 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText to Mesh Without 3D Supervision Using Limit Subdivision
Paper and Code
Mar 24, 2022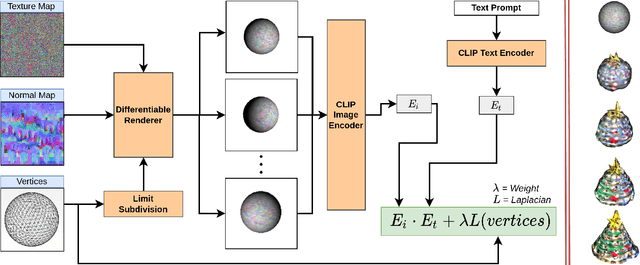

We present a technique for zero-shot generation of a 3D model using only a target text prompt. Without a generative model or any 3D supervision our method deforms a control shape of a limit subdivided surface along with a texture map and normal map to obtain a 3D model asset that matches the input text prompt and can be deployed into games or modeling applications. We rely only on a pre-trained CLIP model that compares the input text prompt with differentiably rendered images of our 3D model. While previous works have focused on stylization or required training of generative models we perform optimization on mesh parameters directly to generate shape and texture. To improve the quality of results we also introduce a set of techniques such as render augmentations, primitive selection, prompt augmentation that guide the mesh towards a suitable result.