 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Knowledge Graph-Based Human-Like Memory Systems to Solve Partially Observable Markov Decision Processes
Aug 11, 2024Humans observe only part of their environment at any moment but can still make complex, long-term decisions thanks to our long-term memory system. To test how an AI can learn and utilize its long-term memory system, we have developed a partially observable Markov decision processes (POMDP) environment, where the agent has to answer questions while navigating a maze. The environment is completely knowledge graph (KG) based, where the hidden states are dynamic KGs. A KG is both human- and machine-readable, making it easy to see what the agents remember and forget. We train and compare agents with different memory systems, to shed light on how human brains work when it comes to managing its own memory systems. By repurposing the given learning objective as learning a memory management policy, we were able to capture the most likely belief state, which is not only interpretable but also reusable.
A Machine with Short-Term, Episodic, and Semantic Memory Systems
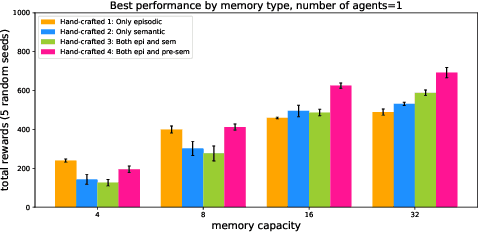
Dec 05, 2022Inspired by the cognitive science theory of the explicit human memory systems, we have modeled an agent with short-term, episodic, and semantic memory systems, each of which is modeled with a knowledge graph. To evaluate this system and analyze the behavior of this agent, we designed and released our own reinforcement learning agent environment, "the Room", where an agent has to learn how to encode, store, and retrieve memories to maximize its return by answering questions. We show that our deep Q-learning based agent successfully learns whether a short-term memory should be forgotten, or rather be stored in the episodic or semantic memory systems. Our experiments indicate that an agent with human-like memory systems can outperform an agent without this memory structure in the environment.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022
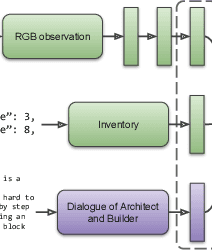
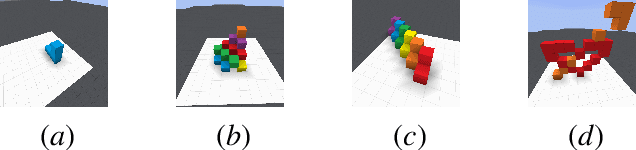
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
A Machine With Human-Like Memory Systems
Apr 04, 2022
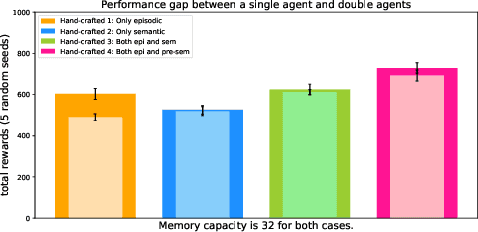
Inspired by the cognitive science theory, we explicitly model an agent with both semantic and episodic memory systems, and show that it is better than having just one of the two memory systems. In order to show this, we have designed and released our own challenging environment, "the Room", compatible with OpenAI Gym, where an agent has to properly learn how to encode, store, and retrieve memories to maximize its rewards. The Room environment allows for a hybrid intelligence setup where machines and humans can collaborate. We show that two agents collaborating with each other results in better performance than one agent acting alone. We have open-sourced our code and models at https://github.com/tae898/explicit-memory.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Feb 02, 2022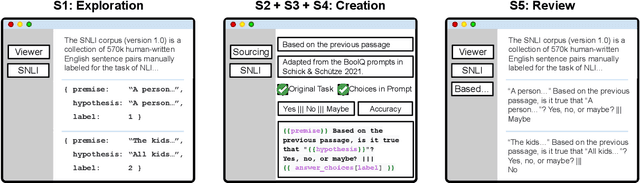
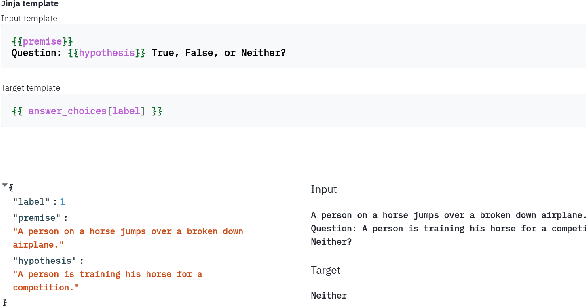

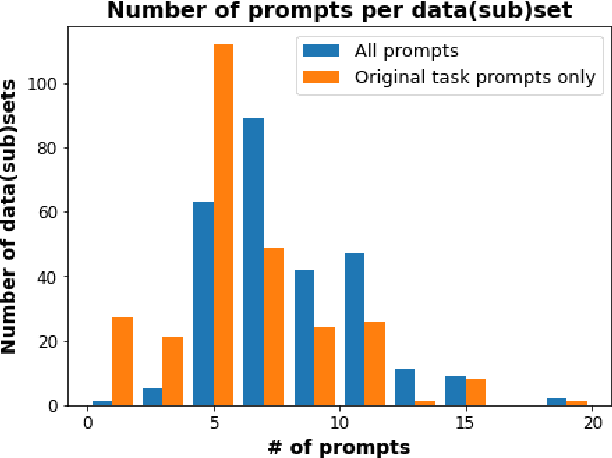
PromptSource is a system for creating, sharing, and using natural language prompts. Prompts are functions that map an example from a dataset to a natural language input and target output. Using prompts to train and query language models is an emerging area in NLP that requires new tools that let users develop and refine these prompts collaboratively. PromptSource addresses the emergent challenges in this new setting with (1) a templating language for defining data-linked prompts, (2) an interface that lets users quickly iterate on prompt development by observing outputs of their prompts on many examples, and (3) a community-driven set of guidelines for contributing new prompts to a common pool. Over 2,000 prompts for roughly 170 datasets are already available in PromptSource. PromptSource is available at https://github.com/bigscience-workshop/promptsource.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021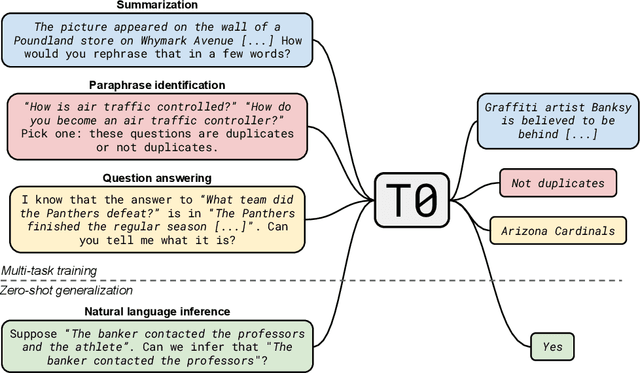

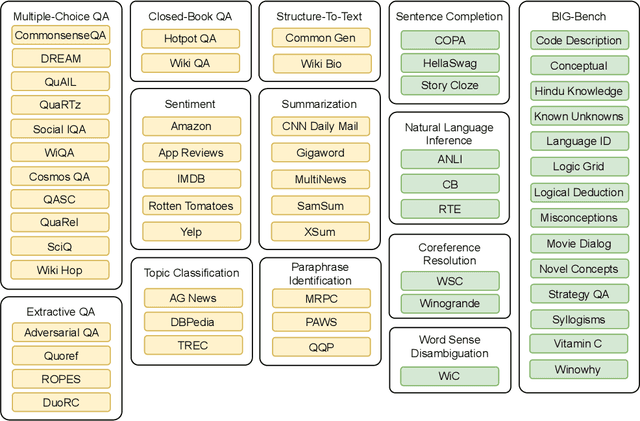

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa
Aug 26, 2021

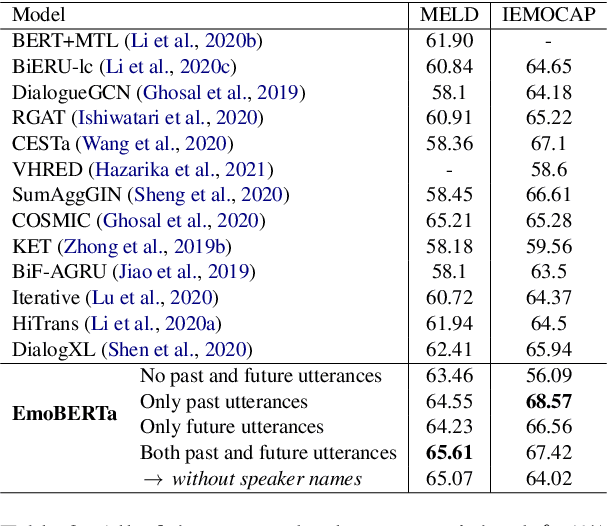

We present EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa, a simple yet expressive scheme of solving the ERC (emotion recognition in conversation) task. By simply prepending speaker names to utterances and inserting separation tokens between the utterances in a dialogue, EmoBERTa can learn intra- and inter- speaker states and context to predict the emotion of a current speaker, in an end-to-end manner. Our experiments show that we reach a new state of the art on the two popular ERC datasets using a basic and straight-forward approach. We've open sourced our code and models at https://github.com/tae898/erc.
Generalizing MLPs With Dropouts, Batch Normalization, and Skip Connections
Aug 22, 2021


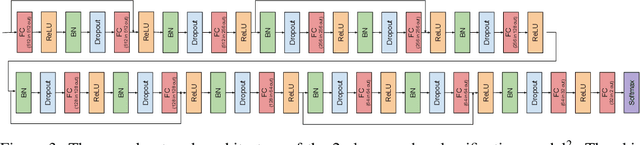
A multilayer perceptron (MLP) is typically made of multiple fully connected layers with nonlinear activation functions. There have been several approaches to make them better (e.g. faster convergence, better convergence limit, etc.). But the researches lack structured ways to test them. We test different MLP architectures by carrying out the experiments on the age and gender datasets. We empirically show that by whitening inputs before every linear layer and adding skip connections, our proposed MLP architecture can result in better performance. Since the whitening process includes dropouts, it can also be used to approximate Bayesian inference. We have open sourced our code, and released models and docker images at https://github.com/tae898/age-gender/