 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToMoE: Converting Dense Large Language Models to Mixture-of-Experts through Dynamic Structural Pruning
Jan 25, 2025Large Language Models (LLMs) have demonstrated remarkable abilities in tackling a wide range of complex tasks. However, their huge computational and memory costs raise significant challenges in deploying these models on resource-constrained devices or efficiently serving them. Prior approaches have attempted to alleviate these problems by permanently removing less important model structures, yet these methods often result in substantial performance degradation due to the permanent deletion of model parameters. In this work, we tried to mitigate this issue by reducing the number of active parameters without permanently removing them. Specifically, we introduce a differentiable dynamic pruning method that pushes dense models to maintain a fixed number of active parameters by converting their MLP layers into a Mixture of Experts (MoE) architecture. Our method, even without fine-tuning, consistently outperforms previous structural pruning techniques across diverse model families, including Phi-2, LLaMA-2, LLaMA-3, and Qwen-2.5.
Not All Prompts Are Made Equal: Prompt-based Pruning of Text-to-Image Diffusion Models
Jun 17, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive image generation capabilities. Still, their computational intensity prohibits resource-constrained organizations from deploying T2I models after fine-tuning them on their internal target data. While pruning techniques offer a potential solution to reduce the computational burden of T2I models, static pruning methods use the same pruned model for all input prompts, overlooking the varying capacity requirements of different prompts. Dynamic pruning addresses this issue by utilizing a separate sub-network for each prompt, but it prevents batch parallelism on GPUs. To overcome these limitations, we introduce Adaptive Prompt-Tailored Pruning (APTP), a novel prompt-based pruning method designed for T2I diffusion models. Central to our approach is a prompt router model, which learns to determine the required capacity for an input text prompt and routes it to an architecture code, given a total desired compute budget for prompts. Each architecture code represents a specialized model tailored to the prompts assigned to it, and the number of codes is a hyperparameter. We train the prompt router and architecture codes using contrastive learning, ensuring that similar prompts are mapped to nearby codes. Further, we employ optimal transport to prevent the codes from collapsing into a single one. We demonstrate APTP's effectiveness by pruning Stable Diffusion (SD) V2.1 using CC3M and COCO as target datasets. APTP outperforms the single-model pruning baselines in terms of FID, CLIP, and CMMD scores. Our analysis of the clusters learned by APTP reveals they are semantically meaningful. We also show that APTP can automatically discover previously empirically found challenging prompts for SD, e.g., prompts for generating text images, assigning them to higher capacity codes.
From Pixels to Prose: A Large Dataset of Dense Image Captions
Jun 14, 2024

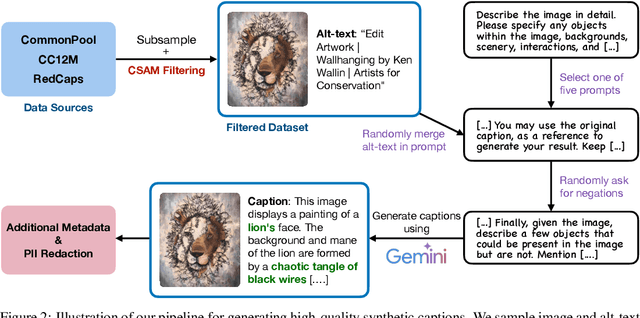
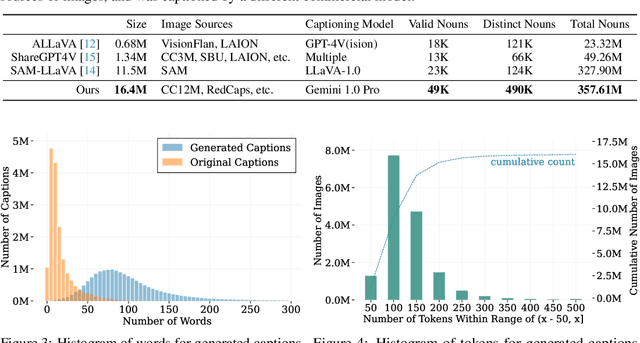
Training large vision-language models requires extensive, high-quality image-text pairs. Existing web-scraped datasets, however, are noisy and lack detailed image descriptions. To bridge this gap, we introduce PixelProse, a comprehensive dataset of over 16M (million) synthetically generated captions, leveraging cutting-edge vision-language models for detailed and accurate descriptions. To ensure data integrity, we rigorously analyze our dataset for problematic content, including child sexual abuse material (CSAM), personally identifiable information (PII), and toxicity. We also provide valuable metadata such as watermark presence and aesthetic scores, aiding in further dataset filtering. We hope PixelProse will be a valuable resource for future vision-language research. PixelProse is available at https://huggingface.co/datasets/tomg-group-umd/pixelprose
Jointly Training and Pruning CNNs via Learnable Agent Guidance and Alignment
Mar 28, 2024



Structural model pruning is a prominent approach used for reducing the computational cost of Convolutional Neural Networks (CNNs) before their deployment on resource-constrained devices. Yet, the majority of proposed ideas require a pretrained model before pruning, which is costly to secure. In this paper, we propose a novel structural pruning approach to jointly learn the weights and structurally prune architectures of CNN models. The core element of our method is a Reinforcement Learning (RL) agent whose actions determine the pruning ratios of the CNN model's layers, and the resulting model's accuracy serves as its reward. We conduct the joint training and pruning by iteratively training the model's weights and the agent's policy, and we regularize the model's weights to align with the selected structure by the agent. The evolving model's weights result in a dynamic reward function for the agent, which prevents using prominent episodic RL methods with stationary environment assumption for our purpose. We address this challenge by designing a mechanism to model the complex changing dynamics of the reward function and provide a representation of it to the RL agent. To do so, we take a learnable embedding for each training epoch and employ a recurrent model to calculate a representation of the changing environment. We train the recurrent model and embeddings using a decoder model to reconstruct observed rewards. Such a design empowers our agent to effectively leverage episodic observations along with the environment representations to learn a proper policy to determine performant sub-networks of the CNN model. Our extensive experiments on CIFAR-10 and ImageNet using ResNets and MobileNets demonstrate the effectiveness of our method.
Compressing Image-to-Image Translation GANs Using Local Density Structures on Their Learned Manifold
Dec 22, 2023



Generative Adversarial Networks (GANs) have shown remarkable success in modeling complex data distributions for image-to-image translation. Still, their high computational demands prohibit their deployment in practical scenarios like edge devices. Existing GAN compression methods mainly rely on knowledge distillation or convolutional classifiers' pruning techniques. Thus, they neglect the critical characteristic of GANs: their local density structure over their learned manifold. Accordingly, we approach GAN compression from a new perspective by explicitly encouraging the pruned model to preserve the density structure of the original parameter-heavy model on its learned manifold. We facilitate this objective for the pruned model by partitioning the learned manifold of the original generator into local neighborhoods around its generated samples. Then, we propose a novel pruning objective to regularize the pruned model to preserve the local density structure over each neighborhood, resembling the kernel density estimation method. Also, we develop a collaborative pruning scheme in which the discriminator and generator are pruned by two pruning agents. We design the agents to capture interactions between the generator and discriminator by exchanging their peer's feedback when determining corresponding models' architectures. Thanks to such a design, our pruning method can efficiently find performant sub-networks and can maintain the balance between the generator and discriminator more effectively compared to baselines during pruning, thereby showing more stable pruning dynamics. Our experiments on image translation GAN models, Pix2Pix and CycleGAN, with various benchmark datasets and architectures demonstrate our method's effectiveness.
Interpretations Steered Network Pruning via Amortized Inferred Saliency Maps
Sep 07, 2022



Convolutional Neural Networks (CNNs) compression is crucial to deploying these models in edge devices with limited resources. Existing channel pruning algorithms for CNNs have achieved plenty of success on complex models. They approach the pruning problem from various perspectives and use different metrics to guide the pruning process. However, these metrics mainly focus on the model's `outputs' or `weights' and neglect its `interpretations' information. To fill in this gap, we propose to address the channel pruning problem from a novel perspective by leveraging the interpretations of a model to steer the pruning process, thereby utilizing information from both inputs and outputs of the model. However, existing interpretation methods cannot get deployed to achieve our goal as either they are inefficient for pruning or may predict non-coherent explanations. We tackle this challenge by introducing a selector model that predicts real-time smooth saliency masks for pruned models. We parameterize the distribution of explanatory masks by Radial Basis Function (RBF)-like functions to incorporate geometric prior of natural images in our selector model's inductive bias. Thus, we can obtain compact representations of explanations to reduce the computational costs of our pruning method. We leverage our selector model to steer the network pruning by maximizing the similarity of explanatory representations for the pruned and original models. Extensive experiments on CIFAR-10 and ImageNet benchmark datasets demonstrate the efficacy of our proposed method. Our implementations are available at \url{https://github.com/Alii-Ganjj/InterpretationsSteeredPruning}