 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribing Textures using Natural Language
Paper and Code
Aug 03, 2020
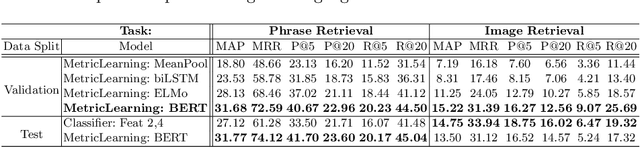
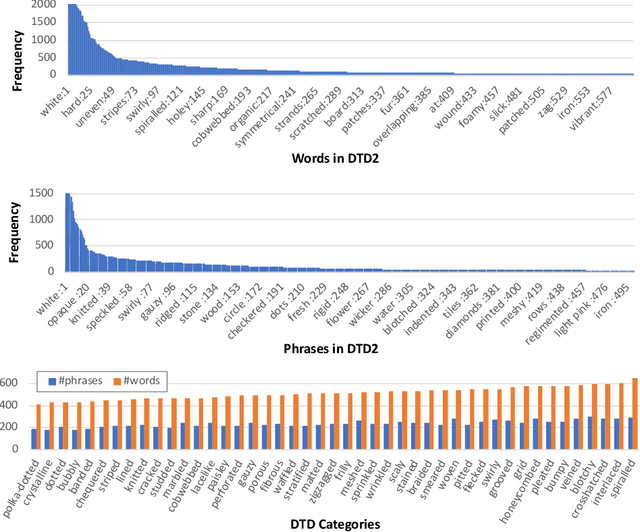
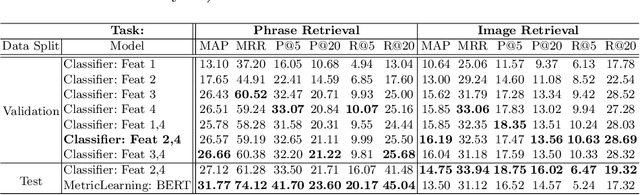
Textures in natural images can be characterized by color, shape, periodicity of elements within them, and other attributes that can be described using natural language. In this paper, we study the problem of describing visual attributes of texture on a novel dataset containing rich descriptions of textures, and conduct a systematic study of current generative and discriminative models for grounding language to images on this dataset. We find that while these models capture some properties of texture, they fail to capture several compositional properties, such as the colors of dots. We provide critical analysis of existing models by generating synthetic but realistic textures with different descriptions. Our dataset also allows us to train interpretable models and generate language-based explanations of what discriminative features are learned by deep networks for fine-grained categorization where texture plays a key role. We present visualizations of several fine-grained domains and show that texture attributes learned on our dataset offer improvements over expert-designed attributes on the Caltech-UCSD Birds dataset.