 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
ToMoE: Converting Dense Large Language Models to Mixture-of-Experts through Dynamic Structural Pruning
Jan 25, 2025Large Language Models (LLMs) have demonstrated remarkable abilities in tackling a wide range of complex tasks. However, their huge computational and memory costs raise significant challenges in deploying these models on resource-constrained devices or efficiently serving them. Prior approaches have attempted to alleviate these problems by permanently removing less important model structures, yet these methods often result in substantial performance degradation due to the permanent deletion of model parameters. In this work, we tried to mitigate this issue by reducing the number of active parameters without permanently removing them. Specifically, we introduce a differentiable dynamic pruning method that pushes dense models to maintain a fixed number of active parameters by converting their MLP layers into a Mixture of Experts (MoE) architecture. Our method, even without fine-tuning, consistently outperforms previous structural pruning techniques across diverse model families, including Phi-2, LLaMA-2, LLaMA-3, and Qwen-2.5.
Calculating the Midsagittal Plane for Symmetrical Bilateral Shapes: Applications to Clinical Facial Surgical Planning
Mar 11, 2018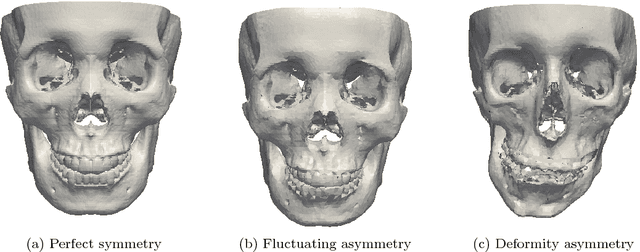

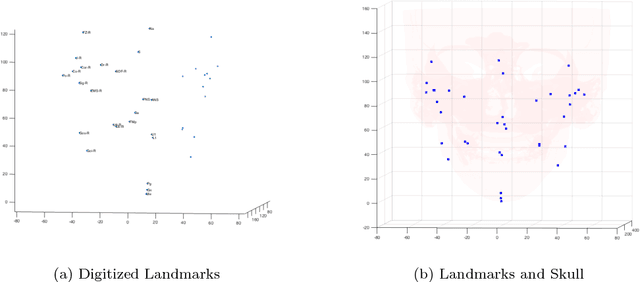
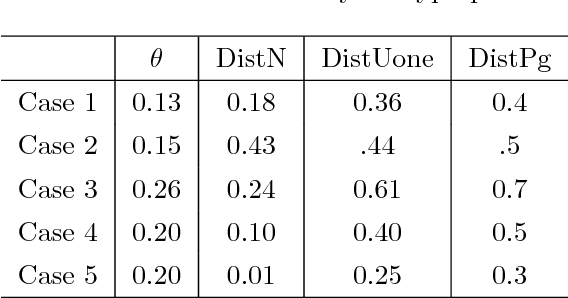
It is difficult to estimate the midsagittal plane of human subjects with craniomaxillofacial (CMF) deformities. We have developed a LAndmark GEometric Routine (LAGER), which automatically estimates a midsagittal plane for such subjects. The LAGER algorithm was based on the assumption that the optimal midsagittal plane of a patient with a deformity is the premorbid midsagittal plane of the patient (i.e. hypothetically normal without deformity). The LAGER algorithm consists of three steps. The first step quantifies the asymmetry of the landmarks using a Euclidean distance matrix analysis and ranks the landmarks according to their degree of asymmetry. The second step uses a recursive algorithm to drop outlier landmarks. The third step inputs the remaining landmarks into an optimization algorithm to determine an optimal midsaggital plane. We validate LAGER on 20 synthetic models mimicking the skulls of real patients with CMF deformities. The results indicated that all the LAGER algorithm-generated midsagittal planes met clinical criteria. Thus it can be used clinically to determine the midsagittal plane for patients with CMF deformities.