 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Techniques for the Conditional Generative Augmentation of Clinical Audio Data
Paper and Code
Nov 05, 2022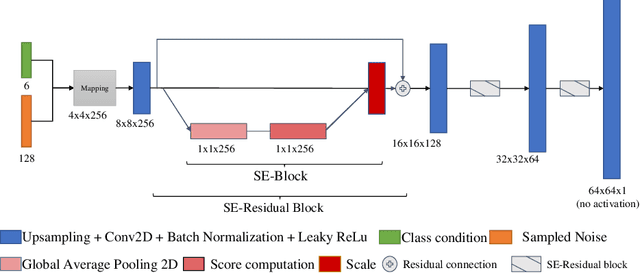

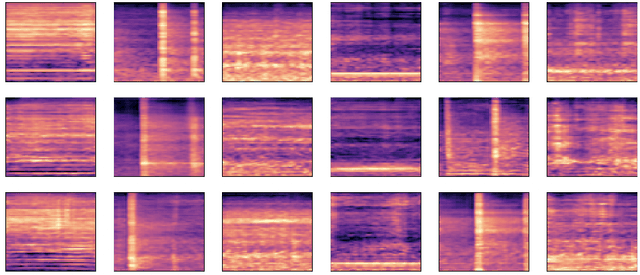
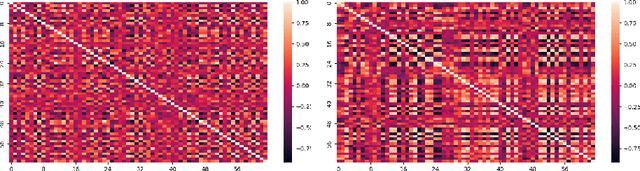
Data augmentation is a valuable tool for the design of deep learning systems to overcome data limitations and stabilize the training process. Especially in the medical domain, where the collection of large-scale data sets is challenging and expensive due to limited access to patient data, relevant environments, as well as strict regulations, community-curated large-scale public datasets, pretrained models, and advanced data augmentation methods are the main factors for developing reliable systems to improve patient care. However, for the development of medical acoustic sensing systems, an emerging field of research, the community lacks large-scale publicly available data sets and pretrained models. To address the problem of limited data, we propose a conditional generative adversarial neural network-based augmentation method which is able to synthesize mel spectrograms from a learned data distribution of a source data set. In contrast to previously proposed fully convolutional models, the proposed model implements residual Squeeze and Excitation modules in the generator architecture. We show that our method outperforms all classical audio augmentation techniques and previously published generative methods in terms of generated sample quality and a performance improvement of 2.84% of Macro F1-Score for a classifier trained on the augmented data set, an enhancement of $1.14\%$ in relation to previous work. By analyzing the correlation of intermediate feature spaces, we show that the residual Squeeze and Excitation modules help the model to reduce redundancy in the latent features. Therefore, the proposed model advances the state-of-the-art in the augmentation of clinical audio data and improves the data bottleneck for the design of clinical acoustic sensing systems.