 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoes: A semantically-aligned music deepfake detection dataset
Mar 24, 2026We introduce Echoes, a new dataset for music deepfake detection designed for training and benchmarking detectors under realistic and provider-diverse conditions. Echoes comprises 3,577 tracks (110 hours of audio) spanning multiple genres (pop, rock, electronic), and includes content generated by ten popular AI music generation systems. To prevent shortcut learning and promote robust generalization, the dataset is deliberately constructed to be challenging, enforcing semantic-level alignment between spoofed audio and bona fide references. This alignment is achieved by conditioning generated audio samples directly on bona-fide waveforms or song descriptors. We evaluate Echoes in a cross-dataset setting against three existing AI-generated music datasets using state-of-the-art Wav2Vec2 XLS-R 2B representations. Results show that (i) Echoes is the hardest in-domain dataset; (ii) detectors trained on existing datasets transfer poorly to Echoes; (iii) training on Echoes yields the strongest generalization performance. These findings suggest that provider diversity and semantic alignment help learn more transferable detection cues.
Easy, Interpretable, Effective: openSMILE for voice deepfake detection
Aug 29, 2024



In this paper, we demonstrate that attacks in the latest ASVspoof5 dataset -- a de facto standard in the field of voice authenticity and deepfake detection -- can be identified with surprising accuracy using a small subset of very simplistic features. These are derived from the openSMILE library, and are scalar-valued, easy to compute, and human interpretable. For example, attack A10`s unvoiced segments have a mean length of 0.09 +- 0.02, while bona fide instances have a mean length of 0.18 +- 0.07. Using this feature alone, a threshold classifier achieves an Equal Error Rate (EER) of 10.3% for attack A10. Similarly, across all attacks, we achieve up to 0.8% EER, with an overall EER of 15.7 +- 6.0%. We explore the generalization capabilities of these features and find that some of them transfer effectively between attacks, primarily when the attacks originate from similar Text-to-Speech (TTS) architectures. This finding may indicate that voice anti-spoofing is, in part, a problem of identifying and remembering signatures or fingerprints of individual TTS systems. This allows to better understand anti-spoofing models and their challenges in real-world application.
Towards generalisable and calibrated synthetic speech detection with self-supervised representations
Sep 11, 2023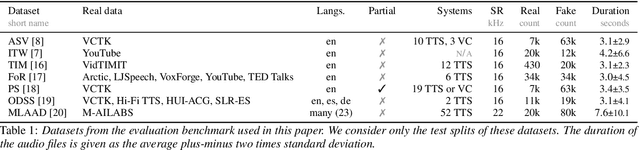



Generalisation -- the ability of a model to perform well on unseen data -- is crucial for building reliable deep fake detectors. However, recent studies have shown that the current audio deep fake models fall short of this desideratum. In this paper we show that pretrained self-supervised representations followed by a simple logistic regression classifier achieve strong generalisation capabilities, reducing the equal error rate from 30% to 8% on the newly introduced In-the-Wild dataset. Importantly, this approach also produces considerably better calibrated models when compared to previous approaches. This means that we can trust our model's predictions more and use these for downstream tasks, such as uncertainty estimation. In particular, we show that the entropy of the estimated probabilities provides a reliable way of rejecting uncertain samples and further improving the accuracy.
Automated Circuit Sizing with Multi-objective Optimization based on Differential Evolution and Bayesian Inference
Jun 06, 2022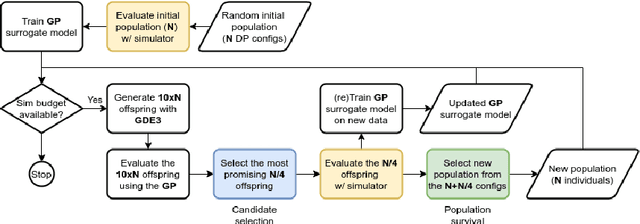
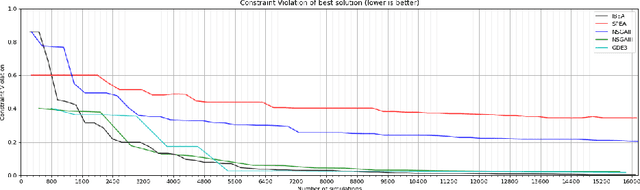
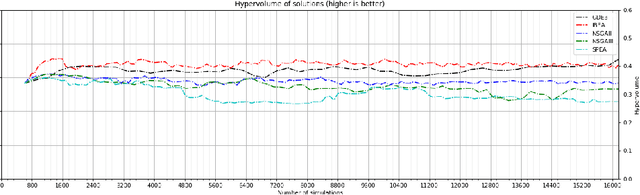
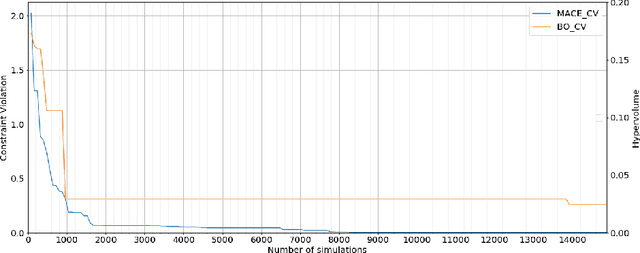
With the ever increasing complexity of specifications, manual sizing for analog circuits recently became very challenging. Especially for innovative, large-scale circuits designs, with tens of design variables, operating conditions and conflicting objectives to be optimized, design engineers spend many weeks, running time-consuming simulations, in their attempt at finding the right configuration. Recent years brought machine learning and optimization techniques to the field of analog circuits design, with evolutionary algorithms and Bayesian models showing good results for circuit sizing. In this context, we introduce a design optimization method based on Generalized Differential Evolution 3 (GDE3) and Gaussian Processes (GPs). The proposed method is able to perform sizing for complex circuits with a large number of design variables and many conflicting objectives to be optimized. While state-of-the-art methods reduce multi-objective problems to single-objective optimization and potentially induce a prior bias, we search directly over the multi-objective space using Pareto dominance and ensure that diverse solutions are provided to the designers to choose from. To the best of our knowledge, the proposed method is the first to specifically address the diversity of the solutions, while also focusing on minimizing the number of simulations required to reach feasible configurations. We evaluate the introduced method on two voltage regulators showing different levels of complexity and we highlight that the proposed innovative candidate selection method and survival policy leads to obtaining feasible solutions, with a high degree of diversity, much faster than with GDE3 or Bayesian Optimization-based algorithms.
The Quo Vadis submission at Traffic4cast 2019
Oct 27, 2019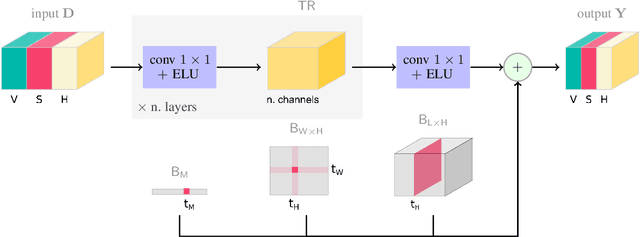
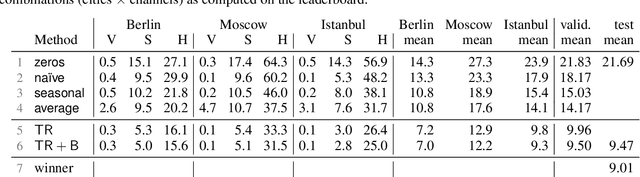
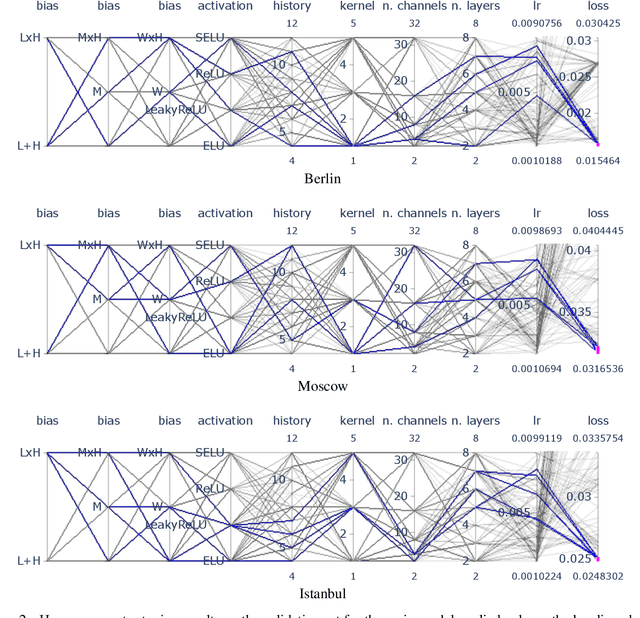

We describe the submission of the Quo Vadis team to the Traffic4cast competition, which was organized as part of the NeurIPS 2019 series of challenges. Our system consists of a temporal regression module, implemented as $1\times1$ 2d convolutions, augmented with spatio-temporal biases. We have found that using biases is a straightforward and efficient way to include seasonal patterns and to improve the performance of the temporal regression model. Our implementation obtains a mean squared error of $9.47\times 10^{-3}$ on the test data, placing us on the eight place team-wise. We also present our attempts at incorporating spatial correlations into the model; however, contrary to our expectations, adding this type of auxiliary information did not benefit the main system. Our code is available at https://github.com/danoneata/traffic4cast.