 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoFE: Mixture of Frozen Experts Architecture
Paper and Code
Mar 09, 2025


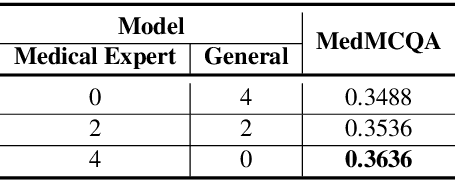
We propose the Mixture of Frozen Experts (MoFE) architecture, which integrates Parameter-efficient Fine-tuning (PEFT) and the Mixture of Experts (MoE) architecture to enhance both training efficiency and model scalability. By freezing the Feed Forward Network (FFN) layers within the MoE framework, MoFE significantly reduces the number of trainable parameters, improving training efficiency while still allowing for effective knowledge transfer from the expert models. This facilitates the creation of models proficient in multiple domains. We conduct experiments to evaluate the trade-offs between performance and efficiency, compare MoFE with other PEFT methodologies, assess the impact of domain expertise in the constituent models, and determine the optimal training strategy. The results show that, although there may be some trade-offs in performance, the efficiency gains are substantial, making MoFE a reasonable solution for real-world, resource-constrained environments.