 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking real-world audio deepfakes: A data-centric approach
Jun 11, 2025The growing prevalence of real-world deepfakes presents a critical challenge for existing detection systems, which are often evaluated on datasets collected just for scientific purposes. To address this gap, we introduce a novel dataset of real-world audio deepfakes. Our analysis reveals that these real-world examples pose significant challenges, even for the most performant detection models. Rather than increasing model complexity or exhaustively search for a better alternative, in this work we focus on a data-centric paradigm, employing strategies like dataset curation, pruning, and augmentation to improve model robustness and generalization. Through these methods, we achieve a 55% relative reduction in EER on the In-the-Wild dataset, reaching an absolute EER of 1.7%, and a 63% reduction on our newly proposed real-world deepfakes dataset, AI4T. These results highlight the transformative potential of data-centric approaches in enhancing deepfake detection for real-world applications. Code and data available at: https://github.com/davidcombei/AI4T.
TADA: Training-free Attribution and Out-of-Domain Detection of Audio Deepfakes
Jun 06, 2025Deepfake detection has gained significant attention across audio, text, and image modalities, with high accuracy in distinguishing real from fake. However, identifying the exact source--such as the system or model behind a deepfake--remains a less studied problem. In this paper, we take a significant step forward in audio deepfake model attribution or source tracing by proposing a training-free, green AI approach based entirely on k-Nearest Neighbors (kNN). Leveraging a pre-trained self-supervised learning (SSL) model, we show that grouping samples from the same generator is straightforward--we obtain an 0.93 F1-score across five deepfake datasets. The method also demonstrates strong out-of-domain (OOD) detection, effectively identifying samples from unseen models at an F1-score of 0.84. We further analyse these results in a multi-dimensional approach and provide additional insights. All code and data protocols used in this work are available in our open repository: https://github.com/adrianastan/tada/.
Seeing What Tastes Good: Revisiting Multimodal Distributional Semantics in the Billion Parameter Era
Jun 04, 2025Human learning and conceptual representation is grounded in sensorimotor experience, in contrast to state-of-the-art foundation models. In this paper, we investigate how well such large-scale models, trained on vast quantities of data, represent the semantic feature norms of concrete object concepts, e.g. a ROSE is red, smells sweet, and is a flower. More specifically, we use probing tasks to test which properties of objects these models are aware of. We evaluate image encoders trained on image data alone, as well as multimodally-trained image encoders and language-only models, on predicting an extended denser version of the classic McRae norms and the newer Binder dataset of attribute ratings. We find that multimodal image encoders slightly outperform language-only approaches, and that image-only encoders perform comparably to the language models, even on non-visual attributes that are classified as "encyclopedic" or "function". These results offer new insights into what can be learned from pure unimodal learning, and the complementarity of the modalities.
The mutual exclusivity bias of bilingual visually grounded speech models
Jun 04, 2025Mutual exclusivity (ME) is a strategy where a novel word is associated with a novel object rather than a familiar one, facilitating language learning in children. Recent work has found an ME bias in a visually grounded speech (VGS) model trained on English speech with paired images. But ME has also been studied in bilingual children, who may employ it less due to cross-lingual ambiguity. We explore this pattern computationally using bilingual VGS models trained on combinations of English, French, and Dutch. We find that bilingual models generally exhibit a weaker ME bias than monolingual models, though exceptions exist. Analyses show that the combined visual embeddings of bilingual models have a smaller variance for familiar data, partly explaining the increase in confusion between novel and familiar concepts. We also provide new insights into why the ME bias exists in VGS models in the first place. Code and data: https://github.com/danoneata/me-vgs
Circumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning
Nov 29, 2024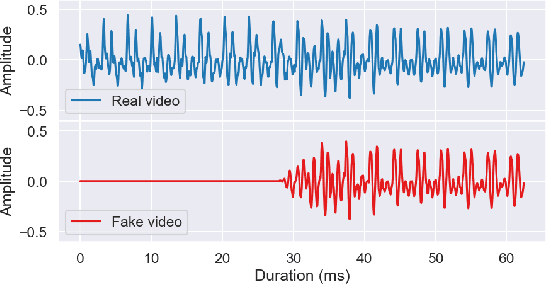
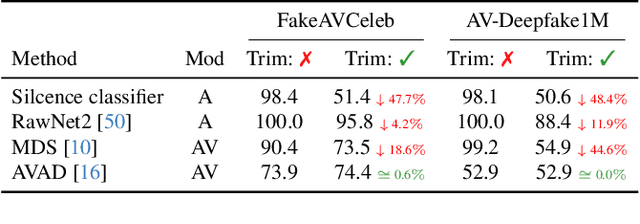
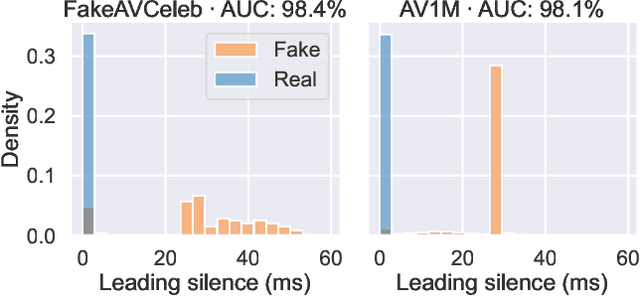

Good datasets are essential for developing and benchmarking any machine learning system. Their importance is even more extreme for safety critical applications such as deepfake detection - the focus of this paper. Here we reveal that two of the most widely used audio-video deepfake datasets suffer from a previously unidentified spurious feature: the leading silence. Fake videos start with a very brief moment of silence and based on this feature alone, we can separate the real and fake samples almost perfectly. As such, previous audio-only and audio-video models exploit the presence of silence in the fake videos and consequently perform worse when the leading silence is removed. To circumvent latching on such unwanted artifact and possibly other unrevealed ones we propose a shift from supervised to unsupervised learning by training models exclusively on real data. We show that by aligning self-supervised audio-video representations we remove the risk of relying on dataset-specific biases and improve robustness in deepfake detection.
DeCLIP: Decoding CLIP representations for deepfake localization
Sep 12, 2024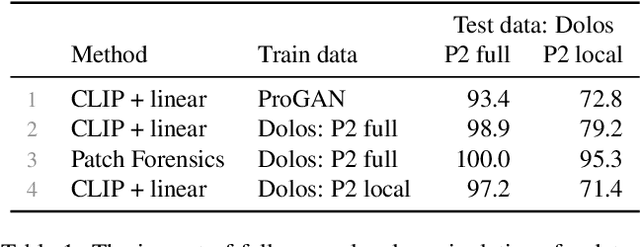
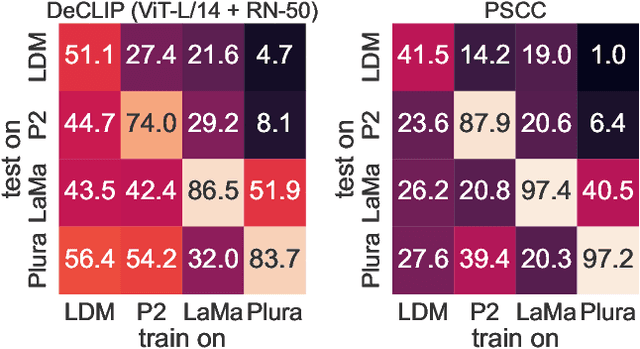
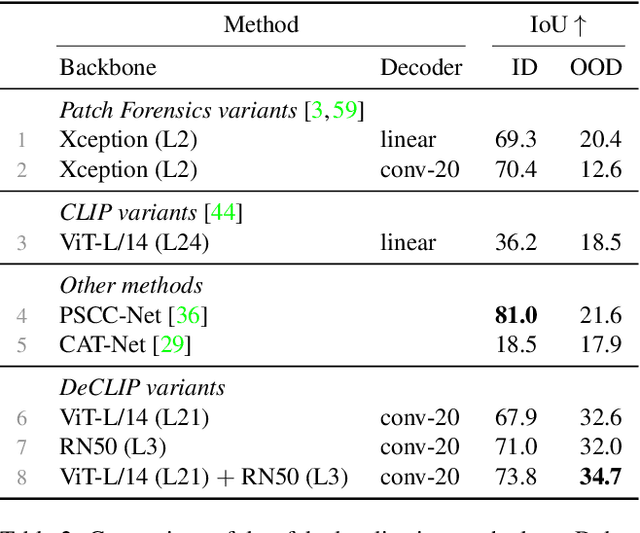

Generative models can create entirely new images, but they can also partially modify real images in ways that are undetectable to the human eye. In this paper, we address the challenge of automatically detecting such local manipulations. One of the most pressing problems in deepfake detection remains the ability of models to generalize to different classes of generators. In the case of fully manipulated images, representations extracted from large self-supervised models (such as CLIP) provide a promising direction towards more robust detectors. Here, we introduce DeCLIP, a first attempt to leverage such large pretrained features for detecting local manipulations. We show that, when combined with a reasonably large convolutional decoder, pretrained self-supervised representations are able to perform localization and improve generalization capabilities over existing methods. Unlike previous work, our approach is able to perform localization on the challenging case of latent diffusion models, where the entire image is affected by the fingerprint of the generator. Moreover, we observe that this type of data, which combines local semantic information with a global fingerprint, provides more stable generalization than other categories of generative methods.
Improved Visually Prompted Keyword Localisation in Real Low-Resource Settings
Sep 09, 2024



Given an image query, visually prompted keyword localisation (VPKL) aims to find occurrences of the depicted word in a speech collection. This can be useful when transcriptions are not available for a low-resource language (e.g. if it is unwritten). Previous work showed that VPKL can be performed with a visually grounded speech model trained on paired images and unlabelled speech. But all experiments were done on English. Moreover, transcriptions were used to get positive and negative pairs for the contrastive loss. This paper introduces a few-shot learning scheme to mine pairs automatically without transcriptions. On English, this results in only a small drop in performance. We also - for the first time - consider VPKL on a real low-resource language, Yoruba. While scores are reasonable, here we see a bigger drop in performance compared to using ground truth pairs because the mining is less accurate in Yoruba.
Easy, Interpretable, Effective: openSMILE for voice deepfake detection
Aug 29, 2024



In this paper, we demonstrate that attacks in the latest ASVspoof5 dataset -- a de facto standard in the field of voice authenticity and deepfake detection -- can be identified with surprising accuracy using a small subset of very simplistic features. These are derived from the openSMILE library, and are scalar-valued, easy to compute, and human interpretable. For example, attack A10`s unvoiced segments have a mean length of 0.09 +- 0.02, while bona fide instances have a mean length of 0.18 +- 0.07. Using this feature alone, a threshold classifier achieves an Equal Error Rate (EER) of 10.3% for attack A10. Similarly, across all attacks, we achieve up to 0.8% EER, with an overall EER of 15.7 +- 6.0%. We explore the generalization capabilities of these features and find that some of them transfer effectively between attacks, primarily when the attacks originate from similar Text-to-Speech (TTS) architectures. This finding may indicate that voice anti-spoofing is, in part, a problem of identifying and remembering signatures or fingerprints of individual TTS systems. This allows to better understand anti-spoofing models and their challenges in real-world application.
WavLM model ensemble for audio deepfake detection
Aug 14, 2024



Audio deepfake detection has become a pivotal task over the last couple of years, as many recent speech synthesis and voice cloning systems generate highly realistic speech samples, thus enabling their use in malicious activities. In this paper we address the issue of audio deepfake detection as it was set in the ASVspoof5 challenge. First, we benchmark ten types of pretrained representations and show that the self-supervised representations stemming from the wav2vec2 and wavLM families perform best. Of the two, wavLM is better when restricting the pretraining data to LibriSpeech, as required by the challenge rules. To further improve performance, we finetune the wavLM model for the deepfake detection task. We extend the ASVspoof5 dataset with samples from other deepfake detection datasets and apply data augmentation. Our final challenge submission consists of a late fusion combination of four models and achieves an equal error rate of 6.56% and 17.08% on the two evaluation sets.
Translating speech with just images
Jun 11, 2024Visually grounded speech models link speech to images. We extend this connection by linking images to text via an existing image captioning system, and as a result gain the ability to map speech audio directly to text. This approach can be used for speech translation with just images by having the audio in a different language from the generated captions. We investigate such a system on a real low-resource language, Yor\`ub\'a, and propose a Yor\`ub\'a-to-English speech translation model that leverages pretrained components in order to be able to learn in the low-resource regime. To limit overfitting, we find that it is essential to use a decoding scheme that produces diverse image captions for training. Results show that the predicted translations capture the main semantics of the spoken audio, albeit in a simpler and shorter form.