 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open Domain Text-Driven Synthesis of Multi-Person Motions
May 28, 2024This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
OmniMotionGPT: Animal Motion Generation with Limited Data
Nov 30, 2023



Our paper aims to generate diverse and realistic animal motion sequences from textual descriptions, without a large-scale animal text-motion dataset. While the task of text-driven human motion synthesis is already extensively studied and benchmarked, it remains challenging to transfer this success to other skeleton structures with limited data. In this work, we design a model architecture that imitates Generative Pretraining Transformer (GPT), utilizing prior knowledge learned from human data to the animal domain. We jointly train motion autoencoders for both animal and human motions and at the same time optimize through the similarity scores among human motion encoding, animal motion encoding, and text CLIP embedding. Presenting the first solution to this problem, we are able to generate animal motions with high diversity and fidelity, quantitatively and qualitatively outperforming the results of training human motion generation baselines on animal data. Additionally, we introduce AnimalML3D, the first text-animal motion dataset with 1240 animation sequences spanning 36 different animal identities. We hope this dataset would mediate the data scarcity problem in text-driven animal motion generation, providing a new playground for the research community.
Learning Probabilistic Models from Generator Latent Spaces with Hat EBM
Oct 29, 2022



This work proposes a method for using any generator network as the foundation of an Energy-Based Model (EBM). Our formulation posits that observed images are the sum of unobserved latent variables passed through the generator network and a residual random variable that spans the gap between the generator output and the image manifold. One can then define an EBM that includes the generator as part of its forward pass, which we call the Hat EBM. The model can be trained without inferring the latent variables of the observed data or calculating the generator Jacobian determinant. This enables explicit probabilistic modeling of the output distribution of any type of generator network. Experiments show strong performance of the proposed method on (1) unconditional ImageNet synthesis at 128x128 resolution, (2) refining the output of existing generators, and (3) learning EBMs that incorporate non-probabilistic generators. Code and pretrained models to reproduce our results are available at https://github.com/point0bar1/hat-ebm.
EBM Life Cycle: MCMC Strategies for Synthesis, Defense, and Density Modeling
May 24, 2022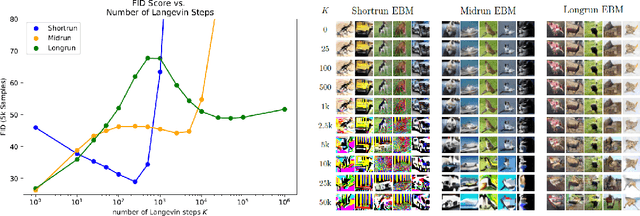

This work presents strategies to learn an Energy-Based Model (EBM) according to the desired length of its MCMC sampling trajectories. MCMC trajectories of different lengths correspond to models with different purposes. Our experiments cover three different trajectory magnitudes and learning outcomes: 1) shortrun sampling for image generation; 2) midrun sampling for classifier-agnostic adversarial defense; and 3) longrun sampling for principled modeling of image probability densities. To achieve these outcomes, we introduce three novel methods of MCMC initialization for negative samples used in Maximum Likelihood (ML) learning. With standard network architectures and an unaltered ML objective, our MCMC initialization methods alone enable significant performance gains across the three applications that we investigate. Our results include state-of-the-art FID scores for unnormalized image densities on the CIFAR-10 and ImageNet datasets; state-of-the-art adversarial defense on CIFAR-10 among purification methods and the first EBM defense on ImageNet; and scalable techniques for learning valid probability densities. Code for this project can be found at https://github.com/point0bar1/ebm-life-cycle.
Stochastic Security: Adversarial Defense Using Long-Run Dynamics of Energy-Based Models
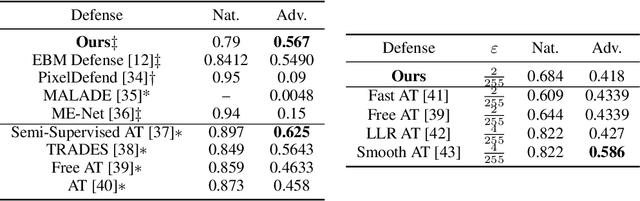
May 27, 2020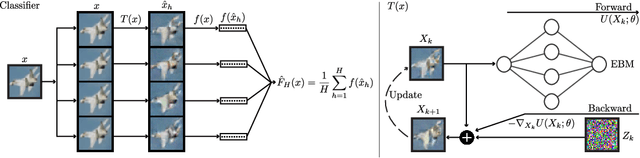
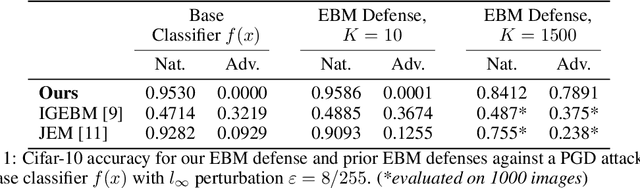


The vulnerability of deep networks to adversarial attacks is a central problem for deep learning from the perspective of both cognition and security. The current most successful defense method is to train a classifier using adversarial images created during learning. Another defense approach involves transformation or purification of the original input to remove adversarial signals before the image is classified. We focus on defending naturally-trained classifiers using Markov Chain Monte Carlo (MCMC) sampling with an Energy-Based Model (EBM) for adversarial purification. In contrast to adversarial training, our approach is intended to secure pre-existing and highly vulnerable classifiers. The memoryless behavior of long-run MCMC sampling will eventually remove adversarial signals, while metastable behavior preserves consistent appearance of MCMC samples after many steps to allow accurate long-run prediction. Balancing these factors can lead to effective purification and robust classification. We evaluate adversarial defense with an EBM using the strongest known attacks against purification. Our contributions are 1) an improved method for training EBM's with realistic long-run MCMC samples, 2) an Expectation-Over-Transformation (EOT) defense that resolves theoretical ambiguities for stochastic defenses and from which the EOT attack naturally follows, and 3) state-of-the-art adversarial defense for naturally-trained classifiers and competitive defense compared to adversarially-trained classifiers on Cifar-10, SVHN, and Cifar-100. Code and pre-trained models are available at https://github.com/point0bar1/ebm-defense.
On Learning Non-Convergent Non-Persistent Short-Run MCMC Toward Energy-Based Model
May 27, 2019
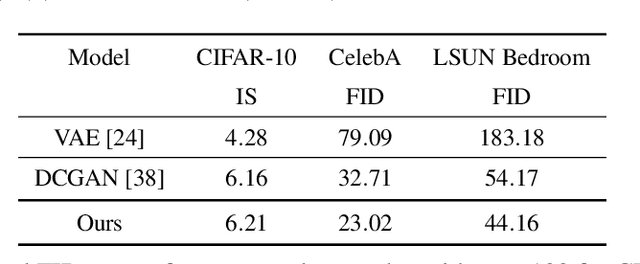

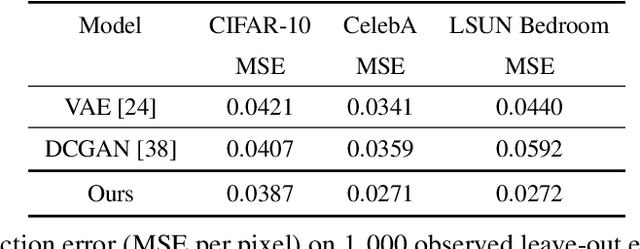
This paper studies a curious phenomenon in learning energy-based model (EBM) using MCMC. In each learning iteration, we generate synthesized examples by running a non-convergent, non-mixing, and non-persistent short-run MCMC toward the current model, always starting from the same initial distribution such as uniform noise distribution, and always running a fixed number of MCMC steps. After generating synthesized examples, we then update the model parameters according to the maximum likelihood learning gradient, as if the synthesized examples are fair samples from the current model. We treat this non-convergent short-run MCMC as a learned generator model or a flow model. We provide arguments for treating the learned non-convergent short-run MCMC as a valid model. We show that the learned short-run MCMC is capable of generating realistic images. More interestingly, unlike traditional EBM or MCMC, the learned short-run MCMC is capable of reconstructing observed images and interpolating between images, like generator or flow models. The code can be found in the Appendix.
On the Anatomy of MCMC-based Maximum Likelihood Learning of Energy-Based Models
Apr 11, 2019

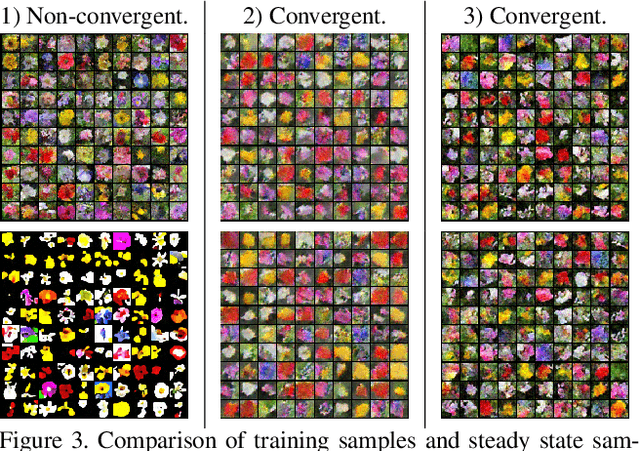
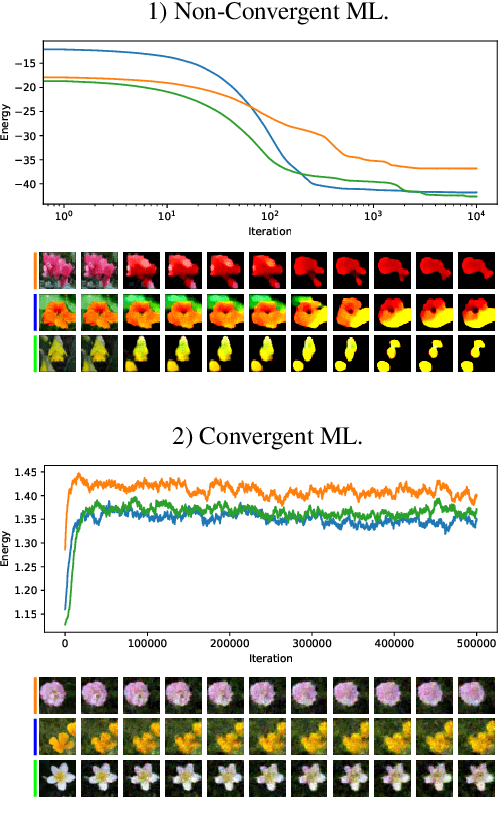
This study investigates the effects of Markov Chain Monte Carlo (MCMC) sampling in unsupervised Maximum Likelihood (ML) learning. Our attention is restricted to the family of unnormalized probability densities for which the negative log density (or energy function) is a ConvNet. In general, we find that many of the techniques used to stabilize training in previous studies can have the opposite effect. Stable ML learning with a ConvNet potential can be achieved with only a few hyper-parameters and no regularization. Using this minimal framework, we identify a variety of ML learning outcomes that depend on the implementation of MCMC sampling. On one hand, we show that it is easy to train an energy-based model which can sample realistic images with short-run Langevin. ML can be effective and stable even when MCMC samples have much higher energy than true steady-state samples throughout training. Based on this insight, we introduce an ML method with purely noise-initialized MCMC, high-quality short-run synthesis, and the same budget as ML with informative MCMC initialization such as CD or PCD. Unlike previous models, our model can obtain realistic high-diversity samples from a noise signal after training with no auxiliary networks. On the other hand, ConvNet potentials learned with highly non-convergent MCMC do not have a valid steady-state and cannot be considered approximate unnormalized densities of the training data because long-run MCMC samples differ greatly from observed images. We show that it is much harder to train a ConvNet potential to learn a steady-state over realistic images. To our knowledge, long-run MCMC samples of all previous models lose the realism of short-run samples. With correct tuning of Langevin noise, we train the first ConvNet potentials for which long-run and steady-state MCMC samples are realistic images.
Divergence Triangle for Joint Training of Generator Model, Energy-based Model, and Inference Model
Dec 28, 2018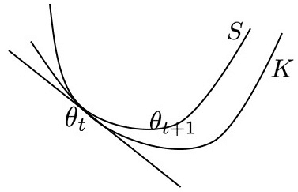


This paper proposes the divergence triangle as a framework for joint training of generator model, energy-based model and inference model. The divergence triangle is a compact and symmetric (anti-symmetric) objective function that seamlessly integrates variational learning, adversarial learning, wake-sleep algorithm, and contrastive divergence in a unified probabilistic formulation. This unification makes the processes of sampling, inference, energy evaluation readily available without the need for costly Markov chain Monte Carlo methods. Our experiments demonstrate that the divergence triangle is capable of learning (1) an energy-based model with well-formed energy landscape, (2) direct sampling in the form of a generator network, and (3) feed-forward inference that faithfully reconstructs observed as well as synthesized data. The divergence triangle is a robust training method that can learn from incomplete data.
Building a Telescope to Look Into High-Dimensional Image Spaces
Mar 02, 2018


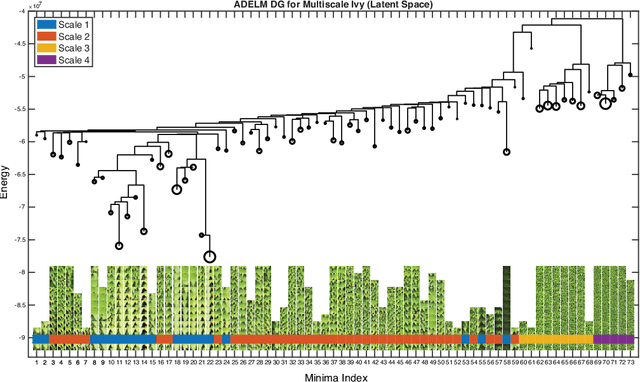
An image pattern can be represented by a probability distribution whose density is concentrated on different low-dimensional subspaces in the high-dimensional image space. Such probability densities have an astronomical number of local modes corresponding to typical pattern appearances. Related groups of modes can join to form macroscopic image basins that represent pattern concepts. Recent works use neural networks that capture high-order image statistics to learn Gibbs models capable of synthesizing realistic images of many patterns. However, characterizing a learned probability density to uncover the Hopfield memories of the model, encoded by the structure of the local modes, remains an open challenge. In this work, we present novel computational experiments that map and visualize the local mode structure of Gibbs densities. Efficient mapping requires identifying the global basins without enumerating the countless modes. Inspired by Grenander's jump-diffusion method, we propose a new MCMC tool called Attraction-Diffusion (AD) that can capture the macroscopic structure of highly non-convex densities by measuring metastability of local modes. AD involves altering the target density with a magnetization potential penalizing distance from a known mode and running an MCMC sample of the altered density to measure the stability of the initial chain state. Using a low-dimensional generator network to facilitate exploration, we map image spaces with up to 12,288 dimensions (64 $\times$ 64 pixels in RGB). Our work shows: (1) AD can efficiently map highly non-convex probability densities, (2) metastable regions of pattern probability densities contain coherent groups of images, and (3) the perceptibility of differences between training images influences the metastability of image basins.