 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline that Questions the Use of Pretrained-Models in Continual Learning
Paper and Code
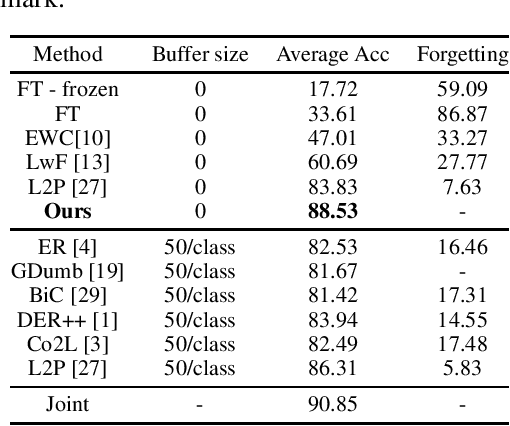
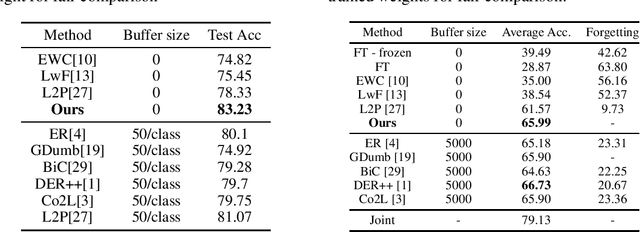
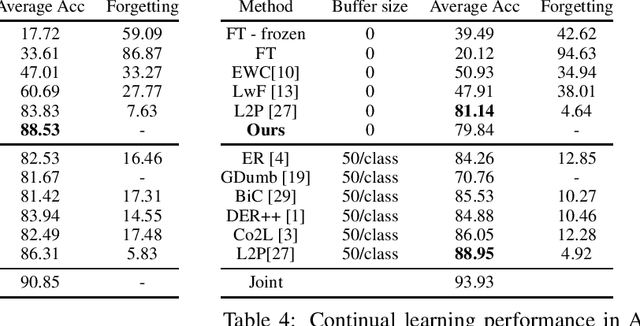
With the success of pretraining techniques in representation learning, a number of continual learning methods based on pretrained models have been proposed. Some of these methods design continual learning mechanisms on the pre-trained representations and only allow minimum updates or even no updates of the backbone models during the training of continual learning. In this paper, we question whether the complexity of these models is needed to achieve good performance by comparing them to a simple baseline that we designed. We argue that the pretrained feature extractor itself can be strong enough to achieve a competitive or even better continual learning performance on Split-CIFAR100 and CoRe 50 benchmarks. To validate this, we conduct a very simple baseline that 1) use the frozen pretrained model to extract image features for every class encountered during the continual learning stage and compute their corresponding mean features on training data, and 2) predict the class of the input based on the nearest neighbor distance between test samples and mean features of the classes; i.e., Nearest Mean Classifier (NMC). This baseline is single-headed, exemplar-free, and can be task-free (by updating the means continually). This baseline achieved 88.53% on 10-Split-CIFAR-100, surpassing most state-of-the-art continual learning methods that are all initialized using the same pretrained transformer model. We hope our baseline may encourage future progress in designing learning systems that can continually add quality to the learning representations even if they started from some pretrained weights.