 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Neural Tangent Kernel from a Practical Perspective: Can it be trusted for Neural Architecture Search without training?
Paper and Code

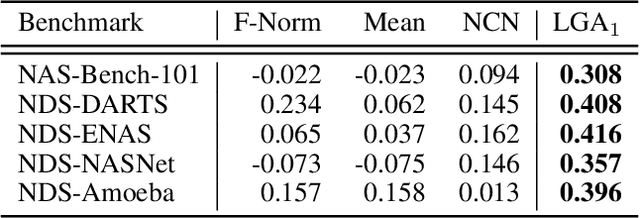
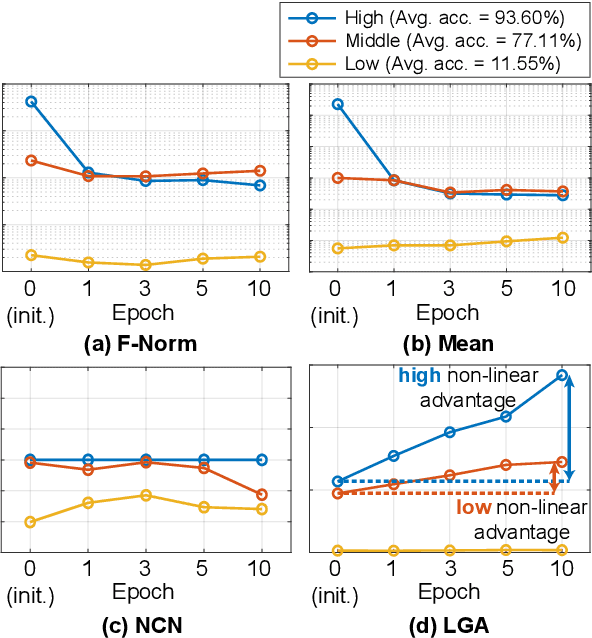
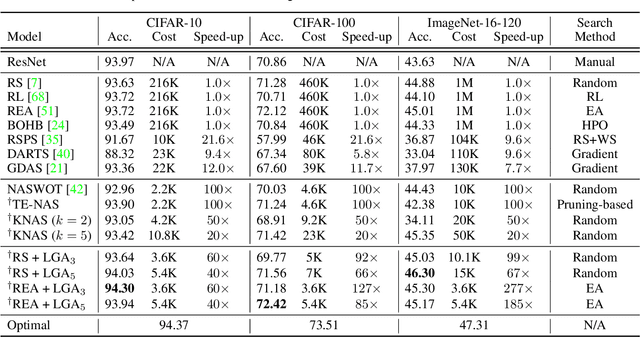
In Neural Architecture Search (NAS), reducing the cost of architecture evaluation remains one of the most crucial challenges. Among a plethora of efforts to bypass training of each candidate architecture to convergence for evaluation, the Neural Tangent Kernel (NTK) is emerging as a promising theoretical framework that can be utilized to estimate the performance of a neural architecture at initialization. In this work, we revisit several at-initialization metrics that can be derived from the NTK and reveal their key shortcomings. Then, through the empirical analysis of the time evolution of NTK, we deduce that modern neural architectures exhibit highly non-linear characteristics, making the NTK-based metrics incapable of reliably estimating the performance of an architecture without some amount of training. To take such non-linear characteristics into account, we introduce Label-Gradient Alignment (LGA), a novel NTK-based metric whose inherent formulation allows it to capture the large amount of non-linear advantage present in modern neural architectures. With minimal amount of training, LGA obtains a meaningful level of rank correlation with the post-training test accuracy of an architecture. Lastly, we demonstrate that LGA, complemented with few epochs of training, successfully guides existing search algorithms to achieve competitive search performances with significantly less search cost. The code is available at: https://github.com/nutellamok/DemystifyingNTK.