 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NaijaVoices Dataset: Cultivating Large-Scale, High-Quality, Culturally-Rich Speech Data for African Languages
May 26, 2025The development of high-performing, robust, and reliable speech technologies depends on large, high-quality datasets. However, African languages -- including our focus, Igbo, Hausa, and Yoruba -- remain under-represented due to insufficient data. Popular voice-enabled technologies do not support any of the 2000+ African languages, limiting accessibility for circa one billion people. While previous dataset efforts exist for the target languages, they lack the scale and diversity needed for robust speech models. To bridge this gap, we introduce the NaijaVoices dataset, a 1,800-hour speech-text dataset with 5,000+ speakers. We outline our unique data collection approach, analyze its acoustic diversity, and demonstrate its impact through finetuning experiments on automatic speech recognition, averagely achieving 75.86% (Whisper), 52.06% (MMS), and 42.33% (XLSR) WER improvements. These results highlight NaijaVoices' potential to advance multilingual speech processing for African languages.
An Exhaustive Evaluation of TTS- and VC-based Data Augmentation for ASR
Mar 11, 2025



Augmenting the training data of automatic speech recognition (ASR) systems with synthetic data generated by text-to-speech (TTS) or voice conversion (VC) has gained popularity in recent years. Several works have demonstrated improvements in ASR performance using this augmentation approach. However, because of the lower diversity of synthetic speech, naively combining synthetic and real data often does not yield the best results. In this work, we leverage recently proposed flow-based TTS/VC models allowing greater speech diversity, and assess the respective impact of augmenting various speech attributes on the word error rate (WER) achieved by several ASR models. Pitch augmentation and VC-based speaker augmentation are found to be ineffective in our setup. Jointly augmenting all other attributes reduces the WER of a Conformer-Transducer model by 11\% relative on Common Voice and by up to 35\% relative on LibriSpeech compared to training on real data only.
Performant ASR Models for Medical Entities in Accented Speech
Jun 18, 2024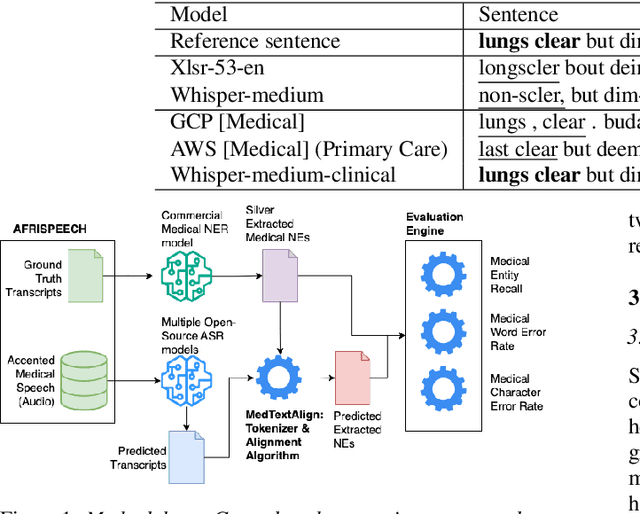



Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
1000 African Voices: Advancing inclusive multi-speaker multi-accent speech synthesis
Jun 17, 2024Recent advances in speech synthesis have enabled many useful applications like audio directions in Google Maps, screen readers, and automated content generation on platforms like TikTok. However, these systems are mostly dominated by voices sourced from data-rich geographies with personas representative of their source data. Although 3000 of the world's languages are domiciled in Africa, African voices and personas are under-represented in these systems. As speech synthesis becomes increasingly democratized, it is desirable to increase the representation of African English accents. We present Afro-TTS, the first pan-African accented English speech synthesis system able to generate speech in 86 African accents, with 1000 personas representing the rich phonological diversity across the continent for downstream application in Education, Public Health, and Automated Content Creation. Speaker interpolation retains naturalness and accentedness, enabling the creation of new voices.
Stochastic Pitch Prediction Improves the Diversity and Naturalness of Speech in Glow-TTS
May 28, 2023Flow-based generative models are widely used in text-to-speech (TTS) systems to learn the distribution of audio features (e.g., Mel-spectrograms) given the input tokens and to sample from this distribution to generate diverse utterances. However, in the zero-shot multi-speaker TTS scenario, the generated utterances lack diversity and naturalness. In this paper, we propose to improve the diversity of utterances by explicitly learning the distribution of fundamental frequency sequences (pitch contours) of each speaker during training using a stochastic flow-based pitch predictor, then conditioning the model on generated pitch contours during inference. The experimental results demonstrate that the proposed method yields a significant improvement in the naturalness and diversity of speech generated by a Glow-TTS model that uses explicit stochastic pitch prediction, over a Glow-TTS baseline and an improved Glow-TTS model that uses a stochastic duration predictor.
Can we use Common Voice to train a Multi-Speaker TTS system?
Oct 12, 2022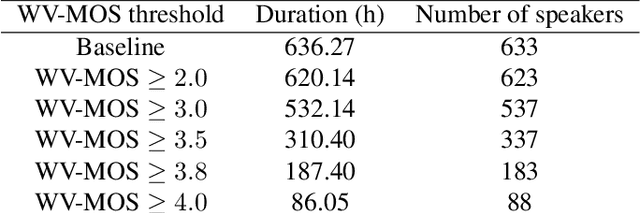
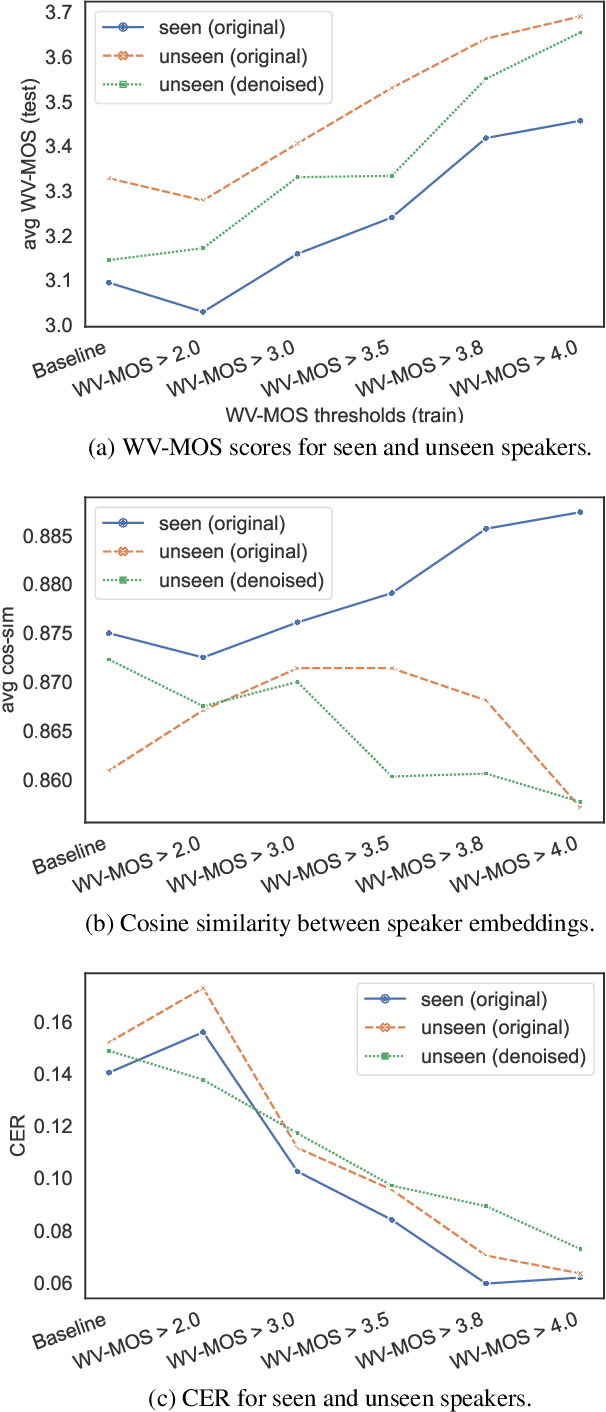
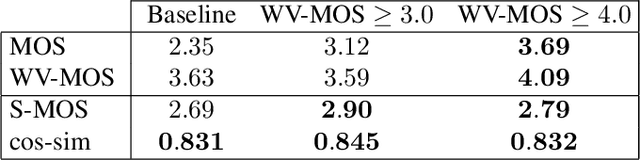
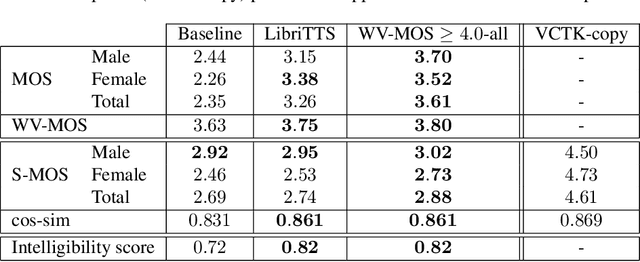
Training of multi-speaker text-to-speech (TTS) systems relies on curated datasets based on high-quality recordings or audiobooks. Such datasets often lack speaker diversity and are expensive to collect. As an alternative, recent studies have leveraged the availability of large, crowdsourced automatic speech recognition (ASR) datasets. A major problem with such datasets is the presence of noisy and/or distorted samples, which degrade TTS quality. In this paper, we propose to automatically select high-quality training samples using a non-intrusive mean opinion score (MOS) estimator, WV-MOS. We show the viability of this approach for training a multi-speaker GlowTTS model on the Common Voice English dataset. Our approach improves the overall quality of generated utterances by 1.26 MOS point with respect to training on all the samples and by 0.35 MOS point with respect to training on the LibriTTS dataset. This opens the door to automatic TTS dataset curation for a wider range of languages.