 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchoring the Unknown: Open-Set Model Attribution via Proxy-Anchor Learning
Jun 09, 2026The proliferation of text-to-speech (TTS) systems capable of generating realistic synthetic speech poses growing challenges for audio forensics. While binary deepfake detection has received considerable attention, source tracing (i.e., identifying which TTS system produced a given audio sample) remains underexplored, particularly in open-set scenarios where unknown systems may be encountered. We propose a metric learning framework based on the Proxy-Anchor loss function that operates on Wav2Vec2-BERT embeddings to learn a discriminative embedding space for TTS source attribution and out-of-distribution (OOD) detection of unseen systems. We evaluate it on the MLAAD v9 dataset spanning 140 TTS systems across 51 languages, and introduce an architecture merging strategy that groups TTS system versions into unified classes, reducing inter-class confusion. Our system achieves 99.76% accuracy on 110 in-distribution classes and a False Positive Rate (FPR@95) as low as 2.04% for OOD detection. Also, for a fair comparison against the current state of the art, we further evaluate it on the MLAAD v5 official dataset splits, improving the OOD accuracy by almost doubling it. These results demonstrate that Proxy-Anchor metric learning, combined with architecture-aware class design and post-hoc OOD scoring, provides an effective framework for forensic TTS source tracing in both closed-set and open-set settings.
How Open is Open TTS? A Practical Evaluation of Open Source TTS Tools for Romanian
Mar 25, 2026Open-source text-to-speech (TTS) frameworks have emerged as highly adaptable platforms for developing speech synthesis systems across a wide range of languages. However, their applicability is not uniform -- particularly when the target language is under-resourced or when computational resources are constrained. In this study, we systematically assess the feasibility of building novel TTS models using four widely adopted open-source architectures: FastPitch, VITS, Grad-TTS, and Matcha-TTS. Our evaluation spans multiple dimensions, including qualitative aspects such as ease of installation, dataset preparation, and hardware requirements, as well as quantitative assessments of synthesis quality for Romanian. We employ both objective metrics and subjective listening tests to evaluate intelligibility, speaker similarity, and naturalness of the generated speech. The results reveal significant challenges in tool chain setup, data preprocessing, and computational efficiency, which can hinder adoption in low-resource contexts. By grounding the analysis in reproducible protocols and accessible evaluation criteria, this work aims to inform best practices and promote more inclusive, language-diverse TTS development. All information needed to reproduce this study (i.e. code and data) are available in our git repository: https://gitlab.com/opentts_ragman/OpenTTS
Echoes: A semantically-aligned music deepfake detection dataset
Mar 24, 2026We introduce Echoes, a new dataset for music deepfake detection designed for training and benchmarking detectors under realistic and provider-diverse conditions. Echoes comprises 3,577 tracks (110 hours of audio) spanning multiple genres (pop, rock, electronic), and includes content generated by ten popular AI music generation systems. To prevent shortcut learning and promote robust generalization, the dataset is deliberately constructed to be challenging, enforcing semantic-level alignment between spoofed audio and bona fide references. This alignment is achieved by conditioning generated audio samples directly on bona-fide waveforms or song descriptors. We evaluate Echoes in a cross-dataset setting against three existing AI-generated music datasets using state-of-the-art Wav2Vec2 XLS-R 2B representations. Results show that (i) Echoes is the hardest in-domain dataset; (ii) detectors trained on existing datasets transfer poorly to Echoes; (iii) training on Echoes yields the strongest generalization performance. These findings suggest that provider diversity and semantic alignment help learn more transferable detection cues.
Understanding the strengths and weaknesses of SSL models for audio deepfake model attribution
Mar 13, 2026Audio deepfake model attribution aims to mitigate the misuse of synthetic speech by identifying the source model responsible for generating a given audio sample, enabling accountability and informing vendors. The task is challenging, but self-supervised learning (SSL)-derived acoustic features have demonstrated state-of-the-art attribution capabilities, yet the underlying factors driving their success and the limits of their discriminative power remain unclear. In this paper, we systematically investigate how SSL-derived features capture architectural signatures in audio deepfakes. By controlling multiple dimensions of the audio generation process we reveal how subtle perturbations in model checkpoints, text prompts, vocoders, or speaker identity influence attribution. Our results provide new insights into the robustness, biases, and limitations of SSL-based deepfake attribution, highlighting both its strengths and vulnerabilities in realistic scenarios.
Unmasking real-world audio deepfakes: A data-centric approach
Jun 11, 2025

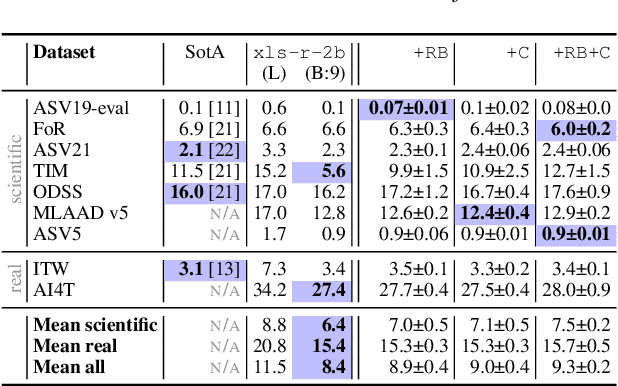
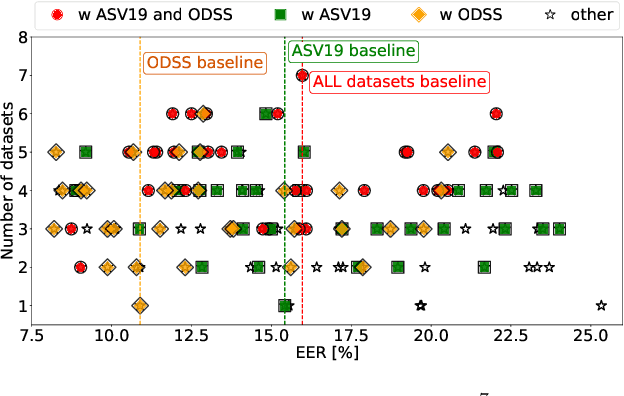
The growing prevalence of real-world deepfakes presents a critical challenge for existing detection systems, which are often evaluated on datasets collected just for scientific purposes. To address this gap, we introduce a novel dataset of real-world audio deepfakes. Our analysis reveals that these real-world examples pose significant challenges, even for the most performant detection models. Rather than increasing model complexity or exhaustively search for a better alternative, in this work we focus on a data-centric paradigm, employing strategies like dataset curation, pruning, and augmentation to improve model robustness and generalization. Through these methods, we achieve a 55% relative reduction in EER on the In-the-Wild dataset, reaching an absolute EER of 1.7%, and a 63% reduction on our newly proposed real-world deepfakes dataset, AI4T. These results highlight the transformative potential of data-centric approaches in enhancing deepfake detection for real-world applications. Code and data available at: https://github.com/davidcombei/AI4T.
Easy, Interpretable, Effective: openSMILE for voice deepfake detection
Aug 29, 2024



In this paper, we demonstrate that attacks in the latest ASVspoof5 dataset -- a de facto standard in the field of voice authenticity and deepfake detection -- can be identified with surprising accuracy using a small subset of very simplistic features. These are derived from the openSMILE library, and are scalar-valued, easy to compute, and human interpretable. For example, attack A10`s unvoiced segments have a mean length of 0.09 +- 0.02, while bona fide instances have a mean length of 0.18 +- 0.07. Using this feature alone, a threshold classifier achieves an Equal Error Rate (EER) of 10.3% for attack A10. Similarly, across all attacks, we achieve up to 0.8% EER, with an overall EER of 15.7 +- 6.0%. We explore the generalization capabilities of these features and find that some of them transfer effectively between attacks, primarily when the attacks originate from similar Text-to-Speech (TTS) architectures. This finding may indicate that voice anti-spoofing is, in part, a problem of identifying and remembering signatures or fingerprints of individual TTS systems. This allows to better understand anti-spoofing models and their challenges in real-world application.
WavLM model ensemble for audio deepfake detection
Aug 14, 2024



Audio deepfake detection has become a pivotal task over the last couple of years, as many recent speech synthesis and voice cloning systems generate highly realistic speech samples, thus enabling their use in malicious activities. In this paper we address the issue of audio deepfake detection as it was set in the ASVspoof5 challenge. First, we benchmark ten types of pretrained representations and show that the self-supervised representations stemming from the wav2vec2 and wavLM families perform best. Of the two, wavLM is better when restricting the pretraining data to LibriSpeech, as required by the challenge rules. To further improve performance, we finetune the wavLM model for the deepfake detection task. We extend the ASVspoof5 dataset with samples from other deepfake detection datasets and apply data augmentation. Our final challenge submission consists of a late fusion combination of four models and achieves an equal error rate of 6.56% and 17.08% on the two evaluation sets.
Towards generalisable and calibrated synthetic speech detection with self-supervised representations
Sep 11, 2023



Generalisation -- the ability of a model to perform well on unseen data -- is crucial for building reliable deep fake detectors. However, recent studies have shown that the current audio deep fake models fall short of this desideratum. In this paper we show that pretrained self-supervised representations followed by a simple logistic regression classifier achieve strong generalisation capabilities, reducing the equal error rate from 30% to 8% on the newly introduced In-the-Wild dataset. Importantly, this approach also produces considerably better calibrated models when compared to previous approaches. This means that we can trust our model's predictions more and use these for downstream tasks, such as uncertainty estimation. In particular, we show that the entropy of the estimated probabilities provides a reliable way of rejecting uncertain samples and further improving the accuracy.
Adaptation of Whisper models to child speech recognition
Jul 24, 2023



Automatic Speech Recognition (ASR) systems often struggle with transcribing child speech due to the lack of large child speech datasets required to accurately train child-friendly ASR models. However, there are huge amounts of annotated adult speech datasets which were used to create multilingual ASR models, such as Whisper. Our work aims to explore whether such models can be adapted to child speech to improve ASR for children. In addition, we compare Whisper child-adaptations with finetuned self-supervised models, such as wav2vec2. We demonstrate that finetuning Whisper on child speech yields significant improvements in ASR performance on child speech, compared to non finetuned Whisper models. Additionally, utilizing self-supervised Wav2vec2 models that have been finetuned on child speech outperforms Whisper finetuning.
Adaptive Planning Search Algorithm for Analog Circuit Verification
Jun 23, 2023


Integrated circuit verification has gathered considerable interest in recent times. Since these circuits keep growing in complexity year by year, pre-Silicon (pre-SI) verification becomes ever more important, in order to ensure proper functionality. Thus, in order to reduce the time needed for manually verifying ICs, we propose a machine learning (ML) approach, which uses less simulations. This method relies on an initial evaluation set of operating condition configurations (OCCs), in order to train Gaussian process (GP) surrogate models. By using surrogate models, we can propose further, more difficult OCCs. Repeating this procedure for several iterations has shown better GP estimation of the circuit's responses, on both synthetic and real circuits, resulting in a better chance of finding the worst case, or even failures, for certain circuit responses. Thus, we show that the proposed approach is able to provide OCCs closer to the specifications for all circuits and identify a failure (specification violation) for one of the responses of a real circuit.