 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and the Future of Work in Africa White Paper
Nov 15, 2024
This white paper is the output of a multidisciplinary workshop in Nairobi (Nov 2023). Led by a cross-organisational team including Microsoft Research, NEPAD, Lelapa AI, and University of Oxford. The workshop brought together diverse thought-leaders from various sectors and backgrounds to discuss the implications of Generative AI for the future of work in Africa. Discussions centred around four key themes: Macroeconomic Impacts; Jobs, Skills and Labour Markets; Workers' Perspectives and Africa-Centris AI Platforms. The white paper provides an overview of the current state and trends of generative AI and its applications in different domains, as well as the challenges and risks associated with its adoption and regulation. It represents a diverse set of perspectives to create a set of insights and recommendations which aim to encourage debate and collaborative action towards creating a dignified future of work for everyone across Africa.
1000 African Voices: Advancing inclusive multi-speaker multi-accent speech synthesis
Jun 17, 2024



Recent advances in speech synthesis have enabled many useful applications like audio directions in Google Maps, screen readers, and automated content generation on platforms like TikTok. However, these systems are mostly dominated by voices sourced from data-rich geographies with personas representative of their source data. Although 3000 of the world's languages are domiciled in Africa, African voices and personas are under-represented in these systems. As speech synthesis becomes increasingly democratized, it is desirable to increase the representation of African English accents. We present Afro-TTS, the first pan-African accented English speech synthesis system able to generate speech in 86 African accents, with 1000 personas representing the rich phonological diversity across the continent for downstream application in Education, Public Health, and Automated Content Creation. Speaker interpolation retains naturalness and accentedness, enabling the creation of new voices.
Prompting Towards Alleviating Code-Switched Data Scarcity in Under-Resourced Languages with GPT as a Pivot
Apr 26, 2024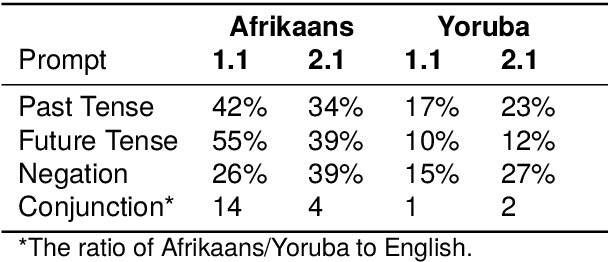
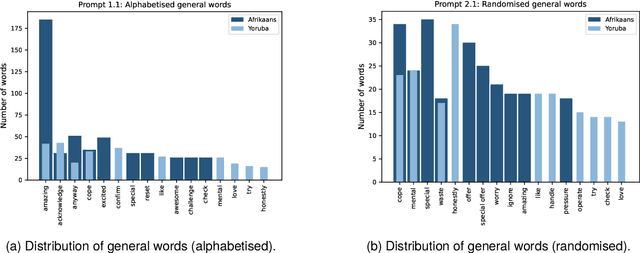
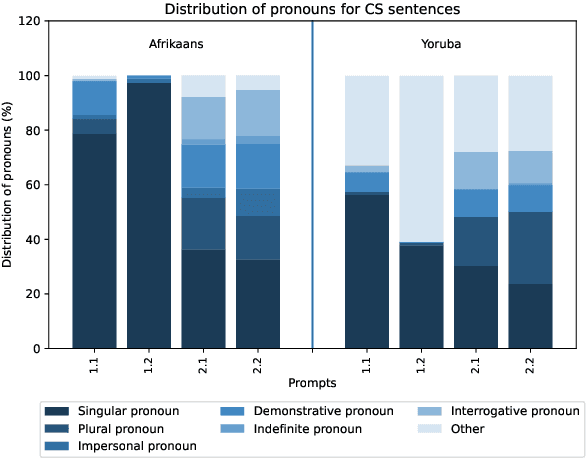
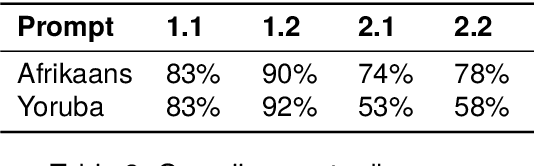
Many multilingual communities, including numerous in Africa, frequently engage in code-switching during conversations. This behaviour stresses the need for natural language processing technologies adept at processing code-switched text. However, data scarcity, particularly in African languages, poses a significant challenge, as many are low-resourced and under-represented. In this study, we prompted GPT 3.5 to generate Afrikaans--English and Yoruba--English code-switched sentences, enhancing diversity using topic-keyword pairs, linguistic guidelines, and few-shot examples. Our findings indicate that the quality of generated sentences for languages using non-Latin scripts, like Yoruba, is considerably lower when compared with the high Afrikaans-English success rate. There is therefore a notable opportunity to refine prompting guidelines to yield sentences suitable for the fine-tuning of language models. We propose a framework for augmenting the diversity of synthetically generated code-switched data using GPT and propose leveraging this technology to mitigate data scarcity in low-resourced languages, underscoring the essential role of native speakers in this process.
YFACC: A Yorùbá speech-image dataset for cross-lingual keyword localisation through visual grounding
Oct 12, 2022

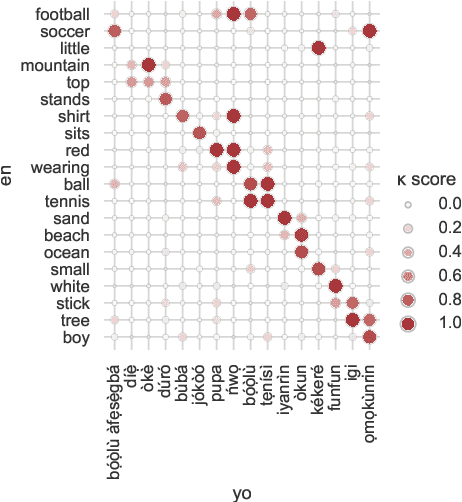

Visually grounded speech (VGS) models are trained on images paired with unlabelled spoken captions. Such models could be used to build speech systems in settings where it is impossible to get labelled data, e.g. for documenting unwritten languages. However, most VGS studies are in English or other high-resource languages. This paper attempts to address this shortcoming. We collect and release a new single-speaker dataset of audio captions for 6k Flickr images in Yor\`ub\'a -- a real low-resource language spoken in Nigeria. We train an attention-based VGS model where images are automatically tagged with English visual labels and paired with Yor\`ub\'a utterances. This enables cross-lingual keyword localisation: a written English query is detected and located in Yor\`ub\'a speech. To quantify the effect of the smaller dataset, we compare to English systems trained on similar and more data. We hope that this new dataset will stimulate research in the use of VGS models for real low-resource languages.
Keyword localisation in untranscribed speech using visually grounded speech models
Feb 02, 2022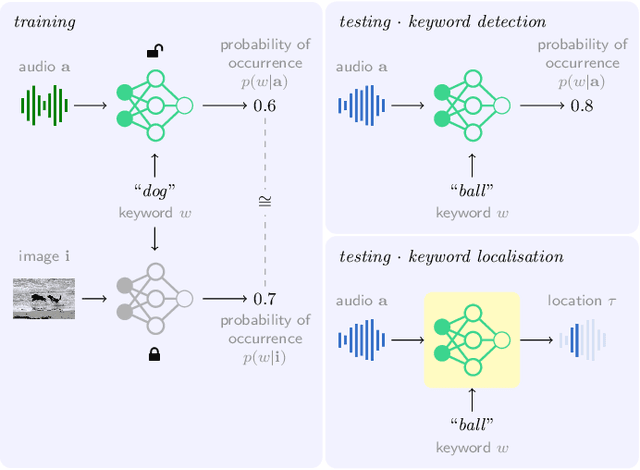
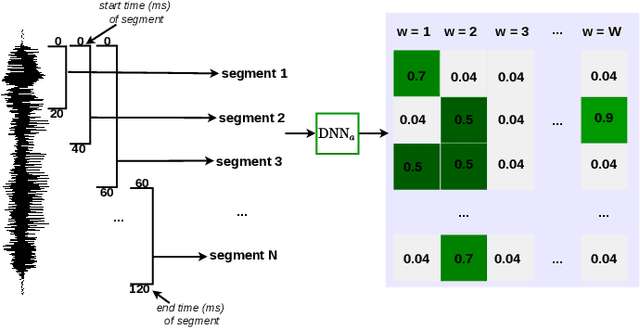
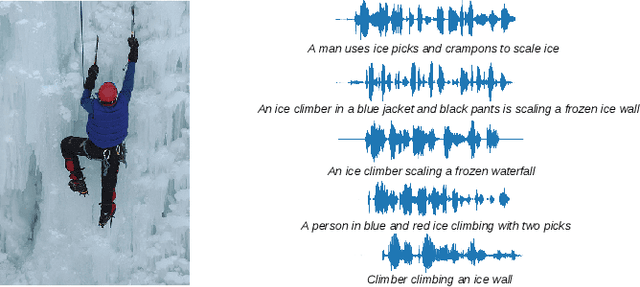
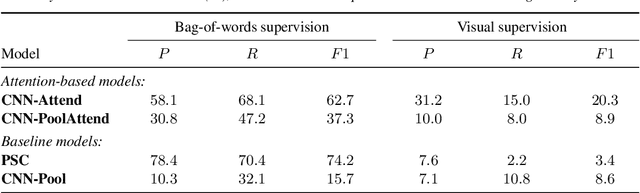
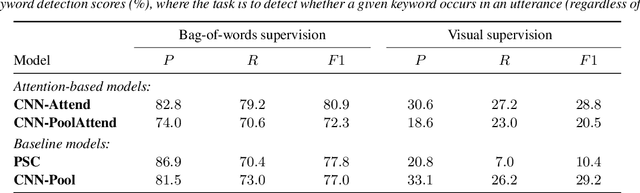
Keyword localisation is the task of finding where in a speech utterance a given query keyword occurs. We investigate to what extent keyword localisation is possible using a visually grounded speech (VGS) model. VGS models are trained on unlabelled images paired with spoken captions. These models are therefore self-supervised -- trained without any explicit textual label or location information. To obtain training targets, we first tag training images with soft text labels using a pretrained visual classifier with a fixed vocabulary. This enables a VGS model to predict the presence of a written keyword in an utterance, but not its location. We consider four ways to equip VGS models with localisations capabilities. Two of these -- a saliency approach and input masking -- can be applied to an arbitrary prediction model after training, while the other two -- attention and a score aggregation approach -- are incorporated directly into the structure of the model. Masked-based localisation gives some of the best reported localisation scores from a VGS model, with an accuracy of 57% when the system knows that a keyword occurs in an utterance and need to predict its location. In a setting where localisation is performed after detection, an $F_1$ of 25% is achieved, and in a setting where a keyword spotting ranking pass is first performed, we get a localisation P@10 of 32%. While these scores are modest compared to the idealised setting with unordered bag-of-word-supervision (from transcriptions), these models do not receive any textual or location supervision. Further analyses show that these models are limited by the first detection or ranking pass. Moreover, individual keyword localisation performance is correlated with the tagging performance from the visual classifier. We also show qualitatively how and where semantic mistakes occur, e.g. that the model locates surfer when queried with ocean.
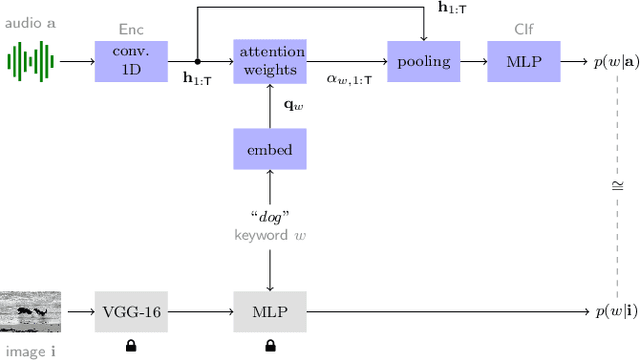
Attention-Based Keyword Localisation in Speech using Visual Grounding
Jun 23, 2021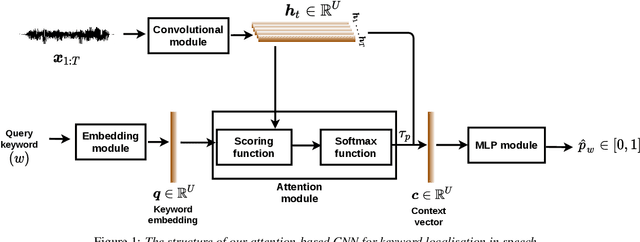
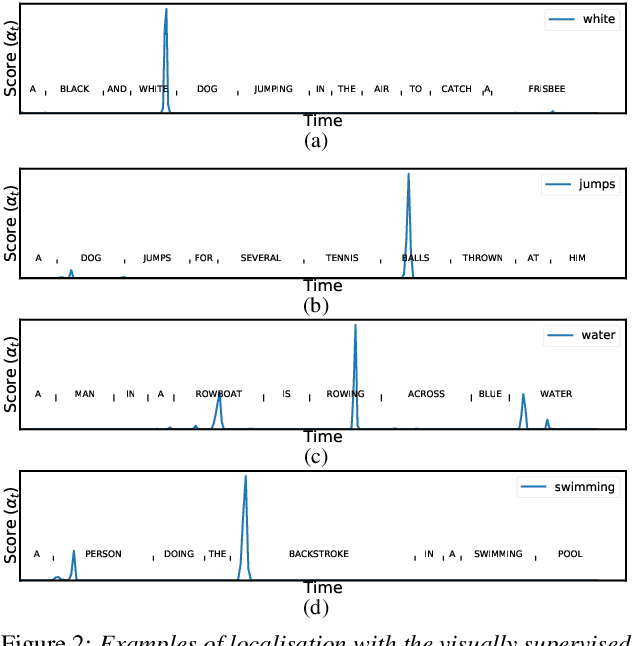
Visually grounded speech models learn from images paired with spoken captions. By tagging images with soft text labels using a trained visual classifier with a fixed vocabulary, previous work has shown that it is possible to train a model that can detect whether a particular text keyword occurs in speech utterances or not. Here we investigate whether visually grounded speech models can also do keyword localisation: predicting where, within an utterance, a given textual keyword occurs without any explicit text-based or alignment supervision. We specifically consider whether incorporating attention into a convolutional model is beneficial for localisation. Although absolute localisation performance with visually supervised models is still modest (compared to using unordered bag-of-word text labels for supervision), we show that attention provides a large gain in performance over previous visually grounded models. As in many other speech-image studies, we find that many of the incorrect localisations are due to semantic confusions, e.g. locating the word 'backstroke' for the query keyword 'swimming'.
Towards localisation of keywords in speech using weak supervision
Dec 14, 2020Developments in weakly supervised and self-supervised models could enable speech technology in low-resource settings where full transcriptions are not available. We consider whether keyword localisation is possible using two forms of weak supervision where location information is not provided explicitly. In the first, only the presence or absence of a word is indicated, i.e. a bag-of-words (BoW) labelling. In the second, visual context is provided in the form of an image paired with an unlabelled utterance; a model then needs to be trained in a self-supervised fashion using the paired data. For keyword localisation, we adapt a saliency-based method typically used in the vision domain. We compare this to an existing technique that performs localisation as a part of the network architecture. While the saliency-based method is more flexible (it can be applied without architectural restrictions), we identify a critical limitation when using it for keyword localisation. Of the two forms of supervision, the visually trained model performs worse than the BoW-trained model. We show qualitatively that the visually trained model sometimes locate semantically related words, but this is not consistent. While our results show that there is some signal allowing for localisation, it also calls for other localisation methods better matched to these forms of weak supervision.