 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Multiple Scripts Matter: Evaluating ASR in Clinical Settings
Jun 16, 2026Automatic speech recognition (ASR) in non-English clinical settings is challenged by multiscript variability, where the same term may appear in multiple valid orthographic forms. Conventional string-matching evaluation metrics often underestimate ASR performance by treating orthographic variants as errors. To address this issue, we introduce MultiClin, a clinical ASR benchmark designed to evaluate robustness to multiscript variability. Experiments across diverse ASR models show that multiscript-aware evaluation provides a fairer assessment of recognition quality than conventional single-reference evaluation. We further investigate the impact of script consistency during training and find that inconsistent script mappings increase orthographic uncertainty and hinder model convergence, with a balanced 50% mapping ratio producing the highest entropy. In contrast, script unification consistently yields the best ASR performance. Our dataset and code are publicly available at: https://github.com/aitrics-ronaldo/Interspeech_MultiClin.
Evaluating the Pre-Consultation Ability of LLMs using Diagnostic Guidelines
Jan 08, 2026We introduce EPAG, a benchmark dataset and framework designed for Evaluating the Pre-consultation Ability of LLMs using diagnostic Guidelines. LLMs are evaluated directly through HPI-diagnostic guideline comparison and indirectly through disease diagnosis. In our experiments, we observe that small open-source models fine-tuned with a well-curated, task-specific dataset can outperform frontier LLMs in pre-consultation. Additionally, we find that increased amount of HPI (History of Present Illness) does not necessarily lead to improved diagnostic performance. Further experiments reveal that the language of pre-consultation influences the characteristics of the dialogue. By open-sourcing our dataset and evaluation pipeline on https://github.com/seemdog/EPAG, we aim to contribute to the evaluation and further development of LLM applications in real-world clinical settings.
Format Inertia: A Failure Mechanism of LLMs in Medical Pre-Consultation
Oct 02, 2025Recent advances in Large Language Models (LLMs) have brought significant improvements to various service domains, including chatbots and medical pre-consultation applications. In the healthcare domain, the most common approach for adapting LLMs to multi-turn dialogue generation is Supervised Fine-Tuning (SFT). However, datasets for SFT in tasks like medical pre-consultation typically exhibit a skewed turn-count distribution. Training on such data induces a novel failure mechanism we term **Format Inertia**, where models tend to generate repetitive, format-correct, but diagnostically uninformative questions in long medical dialogues. To mitigate this observed failure mechanism, we adopt a simple, data-centric method that rebalances the turn-count distribution of the training dataset. Experimental results show that our approach substantially alleviates Format Inertia in medical pre-consultation.
Taxonomy of Comprehensive Safety for Clinical Agents
Sep 26, 2025Safety is a paramount concern in clinical chatbot applications, where inaccurate or harmful responses can lead to serious consequences. Existing methods--such as guardrails and tool calling--often fall short in addressing the nuanced demands of the clinical domain. In this paper, we introduce TACOS (TAxonomy of COmprehensive Safety for Clinical Agents), a fine-grained, 21-class taxonomy that integrates safety filtering and tool selection into a single user intent classification step. TACOS is a taxonomy that can cover a wide spectrum of clinical and non-clinical queries, explicitly modeling varying safety thresholds and external tool dependencies. To validate our framework, we curate a TACOS-annotated dataset and perform extensive experiments. Our results demonstrate the value of a new taxonomy specialized for clinical agent settings, and reveal useful insights about train data distribution and pretrained knowledge of base models.
MoFE: Mixture of Frozen Experts Architecture
Mar 09, 2025


We propose the Mixture of Frozen Experts (MoFE) architecture, which integrates Parameter-efficient Fine-tuning (PEFT) and the Mixture of Experts (MoE) architecture to enhance both training efficiency and model scalability. By freezing the Feed Forward Network (FFN) layers within the MoE framework, MoFE significantly reduces the number of trainable parameters, improving training efficiency while still allowing for effective knowledge transfer from the expert models. This facilitates the creation of models proficient in multiple domains. We conduct experiments to evaluate the trade-offs between performance and efficiency, compare MoFE with other PEFT methodologies, assess the impact of domain expertise in the constituent models, and determine the optimal training strategy. The results show that, although there may be some trade-offs in performance, the efficiency gains are substantial, making MoFE a reasonable solution for real-world, resource-constrained environments.
How does a Language-Specific Tokenizer affect LLMs?
Feb 18, 2025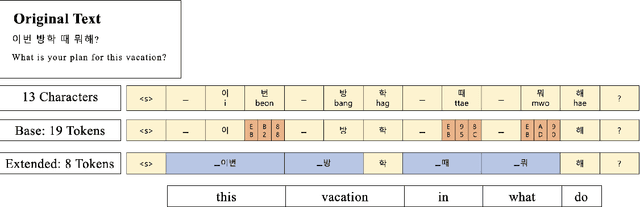
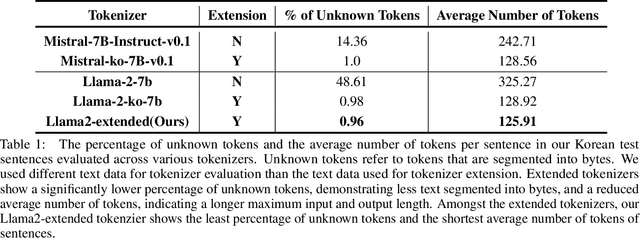

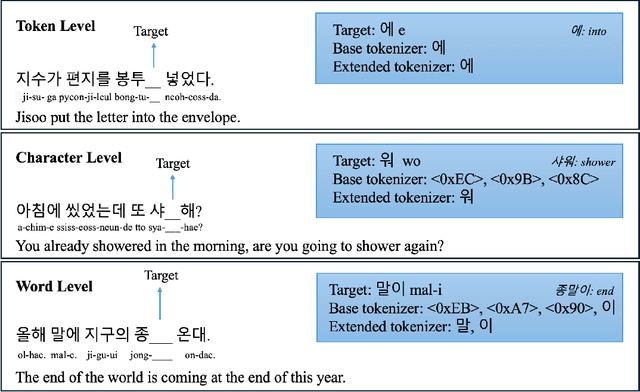
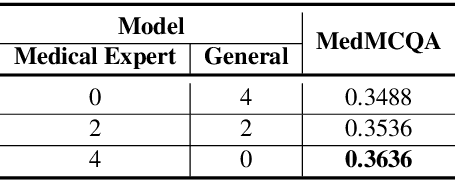
The necessity of language-specific tokenizers intuitively appears crucial for effective natural language processing, yet empirical analyses on their significance and underlying reasons are lacking. This study explores how language-specific tokenizers influence the behavior of Large Language Models predominantly trained with English text data, through the case study of Korean. The research unfolds in two main stages: (1) the development of a Korean-specific extended tokenizer and (2) experiments to compare models with the basic tokenizer and the extended tokenizer through various Next Token Prediction tasks. Our in-depth analysis reveals that the extended tokenizer decreases confidence in incorrect predictions during generation and reduces cross-entropy in complex tasks, indicating a tendency to produce less nonsensical outputs. Consequently, the extended tokenizer provides stability during generation, potentially leading to higher performance in downstream tasks.
DAHL: Domain-specific Automated Hallucination Evaluation of Long-Form Text through a Benchmark Dataset in Biomedicine
Nov 14, 2024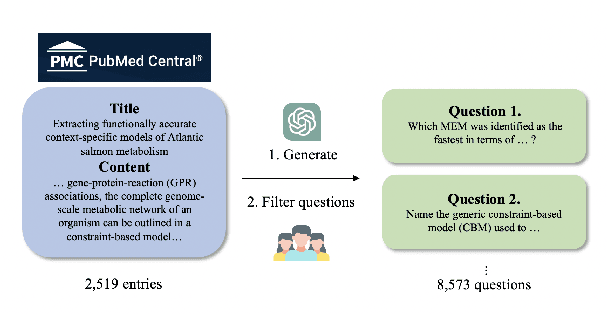

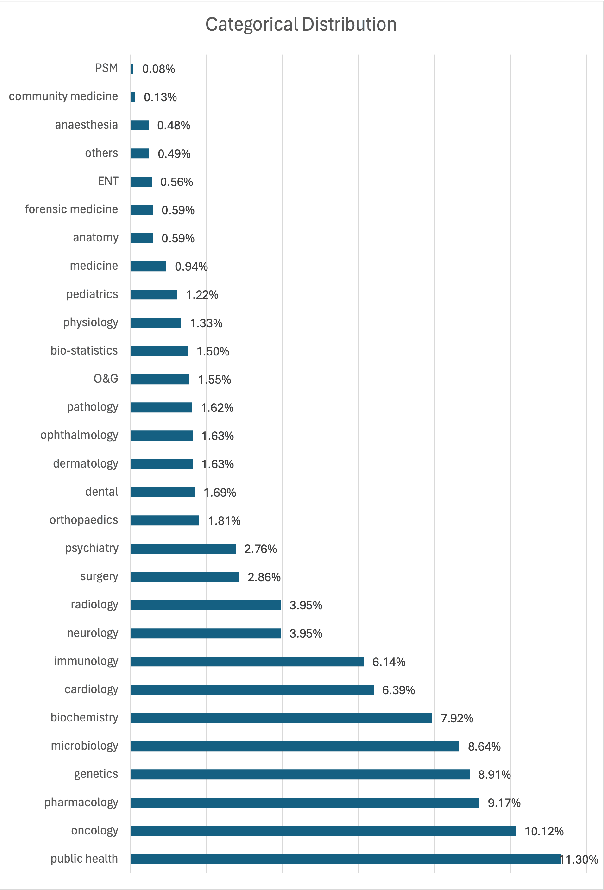
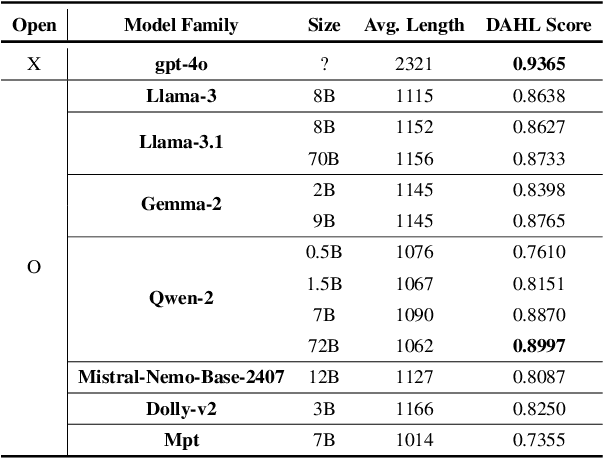
We introduce DAHL, a benchmark dataset and automated evaluation system designed to assess hallucination in long-form text generation, specifically within the biomedical domain. Our benchmark dataset, meticulously curated from biomedical research papers, consists of 8,573 questions across 29 categories. DAHL evaluates fact-conflicting hallucinations in Large Language Models (LLMs) by deconstructing responses into atomic units, each representing a single piece of information. The accuracy of these responses is averaged to produce the DAHL Score, offering a more in-depth evaluation of hallucinations compared to previous methods that rely on multiple-choice tasks. We conduct experiments with 8 different models, finding that larger models tend to hallucinate less; however, beyond a model size of 7 to 8 billion parameters, further scaling does not significantly improve factual accuracy. The DAHL Score holds potential as an efficient alternative to human-annotated preference labels, being able to be expanded to other specialized domains. We release the dataset and code in public.
ManWav: The First Manchu ASR Model
Jun 19, 2024
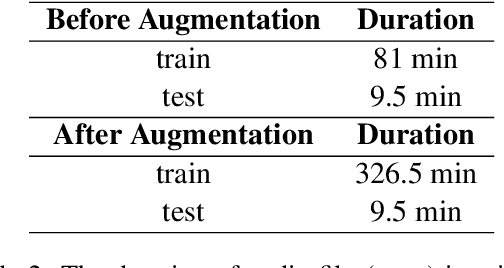
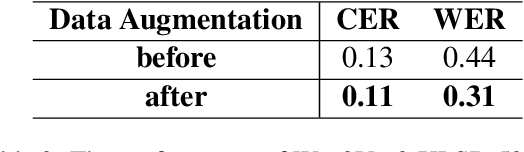

This study addresses the widening gap in Automatic Speech Recognition (ASR) research between high resource and extremely low resource languages, with a particular focus on Manchu, a critically endangered language. Manchu exemplifies the challenges faced by marginalized linguistic communities in accessing state-of-the-art technologies. In a pioneering effort, we introduce the first-ever Manchu ASR model ManWav, leveraging Wav2Vec2-XLSR-53. The results of the first Manchu ASR is promising, especially when trained with our augmented data. Wav2Vec2-XLSR-53 fine-tuned with augmented data demonstrates a 0.02 drop in CER and 0.13 drop in WER compared to the same base model fine-tuned with original data.
Korean Bio-Medical Corpus for Medical Named Entity Recognition
Mar 24, 2024Named Entity Recognition (NER) plays a pivotal role in medical Natural Language Processing (NLP). Yet, there has not been an open-source medical NER dataset specifically for the Korean language. To address this, we utilized ChatGPT to assist in constructing the KBMC (Korean Bio-Medical Corpus), which we are now presenting to the public. With the KBMC dataset, we noticed an impressive 20% increase in medical NER performance compared to models trained on general Korean NER datasets. This research underscores the significant benefits and importance of using specialized tools and datasets, like ChatGPT, to enhance language processing in specialized fields such as healthcare.
CARBD-Ko: A Contextually Annotated Review Benchmark Dataset for Aspect-Level Sentiment Classification in Korean
Feb 23, 2024



This paper explores the challenges posed by aspect-based sentiment classification (ABSC) within pretrained language models (PLMs), with a particular focus on contextualization and hallucination issues. In order to tackle these challenges, we introduce CARBD-Ko (a Contextually Annotated Review Benchmark Dataset for Aspect-Based Sentiment Classification in Korean), a benchmark dataset that incorporates aspects and dual-tagged polarities to distinguish between aspect-specific and aspect-agnostic sentiment classification. The dataset consists of sentences annotated with specific aspects, aspect polarity, aspect-agnostic polarity, and the intensity of aspects. To address the issue of dual-tagged aspect polarities, we propose a novel approach employing a Siamese Network. Our experimental findings highlight the inherent difficulties in accurately predicting dual-polarities and underscore the significance of contextualized sentiment analysis models. The CARBD-Ko dataset serves as a valuable resource for future research endeavors in aspect-level sentiment classification.