Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Estimation for Variance Reduction in Deep Reinforcement Learning
Paper and Code
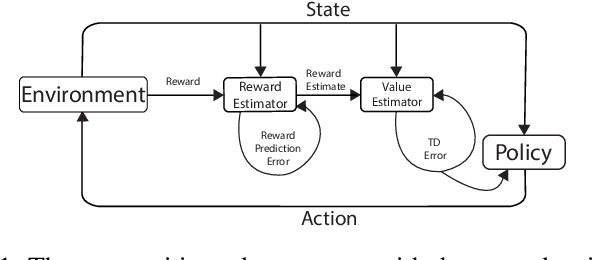
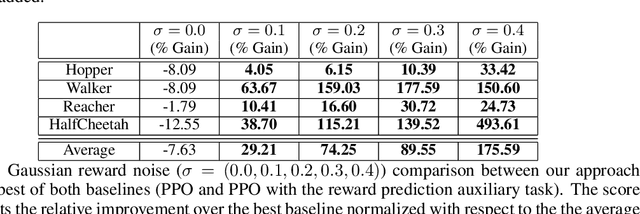
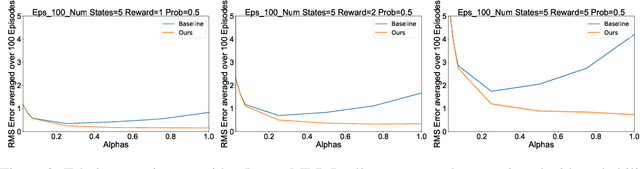

In reinforcement learning (RL), stochastic environments can make learning a policy difficult due to high degrees of variance. As such, variance reduction methods have been investigated in other works, such as advantage estimation and control-variates estimation. Here, we propose to learn a separate reward estimator to train the value function, to help reduce variance caused by a noisy reward signal. This results in theoretical reductions in variance in the tabular case, as well as empirical improvements in both the function approximation and tabular settings in environments where rewards are stochastic. To do so, we use a modified version of Advantage Actor Critic (A2C) on variations of Atari games.
* Accepted to the International Conference on Learning Representations
(ICLR) 2018 Workshop Track
View paper on