 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManWav: The First Manchu ASR Model
Jun 19, 2024
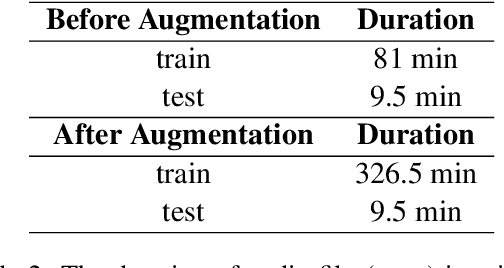
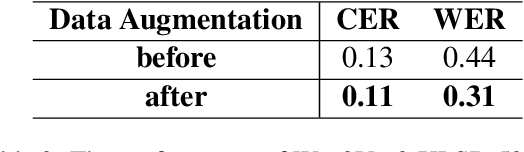

This study addresses the widening gap in Automatic Speech Recognition (ASR) research between high resource and extremely low resource languages, with a particular focus on Manchu, a critically endangered language. Manchu exemplifies the challenges faced by marginalized linguistic communities in accessing state-of-the-art technologies. In a pioneering effort, we introduce the first-ever Manchu ASR model ManWav, leveraging Wav2Vec2-XLSR-53. The results of the first Manchu ASR is promising, especially when trained with our augmented data. Wav2Vec2-XLSR-53 fine-tuned with augmented data demonstrates a 0.02 drop in CER and 0.13 drop in WER compared to the same base model fine-tuned with original data.
A Study on How Attention Scores in the BERT Model are Aware of Lexical Categories in Syntactic and Semantic Tasks on the GLUE Benchmark
Mar 25, 2024



This study examines whether the attention scores between tokens in the BERT model significantly vary based on lexical categories during the fine-tuning process for downstream tasks. Drawing inspiration from the notion that in human language processing, syntactic and semantic information is parsed differently, we categorize tokens in sentences according to their lexical categories and focus on changes in attention scores among these categories. Our hypothesis posits that in downstream tasks that prioritize semantic information, attention scores centered on content words are enhanced, while in cases emphasizing syntactic information, attention scores centered on function words are intensified. Through experimentation conducted on six tasks from the GLUE benchmark dataset, we substantiate our hypothesis regarding the fine-tuning process. Furthermore, our additional investigations reveal the presence of BERT layers that consistently assign more bias to specific lexical categories, irrespective of the task, highlighting the existence of task-agnostic lexical category preferences.
KIT-19: A Comprehensive Korean Instruction Toolkit on 19 Tasks for Fine-Tuning Korean Large Language Models
Mar 25, 2024

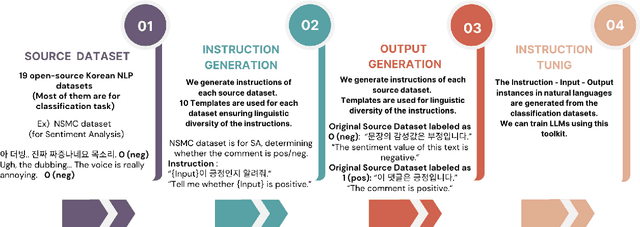
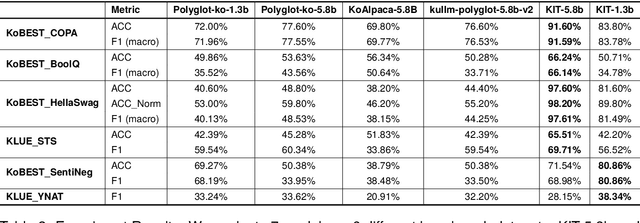
Instruction Tuning on Large Language Models is an essential process for model to function well and achieve high performance in specific tasks. Accordingly, in mainstream languages such as English, instruction-based datasets are being constructed and made publicly available. In the case of Korean, publicly available models and datasets all rely on using the output of ChatGPT or translating datasets built in English. In this paper, We introduce \textit{KIT-19} as an instruction dataset for the development of LLM in Korean. \textit{KIT-19} is a dataset created in an instruction format, comprising 19 existing open-source datasets for Korean NLP tasks. In this paper, we train a Korean Pretrained LLM using \textit{KIT-19} to demonstrate its effectiveness. The experimental results show that the model trained on \textit{KIT-19} significantly outperforms existing Korean LLMs. Based on the its quality and empirical results, this paper proposes that \textit{KIT-19} has the potential to make a substantial contribution to the future improvement of Korean LLMs' performance.
Korean Bio-Medical Corpus for Medical Named Entity Recognition
Mar 24, 2024Named Entity Recognition (NER) plays a pivotal role in medical Natural Language Processing (NLP). Yet, there has not been an open-source medical NER dataset specifically for the Korean language. To address this, we utilized ChatGPT to assist in constructing the KBMC (Korean Bio-Medical Corpus), which we are now presenting to the public. With the KBMC dataset, we noticed an impressive 20% increase in medical NER performance compared to models trained on general Korean NER datasets. This research underscores the significant benefits and importance of using specialized tools and datasets, like ChatGPT, to enhance language processing in specialized fields such as healthcare.
CARBD-Ko: A Contextually Annotated Review Benchmark Dataset for Aspect-Level Sentiment Classification in Korean
Feb 23, 2024



This paper explores the challenges posed by aspect-based sentiment classification (ABSC) within pretrained language models (PLMs), with a particular focus on contextualization and hallucination issues. In order to tackle these challenges, we introduce CARBD-Ko (a Contextually Annotated Review Benchmark Dataset for Aspect-Based Sentiment Classification in Korean), a benchmark dataset that incorporates aspects and dual-tagged polarities to distinguish between aspect-specific and aspect-agnostic sentiment classification. The dataset consists of sentences annotated with specific aspects, aspect polarity, aspect-agnostic polarity, and the intensity of aspects. To address the issue of dual-tagged aspect polarities, we propose a novel approach employing a Siamese Network. Our experimental findings highlight the inherent difficulties in accurately predicting dual-polarities and underscore the significance of contextualized sentiment analysis models. The CARBD-Ko dataset serves as a valuable resource for future research endeavors in aspect-level sentiment classification.
Automatic Construction of a Korean Toxic Instruction Dataset for Ethical Tuning of Large Language Models
Nov 30, 2023



Caution: this paper may include material that could be offensive or distressing. The advent of Large Language Models (LLMs) necessitates the development of training approaches that mitigate the generation of unethical language and aptly manage toxic user queries. Given the challenges related to human labor and the scarcity of data, we present KoTox, comprising 39K unethical instruction-output pairs. This collection of automatically generated toxic instructions refines the training of LLMs and establishes a foundational framework for improving LLMs' ethical awareness and response to various toxic inputs, promoting more secure and responsible interactions in Natural Language Processing (NLP) applications.
Mergen: The First Manchu-Korean Machine Translation Model Trained on Augmented Data
Nov 29, 2023The Manchu language, with its roots in the historical Manchurian region of Northeast China, is now facing a critical threat of extinction, as there are very few speakers left. In our efforts to safeguard the Manchu language, we introduce Mergen, the first-ever attempt at a Manchu-Korean Machine Translation (MT) model. To develop this model, we utilize valuable resources such as the Manwen Laodang(a historical book) and a Manchu-Korean dictionary. Due to the scarcity of a Manchu-Korean parallel dataset, we expand our data by employing word replacement guided by GloVe embeddings, trained on both monolingual and parallel texts. Our approach is built around an encoder-decoder neural machine translation model, incorporating a bi-directional Gated Recurrent Unit (GRU) layer. The experiments have yielded promising results, showcasing a significant enhancement in Manchu-Korean translation, with a remarkable 20-30 point increase in the BLEU score.
DaG LLM ver 1.0: Pioneering Instruction-Tuned Language Modeling for Korean NLP
Nov 23, 2023This paper presents the DaG LLM (David and Goliath Large Language Model), a language model specialized for Korean and fine-tuned through Instruction Tuning across 41 tasks within 13 distinct categories.