 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Textures in Zero-shot Understanding of Fine-Grained Domains
Mar 22, 2022

Textures can be used to describe the appearance of objects in a wide range of fine-grained domains. Textures are localized and one can often refer to their properties in a manner that is independent of the object identity. Moreover, there is a rich vocabulary to describe textures corresponding to properties such as their color, pattern, structure, periodicity, stochasticity, and others. Motivated by this, we study the effectiveness of large-scale language and vision models (e.g., CLIP) at recognizing texture attributes in natural images. We first conduct a systematic study of CLIP on texture datasets where we find that it has good coverage for a wide range of texture terms. CLIP can also handle compositional phrases that consist of color and pattern terms (e.g., red dots or yellow stripes). We then show how these attributes allow for zero-shot fine-grained categorization on existing datasets.
PhraseCut: Language-based Image Segmentation in the Wild
Aug 03, 2020



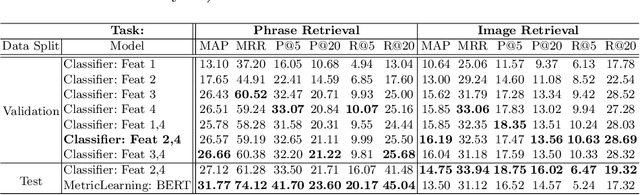
We consider the problem of segmenting image regions given a natural language phrase, and study it on a novel dataset of 77,262 images and 345,486 phrase-region pairs. Our dataset is collected on top of the Visual Genome dataset and uses the existing annotations to generate a challenging set of referring phrases for which the corresponding regions are manually annotated. Phrases in our dataset correspond to multiple regions and describe a large number of object and stuff categories as well as their attributes such as color, shape, parts, and relationships with other entities in the image. Our experiments show that the scale and diversity of concepts in our dataset poses significant challenges to the existing state-of-the-art. We systematically handle the long-tail nature of these concepts and present a modular approach to combine category, attribute, and relationship cues that outperforms existing approaches.
Describing Textures using Natural Language
Aug 03, 2020
Textures in natural images can be characterized by color, shape, periodicity of elements within them, and other attributes that can be described using natural language. In this paper, we study the problem of describing visual attributes of texture on a novel dataset containing rich descriptions of textures, and conduct a systematic study of current generative and discriminative models for grounding language to images on this dataset. We find that while these models capture some properties of texture, they fail to capture several compositional properties, such as the colors of dots. We provide critical analysis of existing models by generating synthetic but realistic textures with different descriptions. Our dataset also allows us to train interpretable models and generate language-based explanations of what discriminative features are learned by deep networks for fine-grained categorization where texture plays a key role. We present visualizations of several fine-grained domains and show that texture attributes learned on our dataset offer improvements over expert-designed attributes on the Caltech-UCSD Birds dataset.
Visualizing and Describing Fine-grained Categories as Textures
Jul 02, 2019


We analyze how categories from recent FGVC challenges can be described by their textural content. The motivation is that subtle differences between species of birds or butterflies can often be described in terms of the texture associated with them and that several top-performing networks are inspired by texture-based representations. These representations are characterized by orderless pooling of second-order filter activations such as in bilinear CNNs and the winner of the iNaturalist 2018 challenge. Concretely, for each category we (i) visualize the "maximal images" by obtaining inputs x that maximize the probability of the particular class according to a texture-based deep network, and (ii) automatically describe the maximal images using a set of texture attributes. The models for texture captioning were trained on our ongoing efforts on collecting a dataset of describable textures building on the DTD dataset. These visualizations indicate what aspects of the texture is most discriminative for each category while the descriptions provide a language-based explanation of the same.
Reasoning about Fine-grained Attribute Phrases using Reference Games
Aug 29, 2017
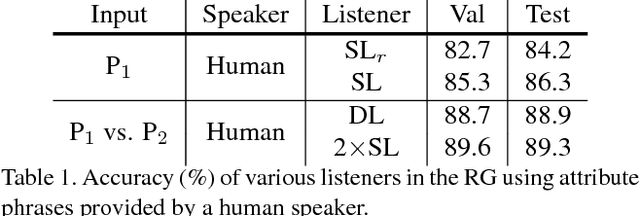


We present a framework for learning to describe fine-grained visual differences between instances using attribute phrases. Attribute phrases capture distinguishing aspects of an object (e.g., "propeller on the nose" or "door near the wing" for airplanes) in a compositional manner. Instances within a category can be described by a set of these phrases and collectively they span the space of semantic attributes for a category. We collect a large dataset of such phrases by asking annotators to describe several visual differences between a pair of instances within a category. We then learn to describe and ground these phrases to images in the context of a *reference game* between a speaker and a listener. The goal of a speaker is to describe attributes of an image that allows the listener to correctly identify it within a pair. Data collected in a pairwise manner improves the ability of the speaker to generate, and the ability of the listener to interpret visual descriptions. Moreover, due to the compositionality of attribute phrases, the trained listeners can interpret descriptions not seen during training for image retrieval, and the speakers can generate attribute-based explanations for differences between previously unseen categories. We also show that embedding an image into the semantic space of attribute phrases derived from listeners offers 20% improvement in accuracy over existing attribute-based representations on the FGVC-aircraft dataset.