Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal or Fake? Learning to Discriminate Machine from Human Generated Text
Paper and Code
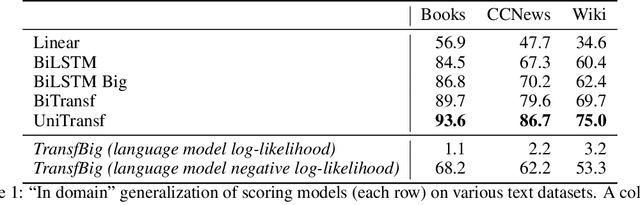
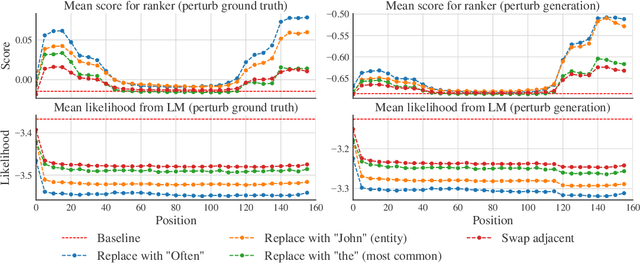
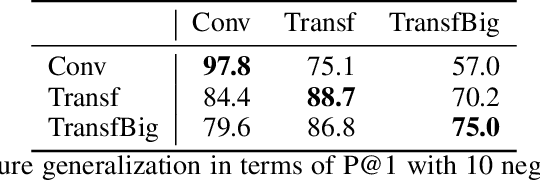
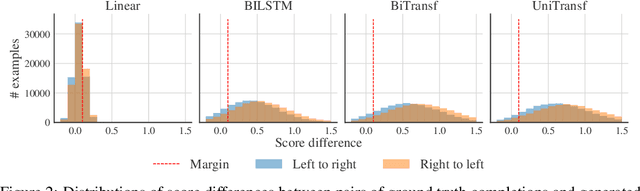
Recent advances in generative modeling of text have demonstrated remarkable improvements in terms of fluency and coherency. In this work we investigate to which extent a machine can discriminate real from machine generated text. This is important in itself for automatic detection of computer generated stories, but can also serve as a tool for further improving text generation. We show that learning a dedicated scoring function to discriminate between real and fake text achieves higher precision than employing the likelihood of a generative model. The scoring functions generalize to other generators than those used for training as long as these generators have comparable model complexity and are trained on similar datasets.
View paper on