 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisher-aware Quantization for DETR Detectors with Critical-category Objectives
Jul 03, 2024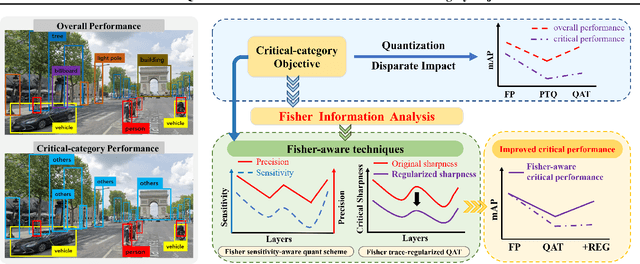


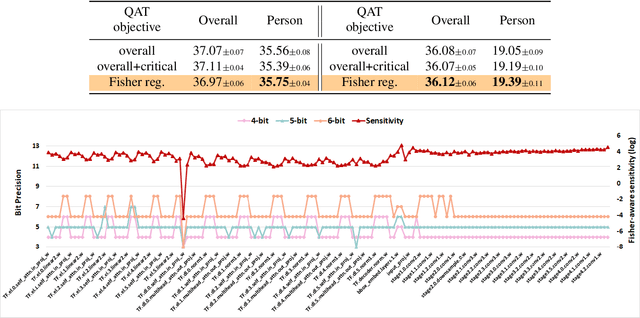
The impact of quantization on the overall performance of deep learning models is a well-studied problem. However, understanding and mitigating its effects on a more fine-grained level is still lacking, especially for harder tasks such as object detection with both classification and regression objectives. This work defines the performance for a subset of task-critical categories, i.e. the critical-category performance, as a crucial yet largely overlooked fine-grained objective for detection tasks. We analyze the impact of quantization at the category-level granularity, and propose methods to improve performance for the critical categories. Specifically, we find that certain critical categories have a higher sensitivity to quantization, and are prone to overfitting after quantization-aware training (QAT). To explain this, we provide theoretical and empirical links between their performance gaps and the corresponding loss landscapes with the Fisher information framework. Using this evidence, we apply a Fisher-aware mixed-precision quantization scheme, and a Fisher-trace regularization for the QAT on the critical-category loss landscape. The proposed methods improve critical-category metrics of the quantized transformer-based DETR detectors. They are even more significant in case of larger models and higher number of classes where the overfitting becomes more severe. For example, our methods lead to 10.4% and 14.5% mAP gains for, correspondingly, 4-bit DETR-R50 and Deformable DETR on the most impacted critical classes in the COCO Panoptic dataset.
Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting
Dec 14, 2023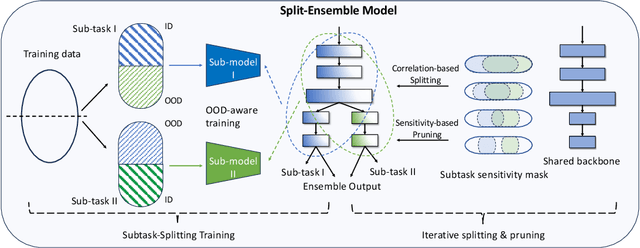
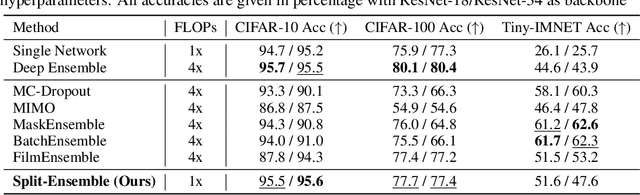
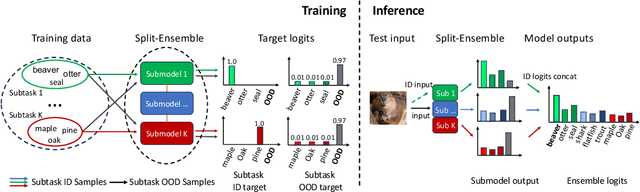
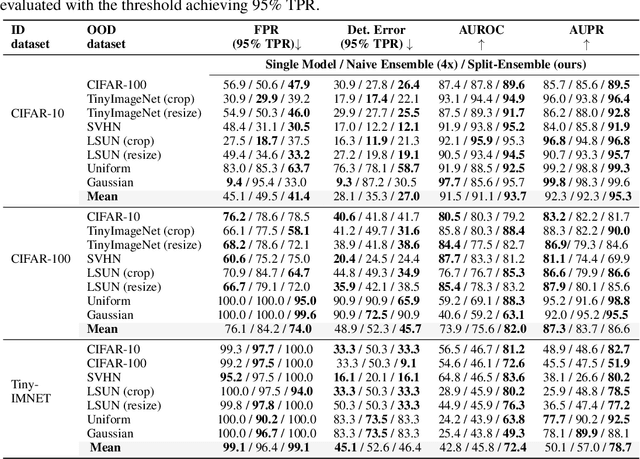
Uncertainty estimation is crucial for machine learning models to detect out-of-distribution (OOD) inputs. However, the conventional discriminative deep learning classifiers produce uncalibrated closed-set predictions for OOD data. A more robust classifiers with the uncertainty estimation typically require a potentially unavailable OOD dataset for outlier exposure training, or a considerable amount of additional memory and compute to build ensemble models. In this work, we improve on uncertainty estimation without extra OOD data or additional inference costs using an alternative Split-Ensemble method. Specifically, we propose a novel subtask-splitting ensemble training objective, where a common multiclass classification task is split into several complementary subtasks. Then, each subtask's training data can be considered as OOD to the other subtasks. Diverse submodels can therefore be trained on each subtask with OOD-aware objectives. The subtask-splitting objective enables us to share low-level features across submodels to avoid parameter and computational overheads. In particular, we build a tree-like Split-Ensemble architecture by performing iterative splitting and pruning from a shared backbone model, where each branch serves as a submodel corresponding to a subtask. This leads to improved accuracy and uncertainty estimation across submodels under a fixed ensemble computation budget. Empirical study with ResNet-18 backbone shows Split-Ensemble, without additional computation cost, improves accuracy over a single model by 0.8%, 1.8%, and 25.5% on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively. OOD detection for the same backbone and in-distribution datasets surpasses a single model baseline by, correspondingly, 2.2%, 8.1%, and 29.6% mean AUROC. Codes will be publicly available at https://antonioo-c.github.io/projects/split-ensemble