 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exhaustive Evaluation of TTS- and VC-based Data Augmentation for ASR
Mar 11, 2025



Augmenting the training data of automatic speech recognition (ASR) systems with synthetic data generated by text-to-speech (TTS) or voice conversion (VC) has gained popularity in recent years. Several works have demonstrated improvements in ASR performance using this augmentation approach. However, because of the lower diversity of synthetic speech, naively combining synthetic and real data often does not yield the best results. In this work, we leverage recently proposed flow-based TTS/VC models allowing greater speech diversity, and assess the respective impact of augmenting various speech attributes on the word error rate (WER) achieved by several ASR models. Pitch augmentation and VC-based speaker augmentation are found to be ineffective in our setup. Jointly augmenting all other attributes reduces the WER of a Conformer-Transducer model by 11\% relative on Common Voice and by up to 35\% relative on LibriSpeech compared to training on real data only.
Stochastic Pitch Prediction Improves the Diversity and Naturalness of Speech in Glow-TTS
May 28, 2023Flow-based generative models are widely used in text-to-speech (TTS) systems to learn the distribution of audio features (e.g., Mel-spectrograms) given the input tokens and to sample from this distribution to generate diverse utterances. However, in the zero-shot multi-speaker TTS scenario, the generated utterances lack diversity and naturalness. In this paper, we propose to improve the diversity of utterances by explicitly learning the distribution of fundamental frequency sequences (pitch contours) of each speaker during training using a stochastic flow-based pitch predictor, then conditioning the model on generated pitch contours during inference. The experimental results demonstrate that the proposed method yields a significant improvement in the naturalness and diversity of speech generated by a Glow-TTS model that uses explicit stochastic pitch prediction, over a Glow-TTS baseline and an improved Glow-TTS model that uses a stochastic duration predictor.
Can we use Common Voice to train a Multi-Speaker TTS system?
Oct 12, 2022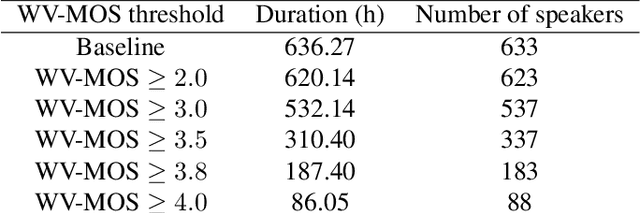
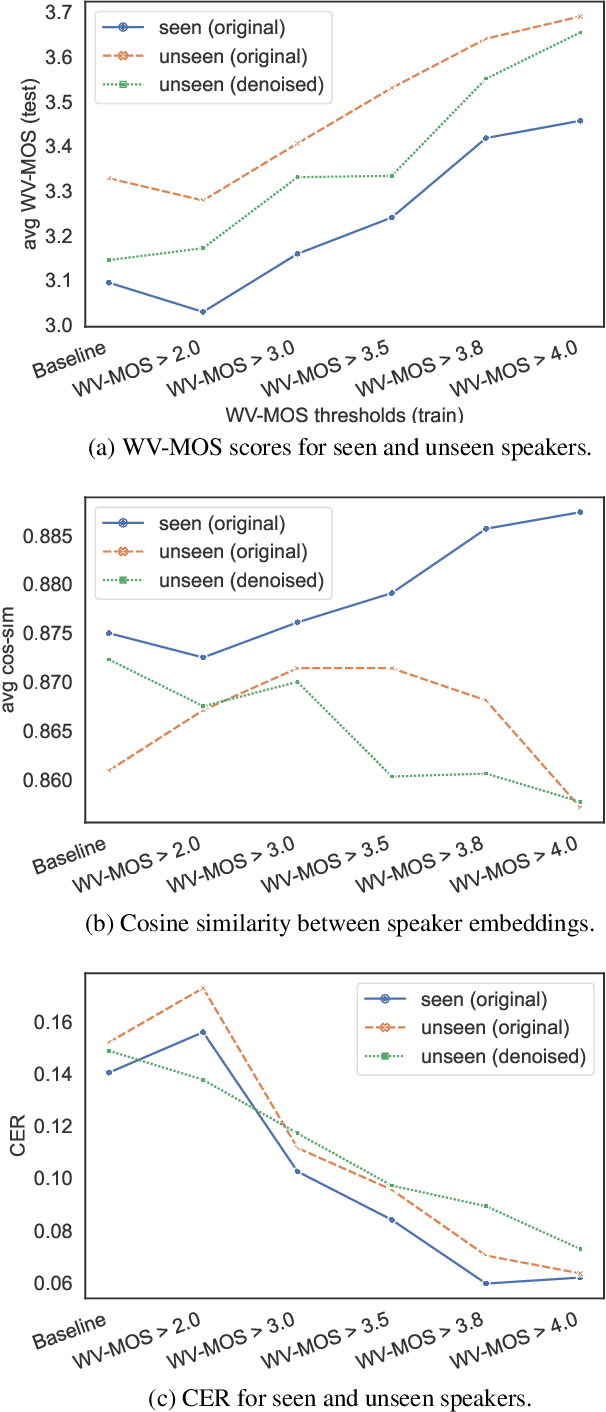
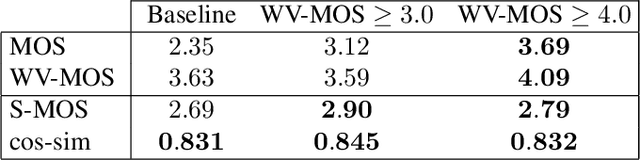
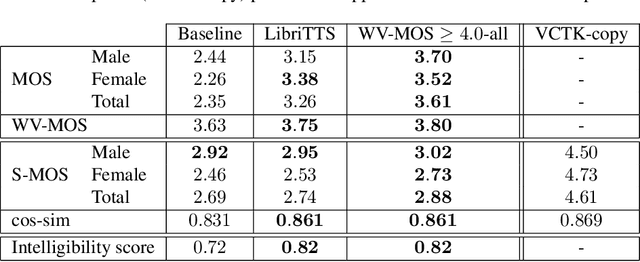
Training of multi-speaker text-to-speech (TTS) systems relies on curated datasets based on high-quality recordings or audiobooks. Such datasets often lack speaker diversity and are expensive to collect. As an alternative, recent studies have leveraged the availability of large, crowdsourced automatic speech recognition (ASR) datasets. A major problem with such datasets is the presence of noisy and/or distorted samples, which degrade TTS quality. In this paper, we propose to automatically select high-quality training samples using a non-intrusive mean opinion score (MOS) estimator, WV-MOS. We show the viability of this approach for training a multi-speaker GlowTTS model on the Common Voice English dataset. Our approach improves the overall quality of generated utterances by 1.26 MOS point with respect to training on all the samples and by 0.35 MOS point with respect to training on the LibriTTS dataset. This opens the door to automatic TTS dataset curation for a wider range of languages.