 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Towards Alleviating Code-Switched Data Scarcity in Under-Resourced Languages with GPT as a Pivot
Apr 26, 2024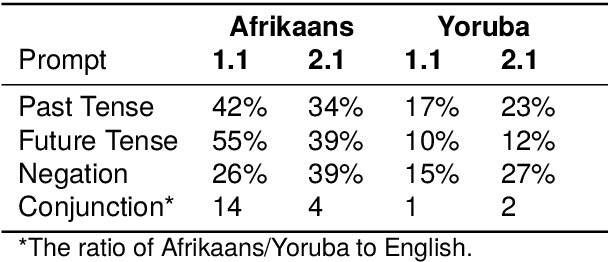
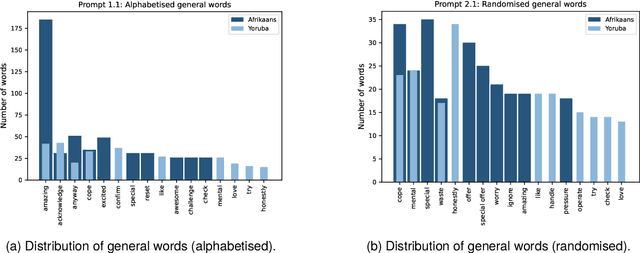
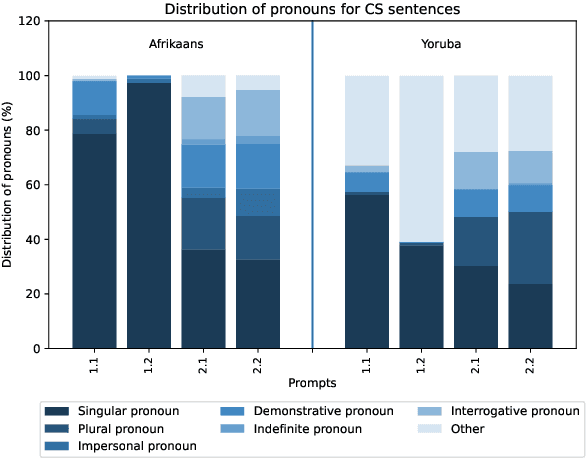
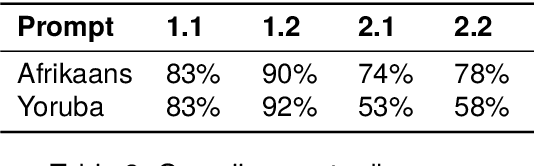
Many multilingual communities, including numerous in Africa, frequently engage in code-switching during conversations. This behaviour stresses the need for natural language processing technologies adept at processing code-switched text. However, data scarcity, particularly in African languages, poses a significant challenge, as many are low-resourced and under-represented. In this study, we prompted GPT 3.5 to generate Afrikaans--English and Yoruba--English code-switched sentences, enhancing diversity using topic-keyword pairs, linguistic guidelines, and few-shot examples. Our findings indicate that the quality of generated sentences for languages using non-Latin scripts, like Yoruba, is considerably lower when compared with the high Afrikaans-English success rate. There is therefore a notable opportunity to refine prompting guidelines to yield sentences suitable for the fine-tuning of language models. We propose a framework for augmenting the diversity of synthetically generated code-switched data using GPT and propose leveraging this technology to mitigate data scarcity in low-resourced languages, underscoring the essential role of native speakers in this process.
Towards Financial Sentiment Analysis in a South African Landscape
Jun 18, 2021



Sentiment analysis as a sub-field of natural language processing has received increased attention in the past decade enabling organisations to more effectively manage their reputation through online media monitoring. Many drivers impact reputation, however, this thesis focuses only the aspect of financial performance and explores the gap with regards to financial sentiment analysis in a South African context. Results showed that pre-trained sentiment analysers are least effective for this task and that traditional lexicon-based and machine learning approaches are best suited to predict financial sentiment of news articles. The evaluated methods produced accuracies of 84\%-94\%. The predicted sentiments correlated quite well with share price and highlighted the potential use of sentiment as an indicator of financial performance. A main contribution of the study was updating an existing sentiment dictionary for financial sentiment analysis. Model generalisation was less acceptable due to the limited amount of training data used. Future work includes expanding the data set to improve general usability and contribute to an open-source financial sentiment analyser for South African data.