 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Cosine Decay: On the effectiveness of Infinite Learning Rate Schedule for Continual Pre-training
Mar 06, 2025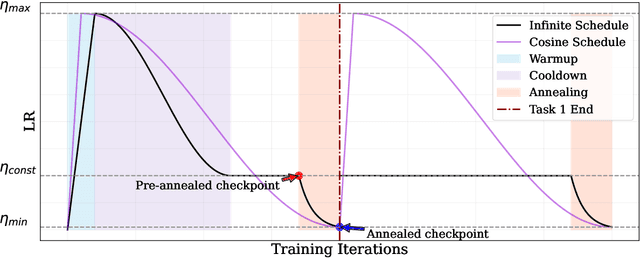

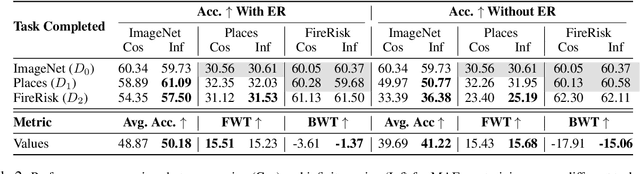
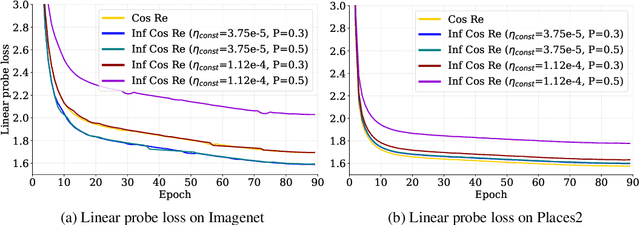
The ever-growing availability of unlabeled data presents both opportunities and challenges for training artificial intelligence systems. While self-supervised learning (SSL) has emerged as a powerful paradigm for extracting meaningful representations from vast amounts of unlabeled data, existing methods still struggle to adapt to the non-stationary, non-IID nature of real-world data streams without forgetting previously learned knowledge. Recent works have adopted a repeated cosine annealing schedule for large-scale continual pre-training; however, these schedules (1) inherently cause forgetting during the re-warming phase and (2) have not been systematically compared to existing continual SSL methods. In this work, we systematically compare the widely used cosine schedule with the recently proposed infinite learning rate schedule and empirically find the latter to be a more effective alternative. Our extensive empirical evaluation across diverse image and language datasets demonstrates that the infinite learning rate schedule consistently enhances continual pre-training performance compared to a repeated cosine decay without being restricted to a fixed iteration budget. For instance, in a small-scale MAE pre-training setup, it outperforms several strong baselines from the literature. We then scale up our experiments to larger MAE pre-training and autoregressive language model pre-training. Our results show that the infinite learning rate schedule remains effective at scale, surpassing repeated cosine decay for both MAE pre-training and zero-shot LM benchmarks.
Channel-Selective Normalization for Label-Shift Robust Test-Time Adaptation
Feb 07, 2024



Deep neural networks have useful applications in many different tasks, however their performance can be severely affected by changes in the data distribution. For example, in the biomedical field, their performance can be affected by changes in the data (different machines, populations) between training and test datasets. To ensure robustness and generalization to real-world scenarios, test-time adaptation has been recently studied as an approach to adjust models to a new data distribution during inference. Test-time batch normalization is a simple and popular method that achieved compelling performance on domain shift benchmarks. It is implemented by recalculating batch normalization statistics on test batches. Prior work has focused on analysis with test data that has the same label distribution as the training data. However, in many practical applications this technique is vulnerable to label distribution shifts, sometimes producing catastrophic failure. This presents a risk in applying test time adaptation methods in deployment. We propose to tackle this challenge by only selectively adapting channels in a deep network, minimizing drastic adaptation that is sensitive to label shifts. Our selection scheme is based on two principles that we empirically motivate: (1) later layers of networks are more sensitive to label shift (2) individual features can be sensitive to specific classes. We apply the proposed technique to three classification tasks, including CIFAR10-C, Imagenet-C, and diagnosis of fatty liver, where we explore both covariate and label distribution shifts. We find that our method allows to bring the benefits of TTA while significantly reducing the risk of failure common in other methods, while being robust to choice in hyperparameters.