 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManWav: The First Manchu ASR Model
Jun 19, 2024
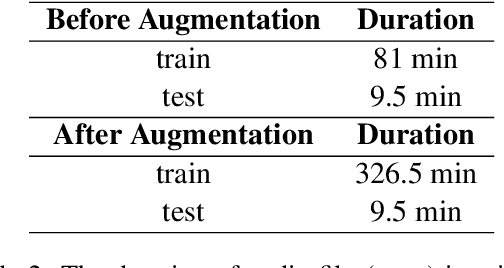
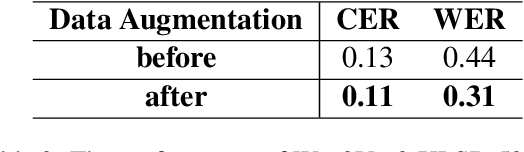

This study addresses the widening gap in Automatic Speech Recognition (ASR) research between high resource and extremely low resource languages, with a particular focus on Manchu, a critically endangered language. Manchu exemplifies the challenges faced by marginalized linguistic communities in accessing state-of-the-art technologies. In a pioneering effort, we introduce the first-ever Manchu ASR model ManWav, leveraging Wav2Vec2-XLSR-53. The results of the first Manchu ASR is promising, especially when trained with our augmented data. Wav2Vec2-XLSR-53 fine-tuned with augmented data demonstrates a 0.02 drop in CER and 0.13 drop in WER compared to the same base model fine-tuned with original data.
Mergen: The First Manchu-Korean Machine Translation Model Trained on Augmented Data
Nov 29, 2023The Manchu language, with its roots in the historical Manchurian region of Northeast China, is now facing a critical threat of extinction, as there are very few speakers left. In our efforts to safeguard the Manchu language, we introduce Mergen, the first-ever attempt at a Manchu-Korean Machine Translation (MT) model. To develop this model, we utilize valuable resources such as the Manwen Laodang(a historical book) and a Manchu-Korean dictionary. Due to the scarcity of a Manchu-Korean parallel dataset, we expand our data by employing word replacement guided by GloVe embeddings, trained on both monolingual and parallel texts. Our approach is built around an encoder-decoder neural machine translation model, incorporating a bi-directional Gated Recurrent Unit (GRU) layer. The experiments have yielded promising results, showcasing a significant enhancement in Manchu-Korean translation, with a remarkable 20-30 point increase in the BLEU score.