 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoBALT: Korean Benchmark For Advanced Linguistic Tasks
May 22, 2025
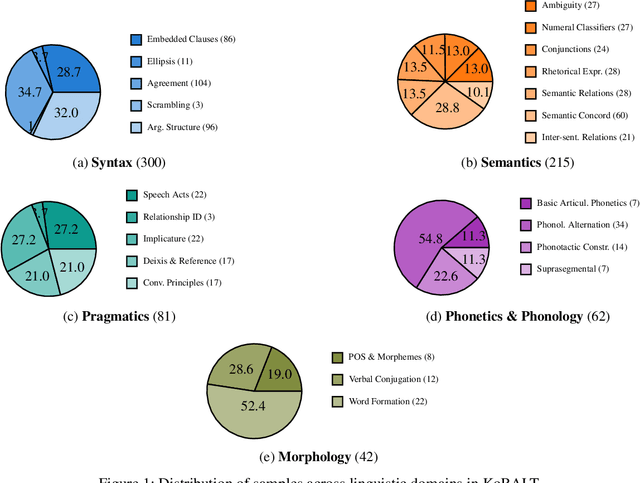

We introduce KoBALT (Korean Benchmark for Advanced Linguistic Tasks), a comprehensive linguistically-motivated benchmark comprising 700 multiple-choice questions spanning 24 phenomena across five linguistic domains: syntax, semantics, pragmatics, phonetics/phonology, and morphology. KoBALT is designed to advance the evaluation of large language models (LLMs) in Korean, a morphologically rich language, by addressing the limitations of conventional benchmarks that often lack linguistic depth and typological grounding. It introduces a suite of expert-curated, linguistically motivated questions with minimal n-gram overlap with standard Korean corpora, substantially mitigating the risk of data contamination and allowing a more robust assessment of true language understanding. Our evaluation of 20 contemporary LLMs reveals significant performance disparities, with the highest-performing model achieving 61\% general accuracy but showing substantial variation across linguistic domains - from stronger performance in semantics (66\%) to considerable weaknesses in phonology (31\%) and morphology (36\%). Through human preference evaluation with 95 annotators, we demonstrate a strong correlation between KoBALT scores and human judgments, validating our benchmark's effectiveness as a discriminative measure of Korean language understanding. KoBALT addresses critical gaps in linguistic evaluation for typologically diverse languages and provides a robust framework for assessing genuine linguistic competence in Korean language models.
KIT-19: A Comprehensive Korean Instruction Toolkit on 19 Tasks for Fine-Tuning Korean Large Language Models
Mar 25, 2024

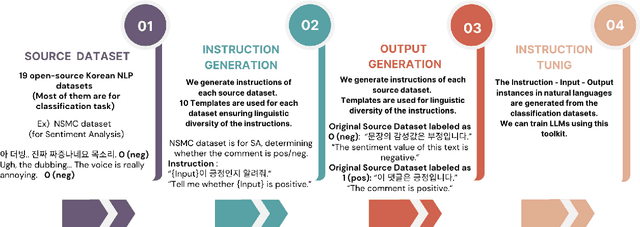
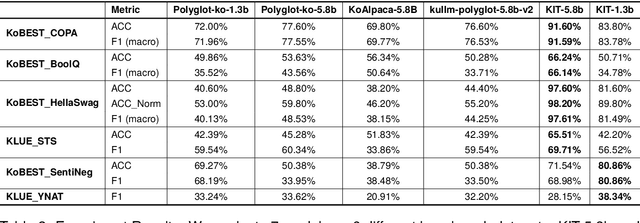
Instruction Tuning on Large Language Models is an essential process for model to function well and achieve high performance in specific tasks. Accordingly, in mainstream languages such as English, instruction-based datasets are being constructed and made publicly available. In the case of Korean, publicly available models and datasets all rely on using the output of ChatGPT or translating datasets built in English. In this paper, We introduce \textit{KIT-19} as an instruction dataset for the development of LLM in Korean. \textit{KIT-19} is a dataset created in an instruction format, comprising 19 existing open-source datasets for Korean NLP tasks. In this paper, we train a Korean Pretrained LLM using \textit{KIT-19} to demonstrate its effectiveness. The experimental results show that the model trained on \textit{KIT-19} significantly outperforms existing Korean LLMs. Based on the its quality and empirical results, this paper proposes that \textit{KIT-19} has the potential to make a substantial contribution to the future improvement of Korean LLMs' performance.
Automatic Construction of a Korean Toxic Instruction Dataset for Ethical Tuning of Large Language Models
Nov 30, 2023



Caution: this paper may include material that could be offensive or distressing. The advent of Large Language Models (LLMs) necessitates the development of training approaches that mitigate the generation of unethical language and aptly manage toxic user queries. Given the challenges related to human labor and the scarcity of data, we present KoTox, comprising 39K unethical instruction-output pairs. This collection of automatically generated toxic instructions refines the training of LLMs and establishes a foundational framework for improving LLMs' ethical awareness and response to various toxic inputs, promoting more secure and responsible interactions in Natural Language Processing (NLP) applications.
DaG LLM ver 1.0: Pioneering Instruction-Tuned Language Modeling for Korean NLP
Nov 23, 2023This paper presents the DaG LLM (David and Goliath Large Language Model), a language model specialized for Korean and fine-tuned through Instruction Tuning across 41 tasks within 13 distinct categories.