 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does a Language-Specific Tokenizer affect LLMs?
Paper and Code
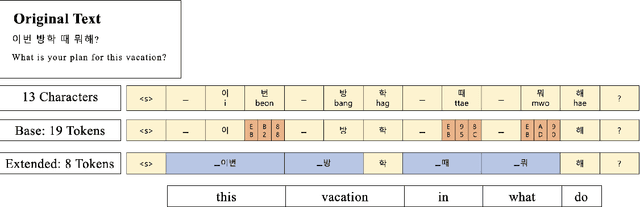
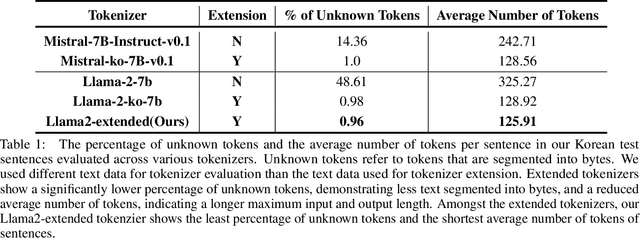

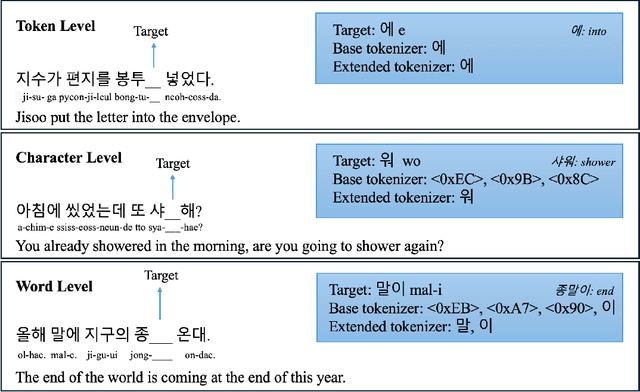
The necessity of language-specific tokenizers intuitively appears crucial for effective natural language processing, yet empirical analyses on their significance and underlying reasons are lacking. This study explores how language-specific tokenizers influence the behavior of Large Language Models predominantly trained with English text data, through the case study of Korean. The research unfolds in two main stages: (1) the development of a Korean-specific extended tokenizer and (2) experiments to compare models with the basic tokenizer and the extended tokenizer through various Next Token Prediction tasks. Our in-depth analysis reveals that the extended tokenizer decreases confidence in incorrect predictions during generation and reduces cross-entropy in complex tasks, indicating a tendency to produce less nonsensical outputs. Consequently, the extended tokenizer provides stability during generation, potentially leading to higher performance in downstream tasks.