 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-Image2Point: Towards Real-Time Point Cloud Reconstruction of a Single Image using 3D Supervision
Sep 20, 2022
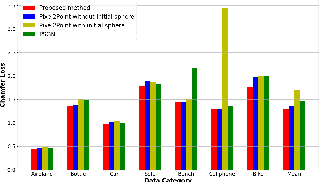


A key question in the problem of 3D reconstruction is how to train a machine or a robot to model 3D objects. Many tasks like navigation in real-time systems such as autonomous vehicles directly depend on this problem. These systems usually have limited computational power. Despite considerable progress in 3D reconstruction systems in recent years, applying them to real-time systems such as navigation systems in autonomous vehicles is still challenging due to the high complexity and computational demand of the existing methods. This study addresses current problems in reconstructing objects displayed in a single-view image in a faster (real-time) fashion. To this end, a simple yet powerful deep neural framework is developed. The proposed framework consists of two components: the feature extractor module and the 3D generator module. We use point cloud representation for the output of our reconstruction module. The ShapeNet dataset is utilized to compare the method with the existing results in terms of computation time and accuracy. Simulations demonstrate the superior performance of the proposed method. Index Terms-Real-time 3D reconstruction, single-view reconstruction, supervised learning, deep neural network