 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards motion from video diffusion models
Nov 19, 2024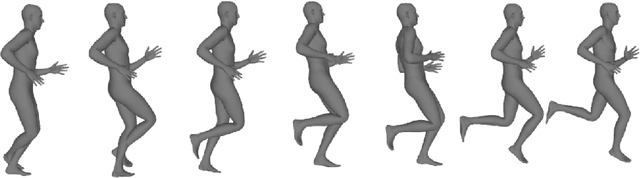
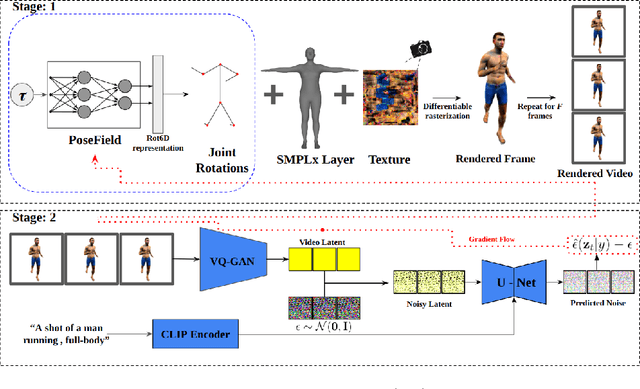
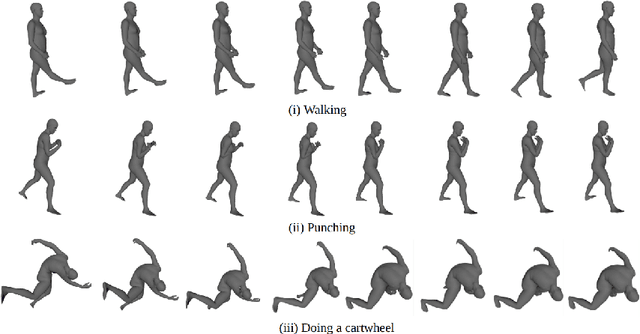
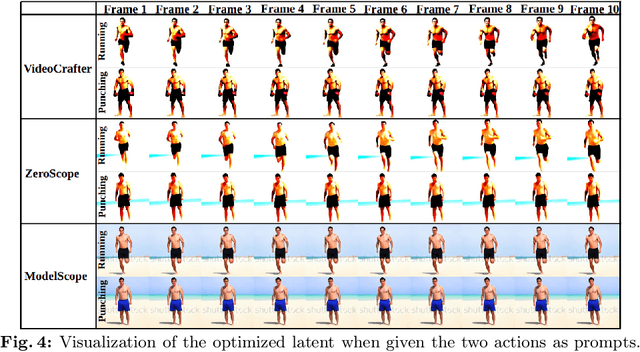
Text-conditioned video diffusion models have emerged as a powerful tool in the realm of video generation and editing. But their ability to capture the nuances of human movement remains under-explored. Indeed the ability of these models to faithfully model an array of text prompts can lead to a wide host of applications in human and character animation. In this work, we take initial steps to investigate whether these models can effectively guide the synthesis of realistic human body animations. Specifically we propose to synthesize human motion by deforming an SMPL-X body representation guided by Score distillation sampling (SDS) calculated using a video diffusion model. By analyzing the fidelity of the resulting animations, we gain insights into the extent to which we can obtain motion using publicly available text-to-video diffusion models using SDS. Our findings shed light on the potential and limitations of these models for generating diverse and plausible human motions, paving the way for further research in this exciting area.
Sketch-guided Cage-based 3D Gaussian Splatting Deformation
Nov 19, 20243D Gaussian Splatting (GS) is one of the most promising novel 3D representations that has received great interest in computer graphics and computer vision. While various systems have introduced editing capabilities for 3D GS, such as those guided by text prompts, fine-grained control over deformation remains an open challenge. In this work, we present a novel sketch-guided 3D GS deformation system that allows users to intuitively modify the geometry of a 3D GS model by drawing a silhouette sketch from a single viewpoint. Our approach introduces a new deformation method that combines cage-based deformations with a variant of Neural Jacobian Fields, enabling precise, fine-grained control. Additionally, it leverages large-scale 2D diffusion priors and ControlNet to ensure the generated deformations are semantically plausible. Through a series of experiments, we demonstrate the effectiveness of our method and showcase its ability to animate static 3D GS models as one of its key applications.
Temporally Consistent Object Editing in Videos using Extended Attention
Jun 01, 2024Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
DragD3D: Vertex-based Editing for Realistic Mesh Deformations using 2D Diffusion Priors
Oct 06, 2023Direct mesh editing and deformation are key components in the geometric modeling and animation pipeline. Direct mesh editing methods are typically framed as optimization problems combining user-specified vertex constraints with a regularizer that determines the position of the rest of the vertices. The choice of the regularizer is key to the realism and authenticity of the final result. Physics and geometry-based regularizers are not aware of the global context and semantics of the object, and the more recent deep learning priors are limited to a specific class of 3D object deformations. In this work, our main contribution is a local mesh editing method called DragD3D for global context-aware realistic deformation through direct manipulation of a few vertices. DragD3D is not restricted to any class of objects. It achieves this by combining the classic geometric ARAP (as rigid as possible) regularizer with 2D priors obtained from a large-scale diffusion model. Specifically, we render the objects from multiple viewpoints through a differentiable renderer and use the recently introduced DDS loss which scores the faithfulness of the rendered image to one from a diffusion model. DragD3D combines the approximate gradients of the DDS with gradients from the ARAP loss to modify the mesh vertices via neural Jacobian field, while also satisfying vertex constraints. We show that our deformations are realistic and aware of the global context of the objects, and provide better results than just using geometric regularizers.
Text to Mesh Without 3D Supervision Using Limit Subdivision
Mar 24, 2022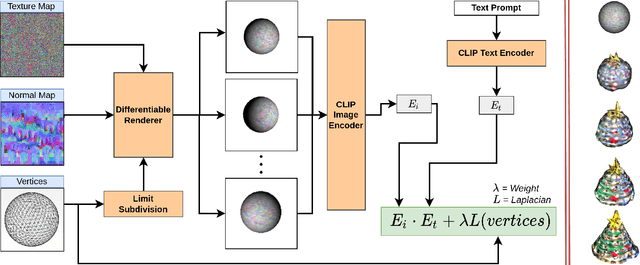

We present a technique for zero-shot generation of a 3D model using only a target text prompt. Without a generative model or any 3D supervision our method deforms a control shape of a limit subdivided surface along with a texture map and normal map to obtain a 3D model asset that matches the input text prompt and can be deployed into games or modeling applications. We rely only on a pre-trained CLIP model that compares the input text prompt with differentiably rendered images of our 3D model. While previous works have focused on stylization or required training of generative models we perform optimization on mesh parameters directly to generate shape and texture. To improve the quality of results we also introduce a set of techniques such as render augmentations, primitive selection, prompt augmentation that guide the mesh towards a suitable result.
CAMREP- Concordia Action and Motion Repository
Oct 06, 2017Action recognition, motion classification, gait analysis and synthesis are fundamental problems in a number of fields such as computer graphics, bio-mechanics and human computer interaction that generate a large body of research. This type of data is complex because it is inherently multidimensional and has multiple modalities such as video, motion capture data, accelerometer data, etc. While some of this data, such as monocular video are easy to acquire, others are much more difficult and expensive such as motion capture data or multi-view video. This creates a large barrier of entry in the research community for data driven research. We have embarked on creating a new large repository of motion and action data (CAMREP) consisting of several motion and action databases. What makes this database unique is that we use a variety of modalities, enabling multi-modal analysis. Presently, the size of datasets varies with some having a large number of subjects while others having smaller numbers. We have also acquired long capture sequences in a number of cases, making some datasets rather large.