 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery with Language Models as Imperfect Experts
Jul 05, 2023



Understanding the causal relationships that underlie a system is a fundamental prerequisite to accurate decision-making. In this work, we explore how expert knowledge can be used to improve the data-driven identification of causal graphs, beyond Markov equivalence classes. In doing so, we consider a setting where we can query an expert about the orientation of causal relationships between variables, but where the expert may provide erroneous information. We propose strategies for amending such expert knowledge based on consistency properties, e.g., acyclicity and conditional independencies in the equivalence class. We then report a case study, on real data, where a large language model is used as an imperfect expert.
Can large language models build causal graphs?
Mar 07, 2023



Building causal graphs can be a laborious process. To ensure all relevant causal pathways have been captured, researchers often have to discuss with clinicians and experts while also reviewing extensive relevant medical literature. By encoding common and medical knowledge, large language models (LLMs) represent an opportunity to ease this process by automatically scoring edges (i.e., connections between two variables) in potential graphs. LLMs however have been shown to be brittle to the choice of probing words, context, and prompts that the user employs. In this work, we evaluate if LLMs can be a useful tool in complementing causal graph development.
Bayesian Nonparametric Modeling of Heterogeneous Groups of Censored Data
Dec 02, 2016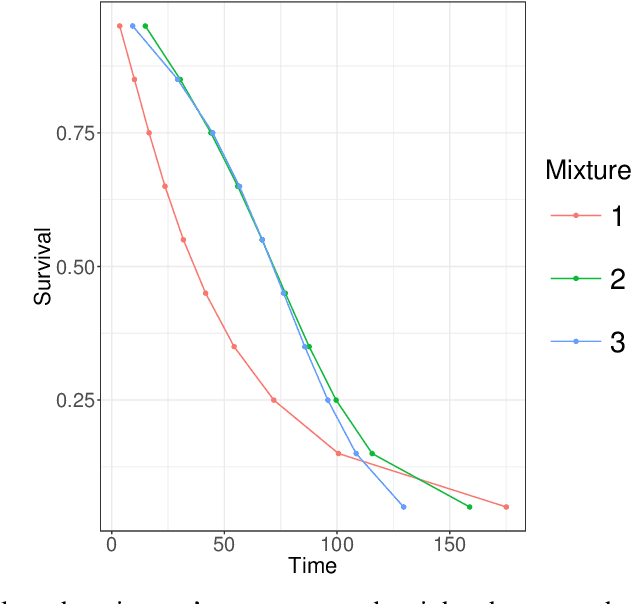
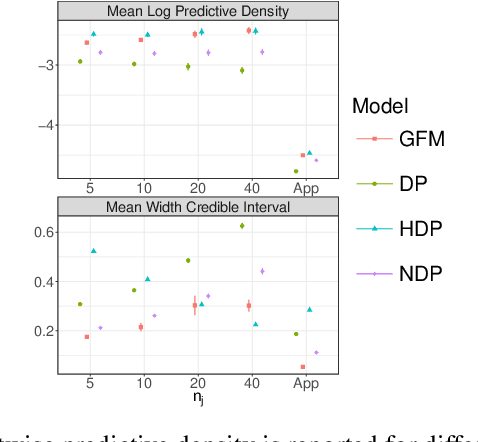
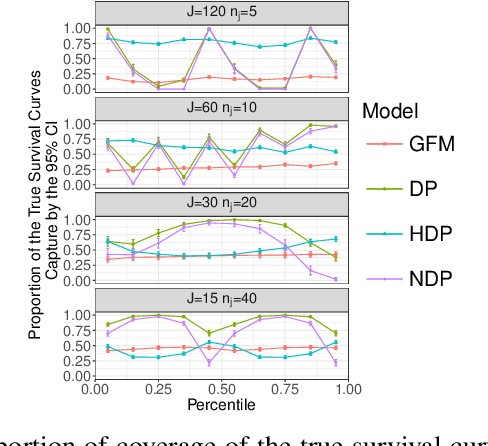

Datasets containing large samples of time-to-event data arising from several small heterogeneous groups are commonly encountered in statistics. This presents problems as they cannot be pooled directly due to their heterogeneity or analyzed individually because of their small sample size. Bayesian nonparametric modelling approaches can be used to model such datasets given their ability to flexibly share information across groups. In this paper, we will compare three popular Bayesian nonparametric methods for modelling the survival functions of heterogeneous groups. Specifically, we will first compare the modelling accuracy of the Dirichlet process, the hierarchical Dirichlet process, and the nested Dirichlet process on simulated datasets of different sizes, where group survival curves differ in shape or in expectation. We, then, will compare the models on a real-world injury dataset.