 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDATAREEL: Automated Data-Driven Video Story Generation with Animations
Apr 28, 2026Data videos are a powerful medium for visual data based storytelling, combining animated, chart-centric visualizations with synchronized narration. Widely used in journalism, education, and public communication, they help audiences understand complex data through clear and engaging visual explanations. Despite their growing impact, generating data-driven video stories remains challenging, as it requires careful coordination of visual encoding, temporal progression, and narration and substantial expertise in visualization design, animation, and video-editing tools. Recent advances in large language models offer new opportunities to automate this process; however, there is currently no benchmark for rigorously evaluating models on animated visualization-based video storytelling. To address this gap, we introduce DataReel, a benchmark for automated data-driven video story generation comprising 328 real-world stories. Each story pairs structured data, a chart visualization, and a narration transcript, enabling systematic evaluation of models' abilities to generate animated data video stories. We further propose a multi-agent framework that decomposes the task into planning, generation, and verification stages, mirroring key aspects of the human storytelling process. Experiments show that this multi-agent approach outperforms direct prompting baselines under both automatic and human evaluations, while revealing persistent challenges in coordinating animation, narration, and visual emphasis. We release DataReel at https://github.com/vis-nlp/DataReel.
Lost in Translation: Do LVLM Judges Generalize Across Languages?
Apr 21, 2026Automatic evaluators such as reward models play a central role in the alignment and evaluation of large vision-language models (LVLMs). Despite their growing importance, these evaluators are almost exclusively assessed on English-centric benchmarks, leaving open the question of how well these evaluators generalize across languages. To answer this question, we introduce MM-JudgeBench, the first large-scale benchmark for multilingual and multimodal judge model evaluation, which includes over 60K pairwise preference instances spanning 25 typologically diverse languages. MM-JudgeBench integrates two complementary subsets: a general vision-language preference evaluation subset extending VL-RewardBench, and a chart-centric visual-text reasoning subset derived from OpenCQA, enabling systematic analysis of reward models (i.e., LVLM judges) across diverse settings. We additionally release a multilingual training set derived from MM-RewardBench, disjoint from our evaluation data, to support domain adaptation. By evaluating 22 LVLMs (15 open-source, 7 proprietary), we uncover substantial cross-lingual performance variance in our proposed benchmark. Our analysis further shows that model size and architecture are poor predictors of multilingual robustness, and that even state-of-the-art LVLM judges exhibit inconsistent behavior across languages. Together, these findings expose fundamental limitations of current reward modeling and underscore the necessity of multilingual, multimodal benchmarks for developing reliable automated evaluators.
Aligning Text, Code, and Vision: A Multi-Objective Reinforcement Learning Framework for Text-to-Visualization
Jan 08, 2026Text-to-Visualization (Text2Vis) systems translate natural language queries over tabular data into concise answers and executable visualizations. While closed-source LLMs generate functional code, the resulting charts often lack semantic alignment and clarity, qualities that can only be assessed post-execution. Open-source models struggle even more, frequently producing non-executable or visually poor outputs. Although supervised fine-tuning can improve code executability, it fails to enhance overall visualization quality, as traditional SFT loss cannot capture post-execution feedback. To address this gap, we propose RL-Text2Vis, the first reinforcement learning framework for Text2Vis generation. Built on Group Relative Policy Optimization (GRPO), our method uses a novel multi-objective reward that jointly optimizes textual accuracy, code validity, and visualization quality using post-execution feedback. By training Qwen2.5 models (7B and 14B), RL-Text2Vis achieves a 22% relative improvement in chart quality over GPT-4o on the Text2Vis benchmark and boosts code execution success from 78% to 97% relative to its zero-shot baseline. Our models significantly outperform strong zero-shot and supervised baselines and also demonstrate robust generalization to out-of-domain datasets like VIS-Eval and NVBench. These results establish GRPO as an effective strategy for structured, multimodal reasoning in visualization generation. We release our code at https://github.com/vis-nlp/RL-Text2Vis.
Toward Generalized Detection of Synthetic Media: Limitations, Challenges, and the Path to Multimodal Solutions
Nov 14, 2025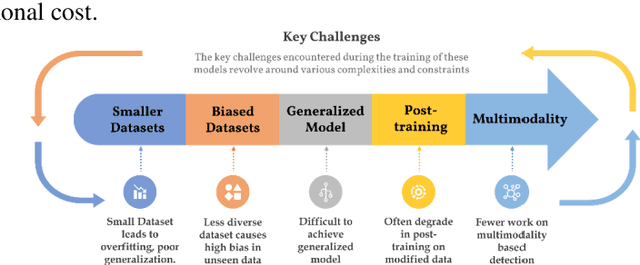
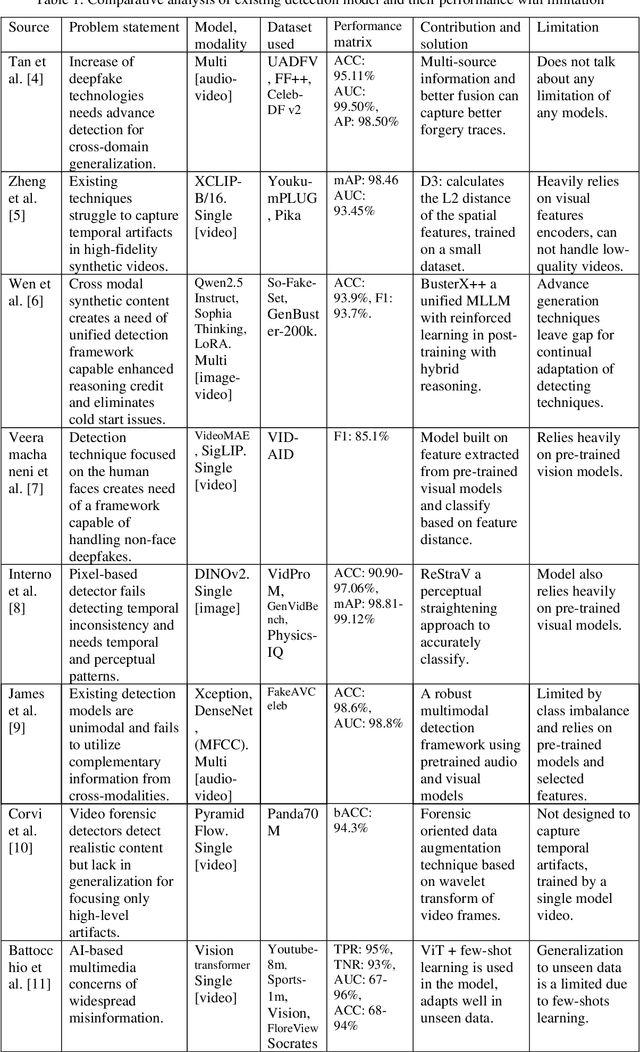
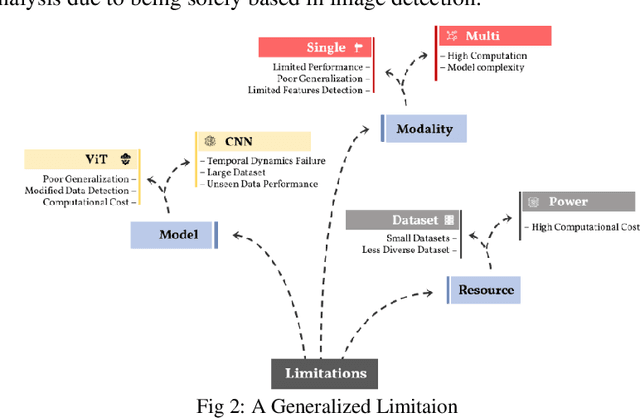
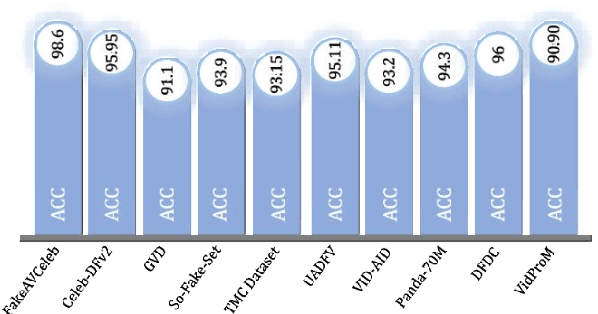
Artificial intelligence (AI) in media has advanced rapidly over the last decade. The introduction of Generative Adversarial Networks (GANs) improved the quality of photorealistic image generation. Diffusion models later brought a new era of generative media. These advances made it difficult to separate real and synthetic content. The rise of deepfakes demonstrated how these tools could be misused to spread misinformation, political conspiracies, privacy violations, and fraud. For this reason, many detection models have been developed. They often use deep learning methods such as Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). These models search for visual, spatial, or temporal anomalies. However, such approaches often fail to generalize across unseen data and struggle with content from different models. In addition, existing approaches are ineffective in multimodal data and highly modified content. This study reviews twenty-four recent works on AI-generated media detection. Each study was examined individually to identify its contributions and weaknesses, respectively. The review then summarizes the common limitations and key challenges faced by current approaches. Based on this analysis, a research direction is suggested with a focus on multimodal deep learning models. Such models have the potential to provide more robust and generalized detection. It offers future researchers a clear starting point for building stronger defenses against harmful synthetic media.
Quantum-Classical Hybrid Framework for Zero-Day Time-Push GNSS Spoofing Detection
Aug 25, 2025Global Navigation Satellite Systems (GNSS) are critical for Positioning, Navigation, and Timing (PNT) applications. However, GNSS are highly vulnerable to spoofing attacks, where adversaries transmit counterfeit signals to mislead receivers. Such attacks can lead to severe consequences, including misdirected navigation, compromised data integrity, and operational disruptions. Most existing spoofing detection methods depend on supervised learning techniques and struggle to detect novel, evolved, and unseen attacks. To overcome this limitation, we develop a zero-day spoofing detection method using a Hybrid Quantum-Classical Autoencoder (HQC-AE), trained solely on authentic GNSS signals without exposure to spoofed data. By leveraging features extracted during the tracking stage, our method enables proactive detection before PNT solutions are computed. We focus on spoofing detection in static GNSS receivers, which are particularly susceptible to time-push spoofing attacks, where attackers manipulate timing information to induce incorrect time computations at the receiver. We evaluate our model against different unseen time-push spoofing attack scenarios: simplistic, intermediate, and sophisticated. Our analysis demonstrates that the HQC-AE consistently outperforms its classical counterpart, traditional supervised learning-based models, and existing unsupervised learning-based methods in detecting zero-day, unseen GNSS time-push spoofing attacks, achieving an average detection accuracy of 97.71% with an average false negative rate of 0.62% (when an attack occurs but is not detected). For sophisticated spoofing attacks, the HQC-AE attains an accuracy of 98.23% with a false negative rate of 1.85%. These findings highlight the effectiveness of our method in proactively detecting zero-day GNSS time-push spoofing attacks across various stationary GNSS receiver platforms.
DashboardQA: Benchmarking Multimodal Agents for Question Answering on Interactive Dashboards
Aug 24, 2025Dashboards are powerful visualization tools for data-driven decision-making, integrating multiple interactive views that allow users to explore, filter, and navigate data. Unlike static charts, dashboards support rich interactivity, which is essential for uncovering insights in real-world analytical workflows. However, existing question-answering benchmarks for data visualizations largely overlook this interactivity, focusing instead on static charts. This limitation severely constrains their ability to evaluate the capabilities of modern multimodal agents designed for GUI-based reasoning. To address this gap, we introduce DashboardQA, the first benchmark explicitly designed to assess how vision-language GUI agents comprehend and interact with real-world dashboards. The benchmark includes 112 interactive dashboards from Tableau Public and 405 question-answer pairs with interactive dashboards spanning five categories: multiple-choice, factoid, hypothetical, multi-dashboard, and conversational. By assessing a variety of leading closed- and open-source GUI agents, our analysis reveals their key limitations, particularly in grounding dashboard elements, planning interaction trajectories, and performing reasoning. Our findings indicate that interactive dashboard reasoning is a challenging task overall for all the VLMs evaluated. Even the top-performing agents struggle; for instance, the best agent based on Gemini-Pro-2.5 achieves only 38.69% accuracy, while the OpenAI CUA agent reaches just 22.69%, demonstrating the benchmark's significant difficulty. We release DashboardQA at https://github.com/vis-nlp/DashboardQA
Vision-Based Localization and LLM-based Navigation for Indoor Environments
Aug 11, 2025



Indoor navigation remains a complex challenge due to the absence of reliable GPS signals and the architectural intricacies of large enclosed environments. This study presents an indoor localization and navigation approach that integrates vision-based localization with large language model (LLM)-based navigation. The localization system utilizes a ResNet-50 convolutional neural network fine-tuned through a two-stage process to identify the user's position using smartphone camera input. To complement localization, the navigation module employs an LLM, guided by a carefully crafted system prompt, to interpret preprocessed floor plan images and generate step-by-step directions. Experimental evaluation was conducted in a realistic office corridor with repetitive features and limited visibility to test localization robustness. The model achieved high confidence and an accuracy of 96% across all tested waypoints, even under constrained viewing conditions and short-duration queries. Navigation tests using ChatGPT on real building floor maps yielded an average instruction accuracy of 75%, with observed limitations in zero-shot reasoning and inference time. This research demonstrates the potential for scalable, infrastructure-free indoor navigation using off-the-shelf cameras and publicly available floor plans, particularly in resource-constrained settings like hospitals, airports, and educational institutions.
Grid2Guide: A* Enabled Small Language Model for Indoor Navigation
Aug 11, 2025



Reliable indoor navigation remains a significant challenge in complex environments, particularly where external positioning signals and dedicated infrastructures are unavailable. This research presents Grid2Guide, a hybrid navigation framework that combines the A* search algorithm with a Small Language Model (SLM) to generate clear, human-readable route instructions. The framework first conducts a binary occupancy matrix from a given indoor map. Using this matrix, the A* algorithm computes the optimal path between origin and destination, producing concise textual navigation steps. These steps are then transformed into natural language instructions by the SLM, enhancing interpretability for end users. Experimental evaluations across various indoor scenarios demonstrate the method's effectiveness in producing accurate and timely navigation guidance. The results validate the proposed approach as a lightweight, infrastructure-free solution for real-time indoor navigation support.
Evolution of ReID: From Early Methods to LLM Integration
Jun 16, 2025



Person re-identification (ReID) has evolved from handcrafted feature-based methods to deep learning approaches and, more recently, to models incorporating large language models (LLMs). Early methods struggled with variations in lighting, pose, and viewpoint, but deep learning addressed these issues by learning robust visual features. Building on this, LLMs now enable ReID systems to integrate semantic and contextual information through natural language. This survey traces that full evolution and offers one of the first comprehensive reviews of ReID approaches that leverage LLMs, where textual descriptions are used as privileged information to improve visual matching. A key contribution is the use of dynamic, identity-specific prompts generated by GPT-4o, which enhance the alignment between images and text in vision-language ReID systems. Experimental results show that these descriptions improve accuracy, especially in complex or ambiguous cases. To support further research, we release a large set of GPT-4o-generated descriptions for standard ReID datasets. By bridging computer vision and natural language processing, this survey offers a unified perspective on the field's development and outlines key future directions such as better prompt design, cross-modal transfer learning, and real-world adaptability.
Retrieval Augmented Generation-based Large Language Models for Bridging Transportation Cybersecurity Legal Knowledge Gaps
May 23, 2025As connected and automated transportation systems evolve, there is a growing need for federal and state authorities to revise existing laws and develop new statutes to address emerging cybersecurity and data privacy challenges. This study introduces a Retrieval-Augmented Generation (RAG) based Large Language Model (LLM) framework designed to support policymakers by extracting relevant legal content and generating accurate, inquiry-specific responses. The framework focuses on reducing hallucinations in LLMs by using a curated set of domain-specific questions to guide response generation. By incorporating retrieval mechanisms, the system enhances the factual grounding and specificity of its outputs. Our analysis shows that the proposed RAG-based LLM outperforms leading commercial LLMs across four evaluation metrics: AlignScore, ParaScore, BERTScore, and ROUGE, demonstrating its effectiveness in producing reliable and context-aware legal insights. This approach offers a scalable, AI-driven method for legislative analysis, supporting efforts to update legal frameworks in line with advancements in transportation technologies.