 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking real-world audio deepfakes: A data-centric approach
Jun 11, 2025

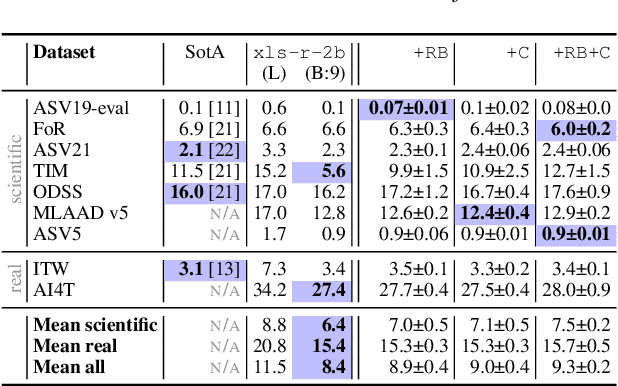
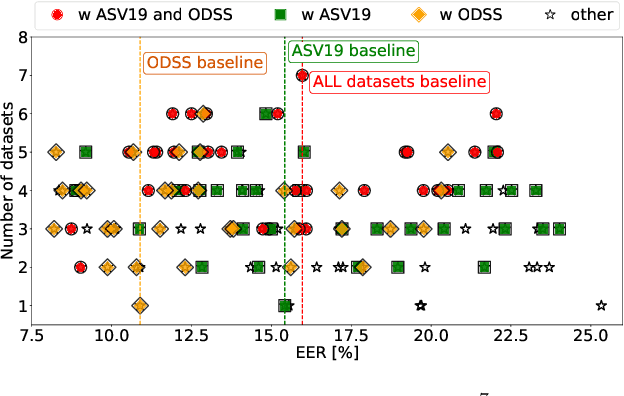
The growing prevalence of real-world deepfakes presents a critical challenge for existing detection systems, which are often evaluated on datasets collected just for scientific purposes. To address this gap, we introduce a novel dataset of real-world audio deepfakes. Our analysis reveals that these real-world examples pose significant challenges, even for the most performant detection models. Rather than increasing model complexity or exhaustively search for a better alternative, in this work we focus on a data-centric paradigm, employing strategies like dataset curation, pruning, and augmentation to improve model robustness and generalization. Through these methods, we achieve a 55% relative reduction in EER on the In-the-Wild dataset, reaching an absolute EER of 1.7%, and a 63% reduction on our newly proposed real-world deepfakes dataset, AI4T. These results highlight the transformative potential of data-centric approaches in enhancing deepfake detection for real-world applications. Code and data available at: https://github.com/davidcombei/AI4T.
TADA: Training-free Attribution and Out-of-Domain Detection of Audio Deepfakes
Jun 06, 2025Deepfake detection has gained significant attention across audio, text, and image modalities, with high accuracy in distinguishing real from fake. However, identifying the exact source--such as the system or model behind a deepfake--remains a less studied problem. In this paper, we take a significant step forward in audio deepfake model attribution or source tracing by proposing a training-free, green AI approach based entirely on k-Nearest Neighbors (kNN). Leveraging a pre-trained self-supervised learning (SSL) model, we show that grouping samples from the same generator is straightforward--we obtain an 0.93 F1-score across five deepfake datasets. The method also demonstrates strong out-of-domain (OOD) detection, effectively identifying samples from unseen models at an F1-score of 0.84. We further analyse these results in a multi-dimensional approach and provide additional insights. All code and data protocols used in this work are available in our open repository: https://github.com/adrianastan/tada/.
WavLM model ensemble for audio deepfake detection
Aug 14, 2024



Audio deepfake detection has become a pivotal task over the last couple of years, as many recent speech synthesis and voice cloning systems generate highly realistic speech samples, thus enabling their use in malicious activities. In this paper we address the issue of audio deepfake detection as it was set in the ASVspoof5 challenge. First, we benchmark ten types of pretrained representations and show that the self-supervised representations stemming from the wav2vec2 and wavLM families perform best. Of the two, wavLM is better when restricting the pretraining data to LibriSpeech, as required by the challenge rules. To further improve performance, we finetune the wavLM model for the deepfake detection task. We extend the ASVspoof5 dataset with samples from other deepfake detection datasets and apply data augmentation. Our final challenge submission consists of a late fusion combination of four models and achieves an equal error rate of 6.56% and 17.08% on the two evaluation sets.