 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Sparsity for Large Language Models Fine-Tuning
Paper and Code
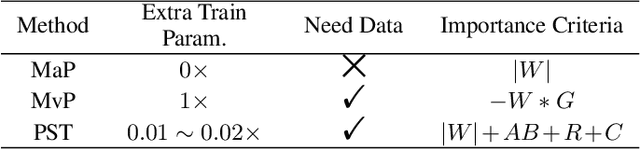
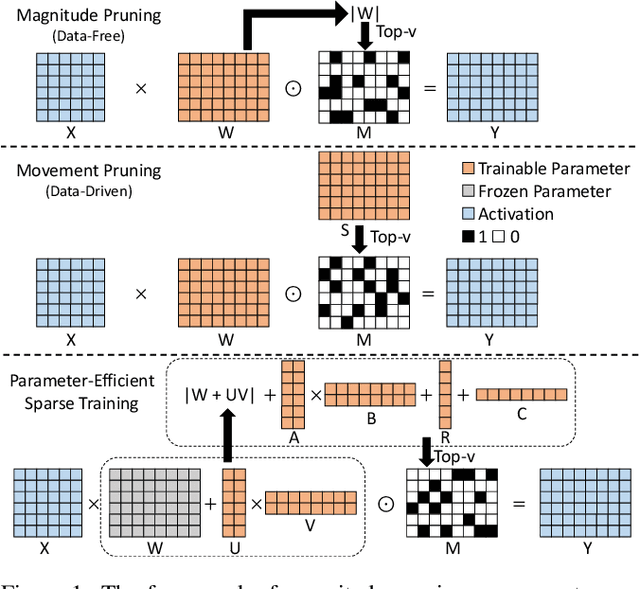
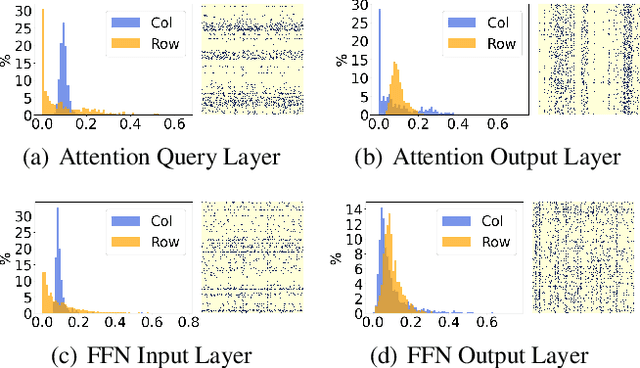
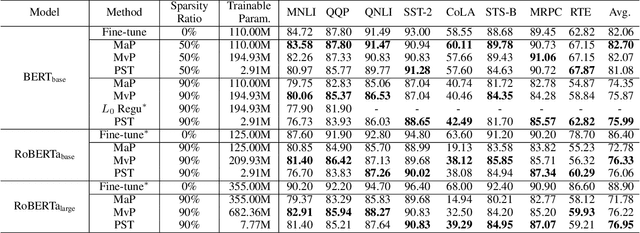
With the dramatically increased number of parameters in language models, sparsity methods have received ever-increasing research focus to compress and accelerate the models. While most research focuses on how to accurately retain appropriate weights while maintaining the performance of the compressed model, there are challenges in the computational overhead and memory footprint of sparse training when compressing large-scale language models. To address this problem, we propose a Parameter-efficient Sparse Training (PST) method to reduce the number of trainable parameters during sparse-aware training in downstream tasks. Specifically, we first combine the data-free and data-driven criteria to efficiently and accurately measure the importance of weights. Then we investigate the intrinsic redundancy of data-driven weight importance and derive two obvious characteristics i.e., low-rankness and structuredness. Based on that, two groups of small matrices are introduced to compute the data-driven importance of weights, instead of using the original large importance score matrix, which therefore makes the sparse training resource-efficient and parameter-efficient. Experiments with diverse networks (i.e., BERT, RoBERTa and GPT-2) on dozens of datasets demonstrate PST performs on par or better than previous sparsity methods, despite only training a small number of parameters. For instance, compared with previous sparsity methods, our PST only requires 1.5% trainable parameters to achieve comparable performance on BERT.