 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Native Low-Rank LLM Pretraining
Feb 12, 2026Foundation models have achieved remarkable success, yet their growing parameter counts pose significant computational and memory challenges. Low-rank factorization offers a promising route to reduce training and inference costs, but the community lacks a stable recipe for training models from scratch using exclusively low-rank weights while matching the performance of the dense model. We demonstrate that Large Language Models (LLMs) can be trained from scratch using exclusively low-rank factorized weights for all non-embedding matrices without auxiliary "full-rank" guidance required by prior methods. While native low-rank training often suffers from instability and loss spikes, we identify uncontrolled growth in the spectral norm (largest singular value) of the weight matrix update as the dominant factor. To address this, we introduce Spectron: Spectral renormalization with orthogonalization, which dynamically bounds the resultant weight updates based on the current spectral norms of the factors. Our method enables stable, end-to-end factorized training with negligible overhead. Finally, we establish compute-optimal scaling laws for natively low-rank transformers, demonstrating predictable power-law behavior and improved inference efficiency relative to dense models.
Heterogeneous Low-Bandwidth Pre-Training of LLMs
Jan 05, 2026Pre-training large language models (LLMs) increasingly requires distributed compute, yet bandwidth constraints make it difficult to scale beyond well-provisioned datacenters-especially when model parallelism forces frequent, large inter-device communications. We study whether SparseLoCo, a low-communication data parallel method based on infrequent synchronization and sparse pseudo-gradient exchange, can be combined with low-bandwidth pipeline model parallelism via activation and activation-gradient compression. We introduce a heterogeneous distributed training framework where some participants host full replicas on high-bandwidth interconnects, while resource-limited participants are grouped to jointly instantiate a replica using pipeline parallelism with subspace-projected inter-stage communication. To make the recently introduced subspace pipeline compression compatible with SparseLoCo, we study a number of adaptations. Across large-scale language modeling experiments (178M-1B parameters) on standard pretraining corpora, we find that activation compression composes with SparseLoCo at modest cost, while selective (heterogeneous) compression consistently improves the loss-communication tradeoff relative to compressing all replicas-especially at aggressive compression ratios. These results suggest a practical path to incorporating low-bandwidth model parallelism and heterogeneous participants into LLM pre-training.
PyLO: Towards Accessible Learned Optimizers in PyTorch
Jun 12, 2025Learned optimizers have been an active research topic over the past decade, with increasing progress toward practical, general-purpose optimizers that can serve as drop-in replacements for widely used methods like Adam. However, recent advances -- such as VeLO, which was meta-trained for 4000 TPU-months -- remain largely inaccessible to the broader community, in part due to their reliance on JAX and the absence of user-friendly packages for applying the optimizers after meta-training. To address this gap, we introduce PyLO, a PyTorch-based library that brings learned optimizers to the broader machine learning community through familiar, widely adopted workflows. Unlike prior work focused on synthetic or convex tasks, our emphasis is on applying learned optimization to real-world large-scale pre-training tasks. Our release includes a CUDA-accelerated version of the small_fc_lopt learned optimizer architecture from (Metz et al., 2022a), delivering substantial speedups -- from 39.36 to 205.59 samples/sec throughput for training ViT B/16 with batch size 32. PyLO also allows us to easily combine learned optimizers with existing optimization tools such as learning rate schedules and weight decay. When doing so, we find that learned optimizers can substantially benefit. Our code is available at https://github.com/Belilovsky-Lab/pylo
Beyond Cosine Decay: On the effectiveness of Infinite Learning Rate Schedule for Continual Pre-training
Mar 06, 2025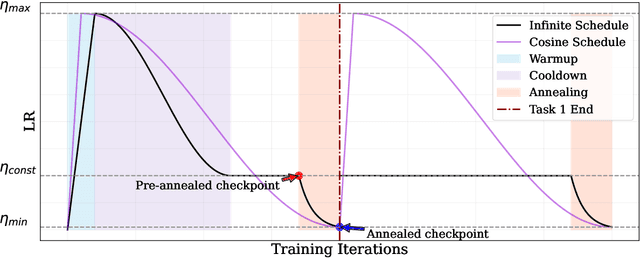

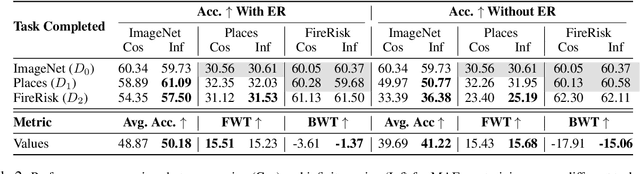
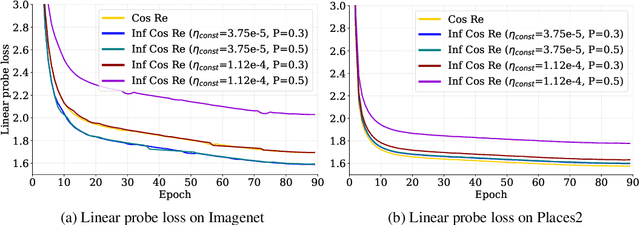
The ever-growing availability of unlabeled data presents both opportunities and challenges for training artificial intelligence systems. While self-supervised learning (SSL) has emerged as a powerful paradigm for extracting meaningful representations from vast amounts of unlabeled data, existing methods still struggle to adapt to the non-stationary, non-IID nature of real-world data streams without forgetting previously learned knowledge. Recent works have adopted a repeated cosine annealing schedule for large-scale continual pre-training; however, these schedules (1) inherently cause forgetting during the re-warming phase and (2) have not been systematically compared to existing continual SSL methods. In this work, we systematically compare the widely used cosine schedule with the recently proposed infinite learning rate schedule and empirically find the latter to be a more effective alternative. Our extensive empirical evaluation across diverse image and language datasets demonstrates that the infinite learning rate schedule consistently enhances continual pre-training performance compared to a repeated cosine decay without being restricted to a fixed iteration budget. For instance, in a small-scale MAE pre-training setup, it outperforms several strong baselines from the literature. We then scale up our experiments to larger MAE pre-training and autoregressive language model pre-training. Our results show that the infinite learning rate schedule remains effective at scale, surpassing repeated cosine decay for both MAE pre-training and zero-shot LM benchmarks.
Towards motion from video diffusion models
Nov 19, 2024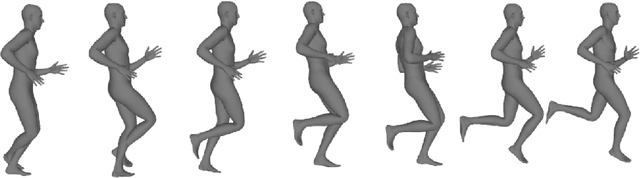
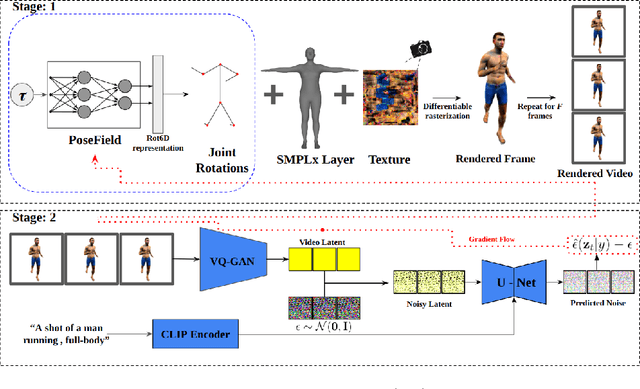
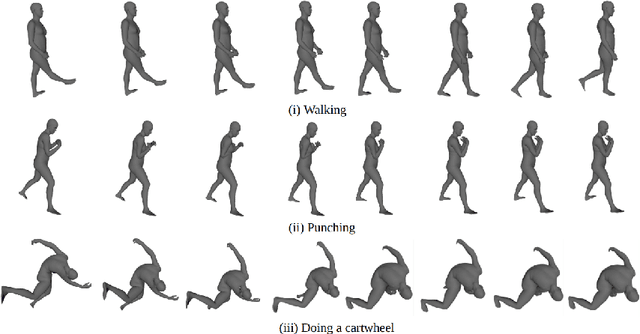
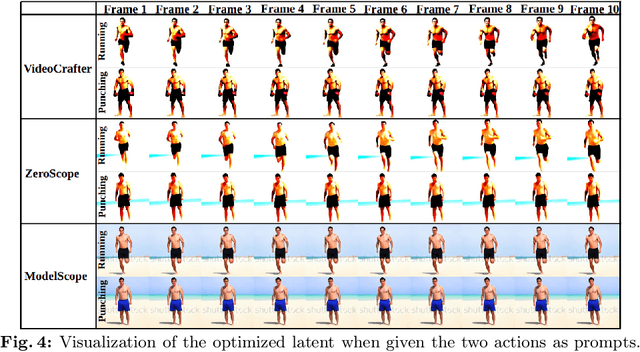
Text-conditioned video diffusion models have emerged as a powerful tool in the realm of video generation and editing. But their ability to capture the nuances of human movement remains under-explored. Indeed the ability of these models to faithfully model an array of text prompts can lead to a wide host of applications in human and character animation. In this work, we take initial steps to investigate whether these models can effectively guide the synthesis of realistic human body animations. Specifically we propose to synthesize human motion by deforming an SMPL-X body representation guided by Score distillation sampling (SDS) calculated using a video diffusion model. By analyzing the fidelity of the resulting animations, we gain insights into the extent to which we can obtain motion using publicly available text-to-video diffusion models using SDS. Our findings shed light on the potential and limitations of these models for generating diverse and plausible human motions, paving the way for further research in this exciting area.
FewShotNeRF: Meta-Learning-based Novel View Synthesis for Rapid Scene-Specific Adaptation
Aug 09, 2024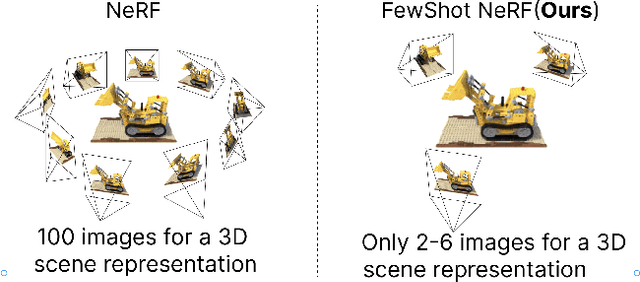
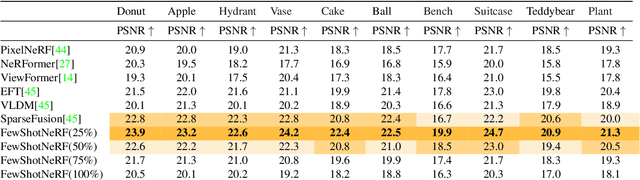
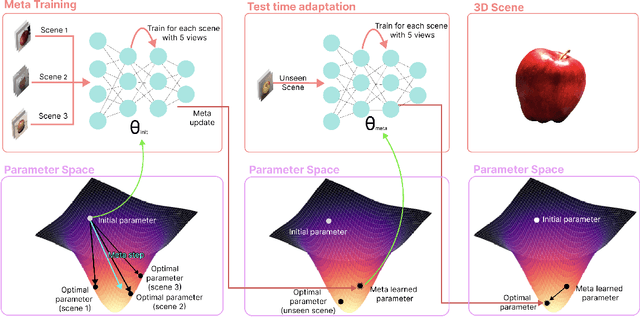
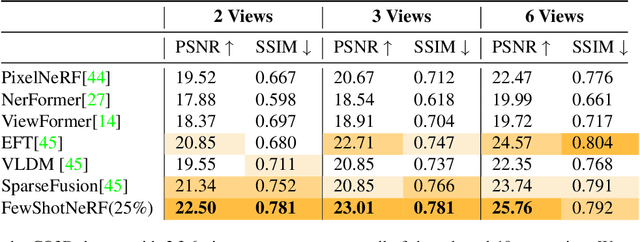
In this paper, we address the challenge of generating novel views of real-world objects with limited multi-view images through our proposed approach, FewShotNeRF. Our method utilizes meta-learning to acquire optimal initialization, facilitating rapid adaptation of a Neural Radiance Field (NeRF) to specific scenes. The focus of our meta-learning process is on capturing shared geometry and textures within a category, embedded in the weight initialization. This approach expedites the learning process of NeRFs and leverages recent advancements in positional encodings to reduce the time required for fitting a NeRF to a scene, thereby accelerating the inner loop optimization of meta-learning. Notably, our method enables meta-learning on a large number of 3D scenes to establish a robust 3D prior for various categories. Through extensive evaluations on the Common Objects in 3D open source dataset, we empirically demonstrate the efficacy and potential of meta-learning in generating high-quality novel views of objects.
Overcoming General Knowledge Loss with Selective Parameter Finetuning
Aug 23, 2023
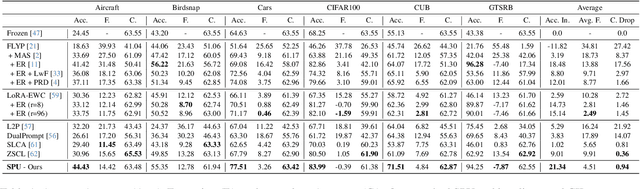
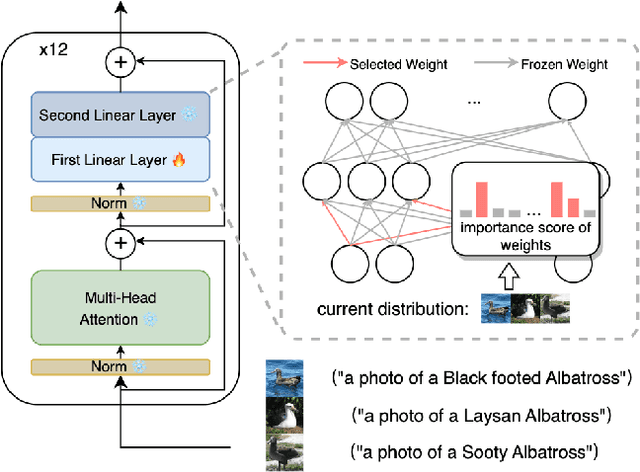

Foundation models encompass an extensive knowledge base and offer remarkable transferability. However, this knowledge becomes outdated or insufficient over time. The challenge lies in updating foundation models to accommodate novel information while retaining their original ability. In this paper, we present a novel approach to achieving continual model updates by effecting localized modifications to a small subset of parameters. Guided by insights gleaned from prior analyses of foundational models, we first localize a specific layer for model refinement and then introduce an importance scoring mechanism designed to update only the most crucial weights. Our method is exhaustively evaluated on foundational vision-language models, measuring its efficacy in both learning new information and preserving pre-established knowledge across a diverse spectrum of continual learning tasks, including Aircraft, Birdsnap CIFAR-100, CUB, Cars, and GTSRB. The results show that our method improves the existing continual learning methods by 0.5\% - 10\% on average, and reduces the loss of pre-trained knowledge from around 5\% to 0.97\%. Comprehensive ablation studies substantiate our method design, shedding light on the contributions of each component to controllably learning new knowledge and mitigating the forgetting of pre-trained knowledge.
Continual Zero-Shot Learning through Semantically Guided Generative Random Walks
Aug 23, 2023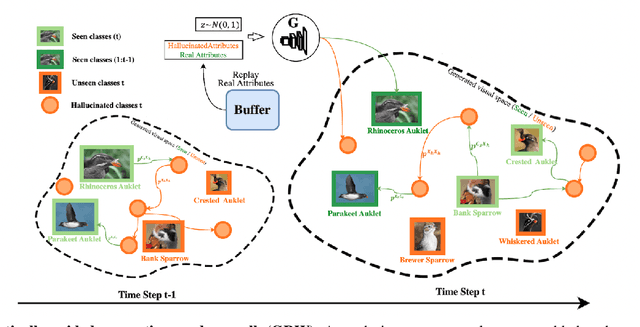
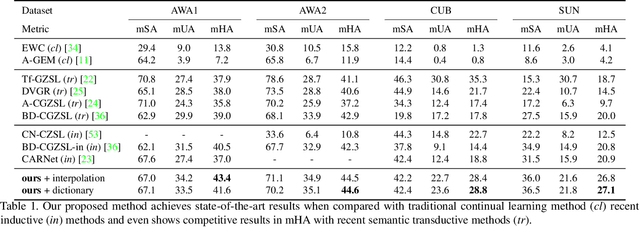
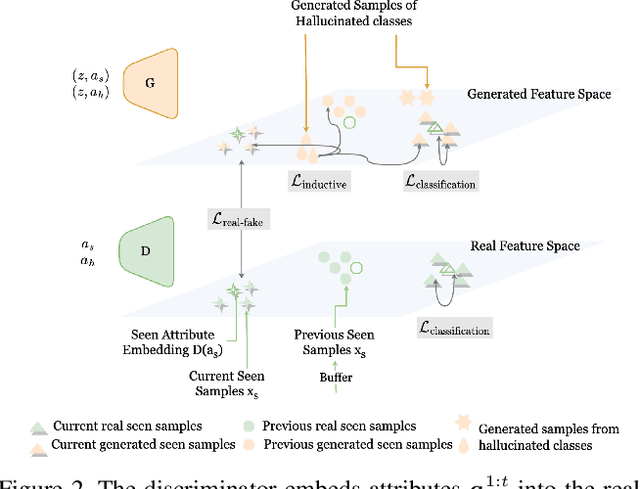
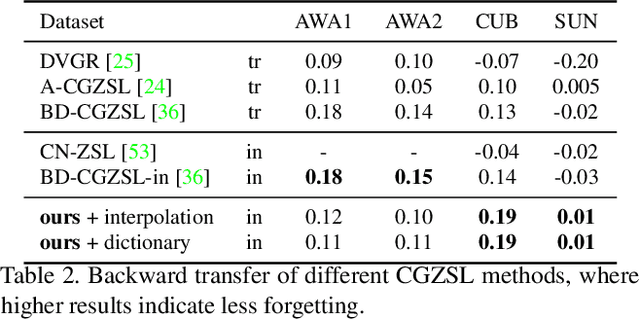
Learning novel concepts, remembering previous knowledge, and adapting it to future tasks occur simultaneously throughout a human's lifetime. To model such comprehensive abilities, continual zero-shot learning (CZSL) has recently been introduced. However, most existing methods overused unseen semantic information that may not be continually accessible in realistic settings. In this paper, we address the challenge of continual zero-shot learning where unseen information is not provided during training, by leveraging generative modeling. The heart of the generative-based methods is to learn quality representations from seen classes to improve the generative understanding of the unseen visual space. Motivated by this, we introduce generalization-bound tools and provide the first theoretical explanation for the benefits of generative modeling to CZSL tasks. Guided by the theoretical analysis, we then propose our learning algorithm that employs a novel semantically guided Generative Random Walk (GRW) loss. The GRW loss augments the training by continually encouraging the model to generate realistic and characterized samples to represent the unseen space. Our algorithm achieves state-of-the-art performance on AWA1, AWA2, CUB, and SUN datasets, surpassing existing CZSL methods by 3-7\%. The code has been made available here \url{https://github.com/wx-zhang/IGCZSL}
A Simple Baseline that Questions the Use of Pretrained-Models in Continual Learning
Oct 10, 2022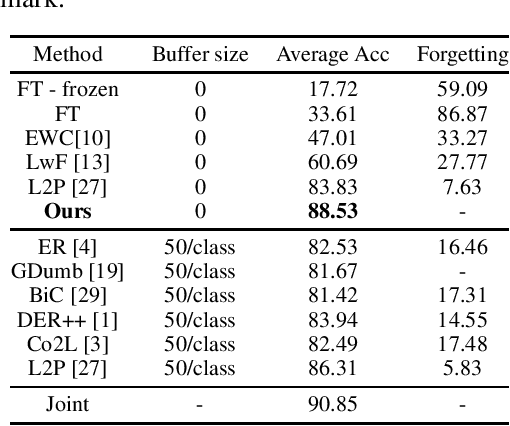
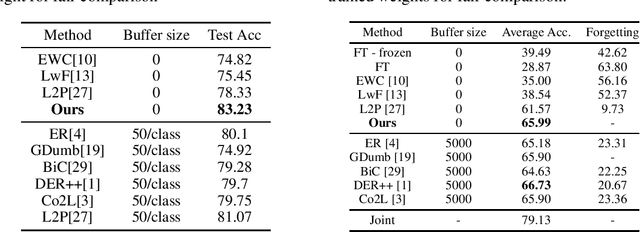
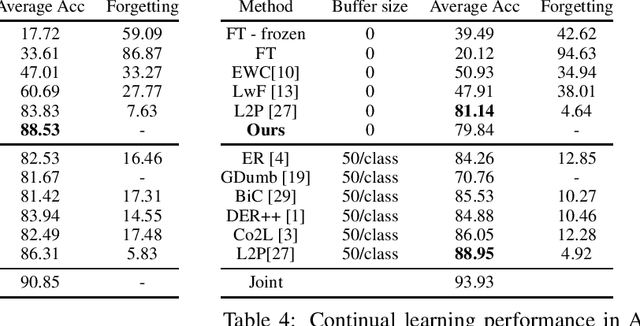
With the success of pretraining techniques in representation learning, a number of continual learning methods based on pretrained models have been proposed. Some of these methods design continual learning mechanisms on the pre-trained representations and only allow minimum updates or even no updates of the backbone models during the training of continual learning. In this paper, we question whether the complexity of these models is needed to achieve good performance by comparing them to a simple baseline that we designed. We argue that the pretrained feature extractor itself can be strong enough to achieve a competitive or even better continual learning performance on Split-CIFAR100 and CoRe 50 benchmarks. To validate this, we conduct a very simple baseline that 1) use the frozen pretrained model to extract image features for every class encountered during the continual learning stage and compute their corresponding mean features on training data, and 2) predict the class of the input based on the nearest neighbor distance between test samples and mean features of the classes; i.e., Nearest Mean Classifier (NMC). This baseline is single-headed, exemplar-free, and can be task-free (by updating the means continually). This baseline achieved 88.53% on 10-Split-CIFAR-100, surpassing most state-of-the-art continual learning methods that are all initialized using the same pretrained transformer model. We hope our baseline may encourage future progress in designing learning systems that can continually add quality to the learning representations even if they started from some pretrained weights.