 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-guided Cage-based 3D Gaussian Splatting Deformation
Nov 19, 20243D Gaussian Splatting (GS) is one of the most promising novel 3D representations that has received great interest in computer graphics and computer vision. While various systems have introduced editing capabilities for 3D GS, such as those guided by text prompts, fine-grained control over deformation remains an open challenge. In this work, we present a novel sketch-guided 3D GS deformation system that allows users to intuitively modify the geometry of a 3D GS model by drawing a silhouette sketch from a single viewpoint. Our approach introduces a new deformation method that combines cage-based deformations with a variant of Neural Jacobian Fields, enabling precise, fine-grained control. Additionally, it leverages large-scale 2D diffusion priors and ControlNet to ensure the generated deformations are semantically plausible. Through a series of experiments, we demonstrate the effectiveness of our method and showcase its ability to animate static 3D GS models as one of its key applications.
DragD3D: Vertex-based Editing for Realistic Mesh Deformations using 2D Diffusion Priors
Oct 06, 2023Direct mesh editing and deformation are key components in the geometric modeling and animation pipeline. Direct mesh editing methods are typically framed as optimization problems combining user-specified vertex constraints with a regularizer that determines the position of the rest of the vertices. The choice of the regularizer is key to the realism and authenticity of the final result. Physics and geometry-based regularizers are not aware of the global context and semantics of the object, and the more recent deep learning priors are limited to a specific class of 3D object deformations. In this work, our main contribution is a local mesh editing method called DragD3D for global context-aware realistic deformation through direct manipulation of a few vertices. DragD3D is not restricted to any class of objects. It achieves this by combining the classic geometric ARAP (as rigid as possible) regularizer with 2D priors obtained from a large-scale diffusion model. Specifically, we render the objects from multiple viewpoints through a differentiable renderer and use the recently introduced DDS loss which scores the faithfulness of the rendered image to one from a diffusion model. DragD3D combines the approximate gradients of the DDS with gradients from the ARAP loss to modify the mesh vertices via neural Jacobian field, while also satisfying vertex constraints. We show that our deformations are realistic and aware of the global context of the objects, and provide better results than just using geometric regularizers.
Text to Mesh Without 3D Supervision Using Limit Subdivision
Mar 24, 2022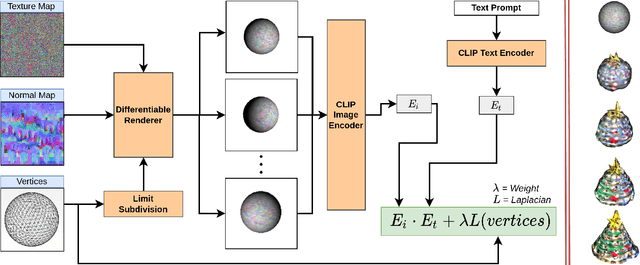

We present a technique for zero-shot generation of a 3D model using only a target text prompt. Without a generative model or any 3D supervision our method deforms a control shape of a limit subdivided surface along with a texture map and normal map to obtain a 3D model asset that matches the input text prompt and can be deployed into games or modeling applications. We rely only on a pre-trained CLIP model that compares the input text prompt with differentiably rendered images of our 3D model. While previous works have focused on stylization or required training of generative models we perform optimization on mesh parameters directly to generate shape and texture. To improve the quality of results we also introduce a set of techniques such as render augmentations, primitive selection, prompt augmentation that guide the mesh towards a suitable result.