processing, syntactic and semantic information is parsed differently, we categorize tokens in sentences according to their lexical categories and focus on changes in attention scores among these categories. Our hypothesis posits that in downstream tasks that prioritize semantic information, attention scores centered on content words are enhanced, while in cases emphasizing syntactic information, attention scores centered on function words are intensified. Through experimentation conducted on six tasks from the GLUE benchmark dataset, we substantiate our hypothesis regarding the fine-tuning process. Furthermore, our additional investigations reveal the presence of BERT layers that consistently assign more bias to specific lexical categories, irrespective of the task, highlighting the existence of task-agnostic lexical category preferences.
Korean Bio-Medical Corpus for Medical Named Entity Recognition
Mar 24, 2024Named Entity Recognition (NER) plays a pivotal role in medical Natural Language Processing (NLP). Yet, there has not been an open-source medical NER dataset specifically for the Korean language. To address this, we utilized ChatGPT to assist in constructing the KBMC (Korean Bio-Medical Corpus), which we are now presenting to the public. With the KBMC dataset, we noticed an impressive 20% increase in medical NER performance compared to models trained on general Korean NER datasets. This research underscores the significant benefits and importance of using specialized tools and datasets, like ChatGPT, to enhance language processing in specialized fields such as healthcare.
CARBD-Ko: A Contextually Annotated Review Benchmark Dataset for Aspect-Level Sentiment Classification in Korean
Feb 23, 2024



This paper explores the challenges posed by aspect-based sentiment classification (ABSC) within pretrained language models (PLMs), with a particular focus on contextualization and hallucination issues. In order to tackle these challenges, we introduce CARBD-Ko (a Contextually Annotated Review Benchmark Dataset for Aspect-Based Sentiment Classification in Korean), a benchmark dataset that incorporates aspects and dual-tagged polarities to distinguish between aspect-specific and aspect-agnostic sentiment classification. The dataset consists of sentences annotated with specific aspects, aspect polarity, aspect-agnostic polarity, and the intensity of aspects. To address the issue of dual-tagged aspect polarities, we propose a novel approach employing a Siamese Network. Our experimental findings highlight the inherent difficulties in accurately predicting dual-polarities and underscore the significance of contextualized sentiment analysis models. The CARBD-Ko dataset serves as a valuable resource for future research endeavors in aspect-level sentiment classification.
Automatic Construction of a Korean Toxic Instruction Dataset for Ethical Tuning of Large Language Models
Nov 30, 2023



Caution: this paper may include material that could be offensive or distressing. The advent of Large Language Models (LLMs) necessitates the development of training approaches that mitigate the generation of unethical language and aptly manage toxic user queries. Given the challenges related to human labor and the scarcity of data, we present KoTox, comprising 39K unethical instruction-output pairs. This collection of automatically generated toxic instructions refines the training of LLMs and establishes a foundational framework for improving LLMs' ethical awareness and response to various toxic inputs, promoting more secure and responsible interactions in Natural Language Processing (NLP) applications.
DaG LLM ver 1.0: Pioneering Instruction-Tuned Language Modeling for Korean NLP
Nov 23, 2023This paper presents the DaG LLM (David and Goliath Large Language Model), a language model specialized for Korean and fine-tuned through Instruction Tuning across 41 tasks within 13 distinct categories.