 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Attention-Based Approach for Image-to-3D Texture Mapping
Sep 05, 2025



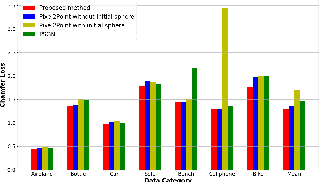
High-quality textures are critical for realistic 3D content creation, yet existing generative methods are slow, rely on UV maps, and often fail to remain faithful to a reference image. To address these challenges, we propose a transformer-based framework that predicts a 3D texture field directly from a single image and a mesh, eliminating the need for UV mapping and differentiable rendering, and enabling faster texture generation. Our method integrates a triplane representation with depth-based backprojection losses, enabling efficient training and faster inference. Once trained, it generates high-fidelity textures in a single forward pass, requiring only 0.2s per shape. Extensive qualitative, quantitative, and user preference evaluations demonstrate that our method outperforms state-of-the-art baselines on single-image texture reconstruction in terms of both fidelity to the input image and perceptual quality, highlighting its practicality for scalable, high-quality, and controllable 3D content creation.
Temporally Consistent Object Editing in Videos using Extended Attention
Jun 01, 2024Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
Fast-Image2Point: Towards Real-Time Point Cloud Reconstruction of a Single Image using 3D Supervision
Sep 20, 2022


A key question in the problem of 3D reconstruction is how to train a machine or a robot to model 3D objects. Many tasks like navigation in real-time systems such as autonomous vehicles directly depend on this problem. These systems usually have limited computational power. Despite considerable progress in 3D reconstruction systems in recent years, applying them to real-time systems such as navigation systems in autonomous vehicles is still challenging due to the high complexity and computational demand of the existing methods. This study addresses current problems in reconstructing objects displayed in a single-view image in a faster (real-time) fashion. To this end, a simple yet powerful deep neural framework is developed. The proposed framework consists of two components: the feature extractor module and the 3D generator module. We use point cloud representation for the output of our reconstruction module. The ShapeNet dataset is utilized to compare the method with the existing results in terms of computation time and accuracy. Simulations demonstrate the superior performance of the proposed method. Index Terms-Real-time 3D reconstruction, single-view reconstruction, supervised learning, deep neural network