 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoBALT: Korean Benchmark For Advanced Linguistic Tasks
May 22, 2025
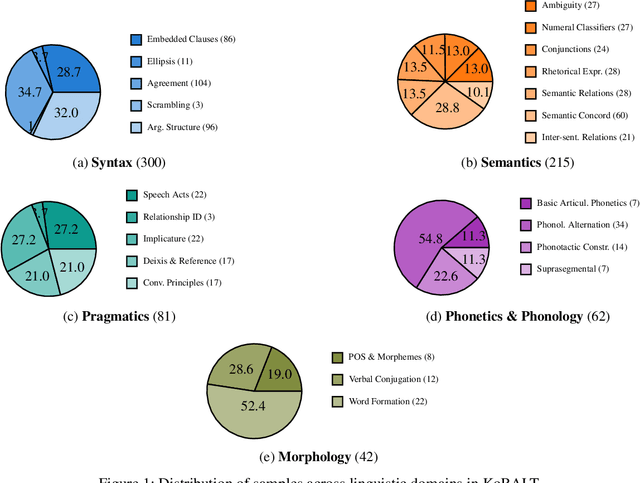
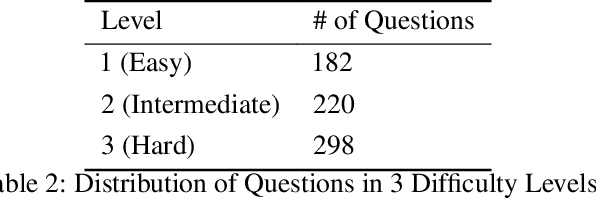

We introduce KoBALT (Korean Benchmark for Advanced Linguistic Tasks), a comprehensive linguistically-motivated benchmark comprising 700 multiple-choice questions spanning 24 phenomena across five linguistic domains: syntax, semantics, pragmatics, phonetics/phonology, and morphology. KoBALT is designed to advance the evaluation of large language models (LLMs) in Korean, a morphologically rich language, by addressing the limitations of conventional benchmarks that often lack linguistic depth and typological grounding. It introduces a suite of expert-curated, linguistically motivated questions with minimal n-gram overlap with standard Korean corpora, substantially mitigating the risk of data contamination and allowing a more robust assessment of true language understanding. Our evaluation of 20 contemporary LLMs reveals significant performance disparities, with the highest-performing model achieving 61\% general accuracy but showing substantial variation across linguistic domains - from stronger performance in semantics (66\%) to considerable weaknesses in phonology (31\%) and morphology (36\%). Through human preference evaluation with 95 annotators, we demonstrate a strong correlation between KoBALT scores and human judgments, validating our benchmark's effectiveness as a discriminative measure of Korean language understanding. KoBALT addresses critical gaps in linguistic evaluation for typologically diverse languages and provides a robust framework for assessing genuine linguistic competence in Korean language models.
Korean Bio-Medical Corpus for Medical Named Entity Recognition
Mar 24, 2024Named Entity Recognition (NER) plays a pivotal role in medical Natural Language Processing (NLP). Yet, there has not been an open-source medical NER dataset specifically for the Korean language. To address this, we utilized ChatGPT to assist in constructing the KBMC (Korean Bio-Medical Corpus), which we are now presenting to the public. With the KBMC dataset, we noticed an impressive 20% increase in medical NER performance compared to models trained on general Korean NER datasets. This research underscores the significant benefits and importance of using specialized tools and datasets, like ChatGPT, to enhance language processing in specialized fields such as healthcare.
DaG LLM ver 1.0: Pioneering Instruction-Tuned Language Modeling for Korean NLP
Nov 23, 2023This paper presents the DaG LLM (David and Goliath Large Language Model), a language model specialized for Korean and fine-tuned through Instruction Tuning across 41 tasks within 13 distinct categories.