 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Personalized Persuasiveness Prediction via Context-Aware User Profiling
Jan 09, 2026Estimating the persuasiveness of messages is critical in various applications, from recommender systems to safety assessment of LLMs. While it is imperative to consider the target persuadee's characteristics, such as their values, experiences, and reasoning styles, there is currently no established systematic framework to optimize leveraging a persuadee's past activities (e.g., conversations) to the benefit of a persuasiveness prediction model. To address this problem, we propose a context-aware user profiling framework with two trainable components: a query generator that generates optimal queries to retrieve persuasion-relevant records from a user's history, and a profiler that summarizes these records into a profile to effectively inform the persuasiveness prediction model. Our evaluation on the ChangeMyView Reddit dataset shows consistent improvements over existing methods across multiple predictor models, with gains of up to +13.77%p in F1 score. Further analysis shows that effective user profiles are context-dependent and predictor-specific, rather than relying on static attributes or surface-level similarity. Together, these results highlight the importance of task-oriented, context-dependent user profiling for personalized persuasiveness prediction.
DAHL: Domain-specific Automated Hallucination Evaluation of Long-Form Text through a Benchmark Dataset in Biomedicine
Nov 14, 2024

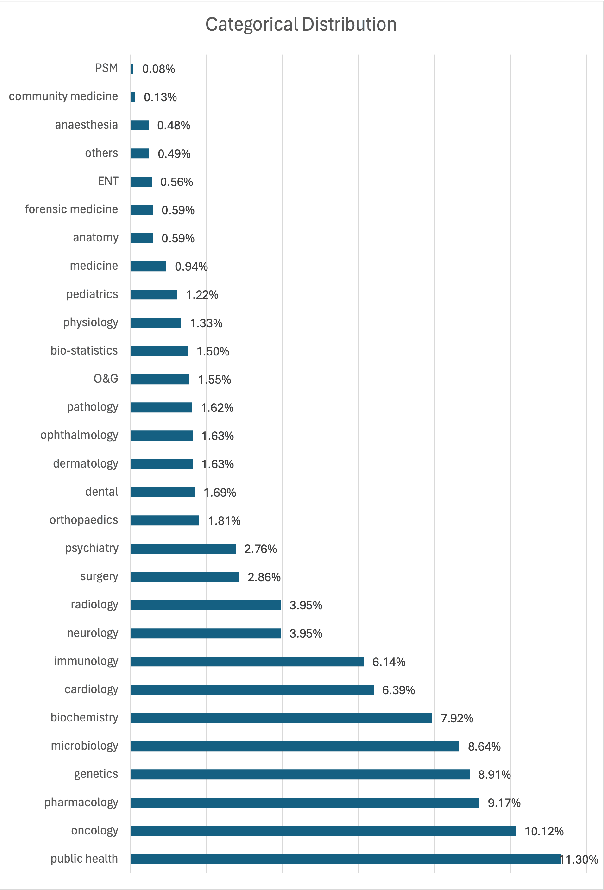
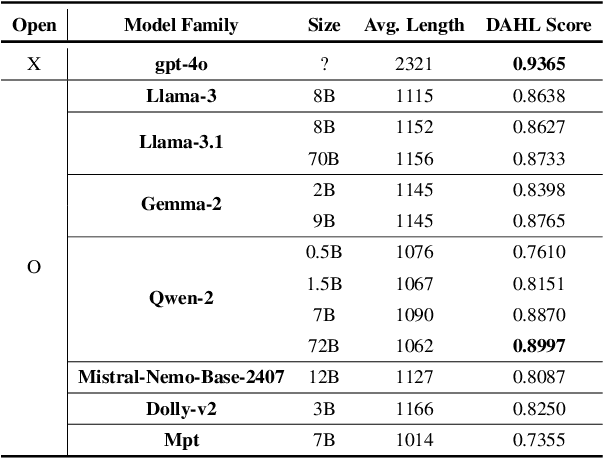
We introduce DAHL, a benchmark dataset and automated evaluation system designed to assess hallucination in long-form text generation, specifically within the biomedical domain. Our benchmark dataset, meticulously curated from biomedical research papers, consists of 8,573 questions across 29 categories. DAHL evaluates fact-conflicting hallucinations in Large Language Models (LLMs) by deconstructing responses into atomic units, each representing a single piece of information. The accuracy of these responses is averaged to produce the DAHL Score, offering a more in-depth evaluation of hallucinations compared to previous methods that rely on multiple-choice tasks. We conduct experiments with 8 different models, finding that larger models tend to hallucinate less; however, beyond a model size of 7 to 8 billion parameters, further scaling does not significantly improve factual accuracy. The DAHL Score holds potential as an efficient alternative to human-annotated preference labels, being able to be expanded to other specialized domains. We release the dataset and code in public.
Learning to increase matching efficiency in identifying additional b-jets in the $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ process
Mar 16, 2021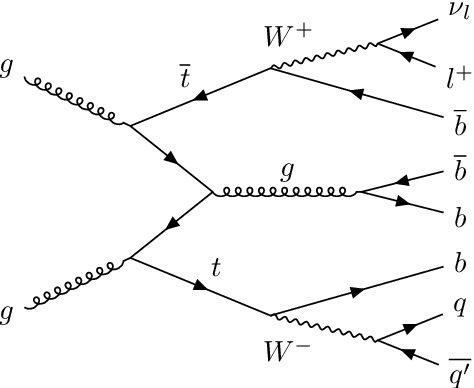
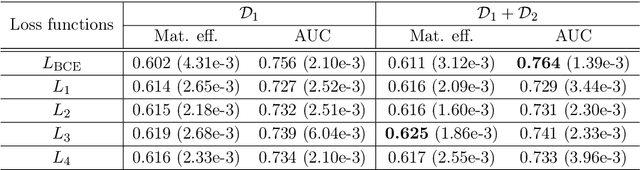
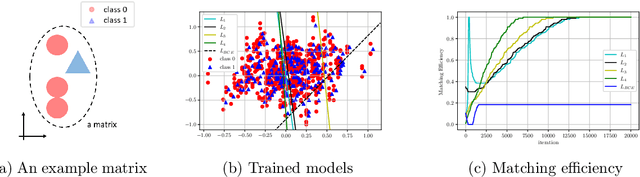
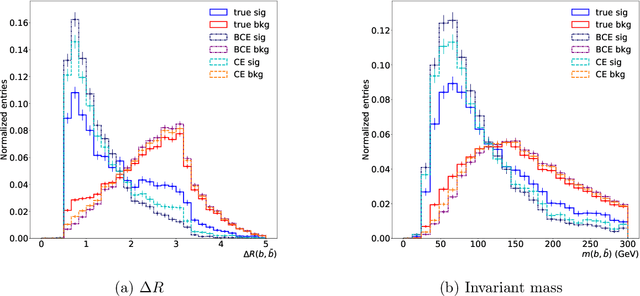
The $\text{t}\bar{\text{t}}\text{H}(\text{b}\bar{\text{b}})$ process is an essential channel to reveal the Higgs properties but has an irreducible background from the $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ process, which produces a top quark pair in association with a b quark pair. Therefore, understanding the $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ process is crucial for improving the sensitivity of a search for the $\text{t}\bar{\text{t}}\text{H}(\text{b}\bar{\text{b}})$ process. To this end, when measuring the differential cross-section of the $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ process, we need to distinguish the b-jets originated from top quark decays, and additional b-jets originated from gluon splitting. Since there are no simple identification rules, we adopt deep learning methods to learn from data to identify the additional b-jets from the $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ events. Specifically, by exploiting the special structure of the $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ event data, we propose several loss functions that can be minimized to directly increase the matching efficiency, the accuracy of identifying additional b-jets. We discuss the difference between our method and another deep learning-based approach based on binary classification arXiv:1910.14535 using synthetic data. We then verify that additional b-jets can be identified more accurately by increasing matching efficiency directly rather than the binary classification accuracy, using simulated $\text{t}\bar{\text{t}}\text{b}\bar{\text{b}}$ event data in the lepton+jets channel from pp collision at $\sqrt{s}$ = 13 TeV.