Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManWav: The First Manchu ASR Model
Paper and Code

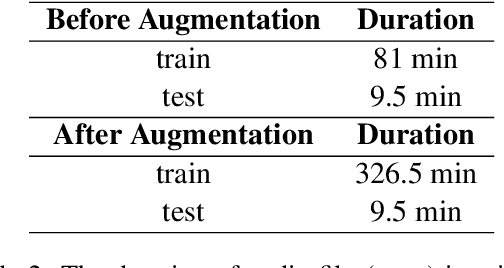
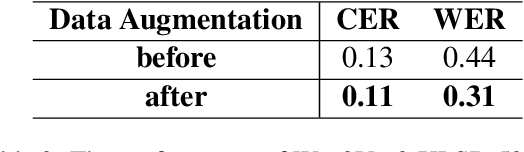

This study addresses the widening gap in Automatic Speech Recognition (ASR) research between high resource and extremely low resource languages, with a particular focus on Manchu, a critically endangered language. Manchu exemplifies the challenges faced by marginalized linguistic communities in accessing state-of-the-art technologies. In a pioneering effort, we introduce the first-ever Manchu ASR model ManWav, leveraging Wav2Vec2-XLSR-53. The results of the first Manchu ASR is promising, especially when trained with our augmented data. Wav2Vec2-XLSR-53 fine-tuned with augmented data demonstrates a 0.02 drop in CER and 0.13 drop in WER compared to the same base model fine-tuned with original data.
* ACL2024/Field Matters
View paper on