 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards motion from video diffusion models
Paper and Code
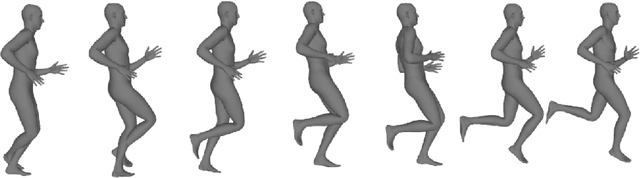
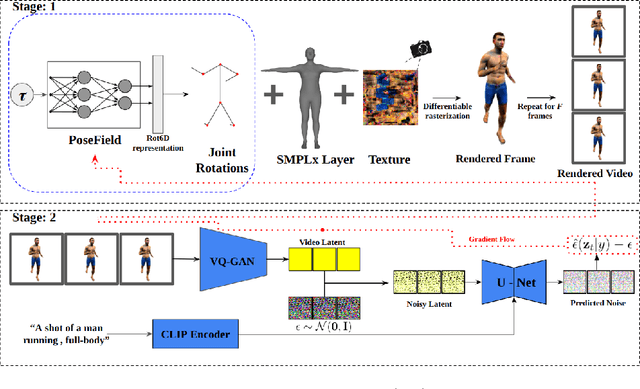
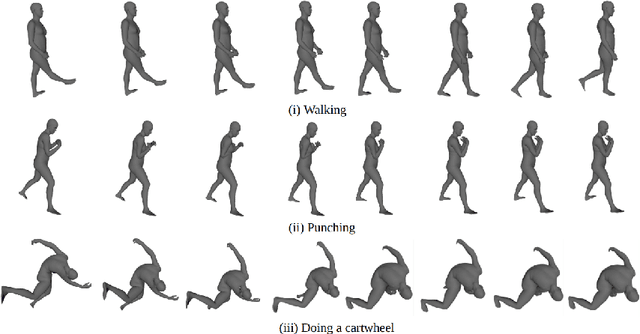
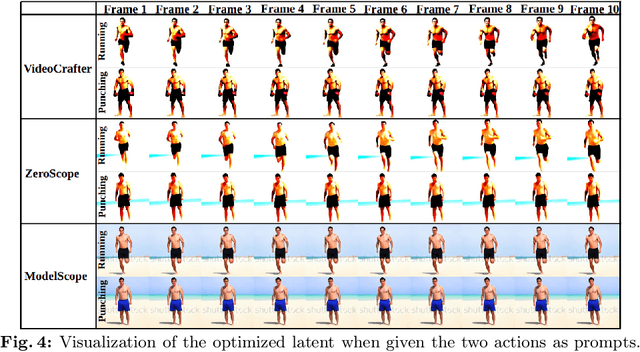
Text-conditioned video diffusion models have emerged as a powerful tool in the realm of video generation and editing. But their ability to capture the nuances of human movement remains under-explored. Indeed the ability of these models to faithfully model an array of text prompts can lead to a wide host of applications in human and character animation. In this work, we take initial steps to investigate whether these models can effectively guide the synthesis of realistic human body animations. Specifically we propose to synthesize human motion by deforming an SMPL-X body representation guided by Score distillation sampling (SDS) calculated using a video diffusion model. By analyzing the fidelity of the resulting animations, we gain insights into the extent to which we can obtain motion using publicly available text-to-video diffusion models using SDS. Our findings shed light on the potential and limitations of these models for generating diverse and plausible human motions, paving the way for further research in this exciting area.