 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving adaptability to new environments and removing catastrophic forgetting in Reinforcement Learning by using an eco-system of agents
Paper and Code
Apr 13, 2022

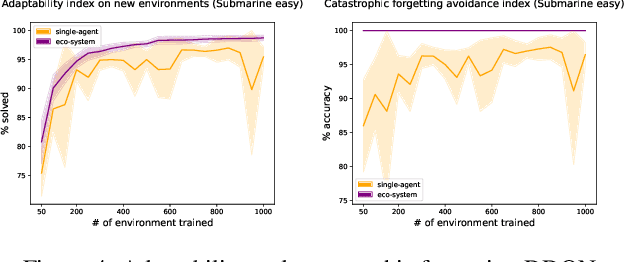
Adapting a Reinforcement Learning (RL) agent to an unseen environment is a difficult task due to typical over-fitting on the training environment. RL agents are often capable of solving environments very close to the trained environment, but when environments become substantially different, their performance quickly drops. When agents are retrained on new environments, a second issue arises: there is a risk of catastrophic forgetting, where the performance on previously seen environments is seriously hampered. This paper proposes a novel approach that exploits an ecosystem of agents to address both concerns. Hereby, the (limited) adaptive power of individual agents is harvested to build a highly adaptive ecosystem. This allows to transfer part of the workload from learning to inference. An evaluation of the approach on two distinct distributions of environments shows that our approach outperforms state-of-the-art techniques in terms of adaptability/generalization as well as avoids catastrophic forgetting.